【泡泡机器人】也来谈语义SLAM/语义地图

『本文来自高翔博士在知乎的回答总结整理』
SLAM发展到今天,好些人认为这已经是个Solved Problem了。然而实际去考察,你会发现这个同时『定位』与『建图』,在『定位』这端做了很多工作,但『建图』这端是明显缺乏的。按照理想中的情况,一个SLAM程序的流程应该是这样:
对陌生环境进行一次扫描,建立地图;
保存地图;
以后运行时,打开这张地图进行定位。
这基本上是SLAM的最终目标了。但是当你打开一个SLAM程序,你会发现我们只能做完第1步,往往是建完地图之后,程序退出,所有你建起来的特征点也好,稠密点云也好,surfel也好,tsdf也好,好看是好看,基本没法存下来当作地图来继续使用(顶多做个3D模型打印一下)。所以如果要问『SLAM现在做到什么程度』,我觉得大致上可以这样回答:
关于第1步,现在我们能做到比较好的实时追踪和建图。大部分研究集中在Tracking上面,不过这种方式在无闭环时必定有累计误差,我个人经验是在0.5%-1%这个数量级,也许个别方案在个别数据上看起来好一些,不过视觉肯定比激光要差一些,比仔细标定的轮速计也差一些,也比较容易受干扰,但好在是一个独立的系统,和别的能够互相补充。有回环可以消累积误差,前提是得回来,自动驾驶很多场景是车一直往前开,基本不回去。
关于第2步和第3步,有一些可能的解决方案,但是都不完善。相比来说,激光SLAM在地图这边相对统一,通常都是用2D网格和3D点云来做,与激光数据可以直接比较。视觉地图就没那么直接。很多研究并不奔着『地图复用』的目的去,通常是做完第1步之后就完全不管了,导致我们现在没有特别好的视觉地图可以用。
所以现阶段我们还能难说『视觉SLAM已经解决』这样的话,除非能够拿出一张可以随时定位的视觉地图。这部分的缺失,我认为是语义SLAM的一个很重要的动机。我们不妨想想,现在有哪些可能用来作为视觉地图的东西:
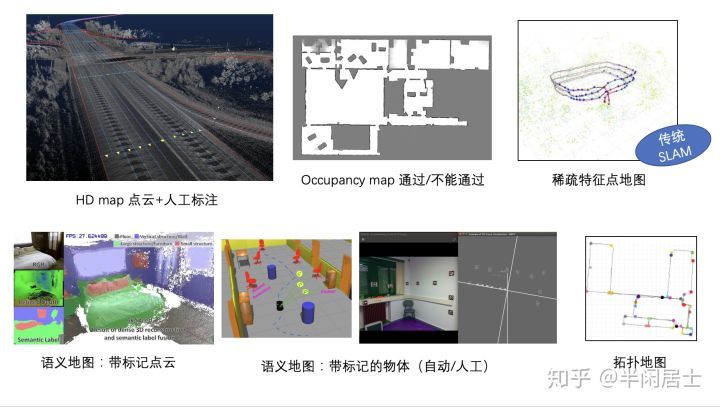
高精地图,点云加人工标。这个一般学校生产不出来,只有公司里有;
Grid map/Occupancy map,适合激光。有RGB-D的时候可以用,纯视觉困难;
特征点地图,现在SLAM里主要形式,类似ORB-SLAM2的地图,容易受光照和场景影响。
点云/带标记的点云,很难用,可能有部分带半稠密重建的方法可以和点云地图做ICP。
物体地图,以物体实例作为路标的地图。
拓扑地图,以路径点作为节点的拓扑图,可以端到端地训练图像到路径点的映射。
所以现在看来室内比较有希望的是后面几种,自动驾驶主要是高精地图。
什么是语义SLAM?
语义SLAM的概念很模糊。你会找到许多带着『Semantic』字眼,实际上完全不在说同一件事情的论文。比如从图像到Pose端到端的VO、从分割结果建标记点云、场景识别、CNN提特征、CNN做回环、带语义标记误差的BA,等等,都可以叫语义SLAM。
但是从实用层面考虑,我觉得最关键的一点是:
用神经网络帮助SLAM提路标
提路标这件事实际上是传统SLAM非常不擅长的事情。我们用角点和边缘,是因为现在只有角点和边缘可用。如果现在有个网络,对任意一张图片都能正确找到图片里的路标,一一对应,非常鲁棒,那么后续的SLAM就是件很简单的事情。比如现在人脸关键点能够做的非常准、非常鲁棒,对各种光照下的人脸我们都能找到那几十个点。

如果我们能在道路场景或室内场景也能做到这种程度,那SLAM就完全不一样。然而现在似乎并没有这种做法,至少还没流行开来。
那么就只能退而求其次,用现有的检测和分割来帮忙提路标。如果已经知道图像中某个物体属于一个既定的类别,然后再提角点,就会比针对全图提角点要好很多。当然,如果能直接提到点,那肯定是提点更好用,检测和分割都需要一些额外的后续处理。
举一些上面谈到的地图例子。
带标记的点云是研究最多的,从很早之前就有。它的思路是把分割的结果往RGBD点云里投,然后做一个融合,RGBD+室内的场景多一些,室外也有一部分。18年比如ETH有把Mask RCNN结果投到3D中进行Instance推断然后建图的,可以达到非常细致的结果。
再早一点比如牛津的Semantic Fusion,算是比较经典的工作:
自动驾驶里也有这种类型的高精地图,举例比如说Civil maps的演示视频,点云中有标记车道线和地面箭头。后面也有带物体instance的地图:
单纯的给点云上标记的事情其实并没有太多用途。给激光用,激光ICP通常不考虑标记信息;给视觉用,视觉也没法直接和点云去匹配。所以这种五颜六色的点云来说,物体级别的地图会更加有用:

这种图的好处在于物体实际充当了SLAM中的路标的功能,它们的提取和匹配会比传统的角点更加鲁棒。你可以期待不同天气下都能提到同一个红绿灯,但你不能期待对于各种天气下同样的建筑物能提到同样的角点。
细分下去,这种基于物体的地图也可以有不同做法。比如室内环境,你可以准备一个3D模型库,只检测模型库内的物体。这种做法在早期的SLAM++和现在的一些论文中都能看到,比如这个就是存了椅子模型的:

观看本视频(video4)请到文末获取链接
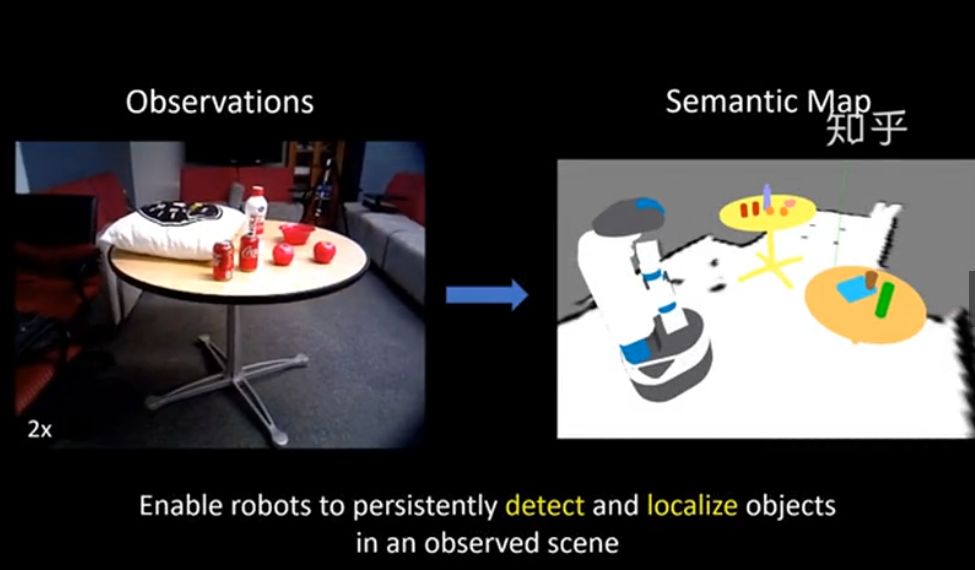
这个模型更多一些,除了椅子还有很多小物体,能用地图信息修正检测结果,并且他们用的是检测而不是分割:
观看本视频(video5)请到文末获取链接
所以『把物体建出来当地图路标』其实是一个不错的思路。剩下的就是看物体有多少类,能不能支持到大多数常见的物体。就自动驾驶来说,有了车道线,你至少就能知道自己在第几根车道线之间。有了车道线地图,就能知道自己在地图上哪两根车道线之间。类别再丰富一些,能用来定位的东西就更多,覆盖范围也就更宽。
这个算是语义SLAM和传统SLAM中最不同的地方了。
以上视频来自YouTube,论文题目在视频开头处,读者可自行搜索
video4:
https://v.qq.com/x/page/u0848a98m7f.html?pcsharecode=CdrLQDmn&sf=uri
video5:
https://v.qq.com/x/page/p0848kefne5.html?pcsharecode=GsG7cVSL&sf=uri




