重磅 | Facebook提出全新CNN机器翻译:准确度超越谷歌而且还快九倍(已开源)
选自code.facebook
作者:Jonas Gehring、Michael Auli、David Grangier、Denis Yarats、Yann N. Dauphin
机器之心编译
参与:吴攀、微胖、蒋思源
去年谷歌在机器翻译上取得了连续不断的突破,参阅《重磅 | 谷歌翻译整合神经网络:机器翻译实现颠覆性突破》和《重磅 | 谷歌神经机器翻译再突破:实现高质量多语言翻译和 zero-shot 翻译》。谷歌的方法用到了文本处理惯用的循环神经网络。近日,Facebook 也宣布在神经机器翻译上取得了重大进展,在超过了去年谷歌研究的水平的同时还实现了显著的速度提升。而和谷歌的方法不一样,Facebook 的方法采用了一种完全基于卷积神经网络的架构。机器之心对 Facebook 博客上的介绍文章进行编译,同时在文末附上了该研究论文的摘要介绍,另外该研究的相关源代码和模型也已经在 GitHub 上开源。
论文地址:https://s3.amazonaws.com/fairseq/papers/convolutional-sequence-to-sequence-learning.pdf
GitHub 项目地址:https://github.com/facebookresearch/fairseq
Facebook 的使命是让世界更加开放和互联,让每个人都能以自己偏好的语言享受视频和博文——当然,准确度和速度要尽可能最高。因此,语言翻译就显得很重要了。
今天,FAIR 团队推出了一项研究成果:使用一种全新的卷积神经网络(CNN)进行语言翻译,结果以 9 倍于以往循环神经网络(CNN)的速度实现了目前最高准确率。[1] 另外,你可以在 GitHub 开源许可下下载到 FAIR 序列模型工具包(fairseq)源代码和训练过的系统,研究人员可以打造用于翻译、文本摘要以及针对其他任务的定制化模型。
为什么是 CNN?
几十年前,最初由 Yann LeCun 开发的 CNN 已经成功用于多个机器学习领域,比如图像处理。不过,对于文本应用来说,因为 RNN 的高准确度,其已经当仁不让地成为了被最广泛采用的技术和语言翻译的最佳选择。
尽管历史表明,在语言翻译任务上,RNN 胜过 CNN,但其内在设计是有局限性,只要看看它是如何处理信息的就能明白这一点。计算机的翻译办法是:阅读某种语言句子,然后预测在另一种语言中相同含义的语词排列顺序。RNN 运行严格遵照从左到右或者从右到左的顺序,一次处理一个单词。这一运行方式并不天然地契合驱动现代机器学习系统的高度并行的 GPU 硬件。由于每个单词必须等到网络处理完前一个单词,因此计算并不是完全并行的。对比之下,CNN 能够同时计算所有元素,充分利用了 GPU 的并行,计算也因此更高效。CNN 的另一个优势就是以分层的方式处理信息,因此,捕捉数据中的复杂关系也更容易些。
在之前的研究中,被用于翻译任务的 CNN 的表现并不比 RNN 出色。然而,鉴于 CNN 架构潜力,FAIR 开始研究将 CNN 用于翻译,结果发现了一种翻译模型设计,该设计能够让 CNN 的翻译效果也很出色。鉴于 CNN 更加出色的计算效率,CNN 还有望扩大翻译规模,将世界上 6,500 多种语言(世界语言种类大约为 6,900 多种——译者注)纳入翻译范围。
在速度上达到当前最佳
我们的研究结果表明,与 RNN [2] 相比,我们的系统在由机器翻译协会(WMT)提供的广泛使用的公共基准数据集上达到了新的最佳效果。特别是,CNN 模型在 WMT 2014 英语-法语任务(该度量标准被广泛用于判断机器翻译的准确度)上超过了之前最佳结果 1.5 BLEU。我们的模型在 WMT 2014 英语-德语任务上提高了 0.5 BLEU,在 WMT 2016 英语-罗马尼亚语上提高了 1.8 BLEU。
对于实际应用,神经机器翻译的一个考量因素是我们为系统提供一个句子后,它到底需要多长时间进行翻译。FAIR CNN 模型在计算上十分高效,它要比强 RNN 系统快九倍左右。许多研究聚焦于量化权重或浓缩(distillation)等方法来加速神经网络,而它们同样也可被用于本 CNN 模型,甚至提速的效果还要大些,表现出了显著的未来潜力。
利用多跳注意(multi-hop attention)和门控(gating)来改善翻译效果
在我们模型架构中,一个明显不同的组件就是多跳注意,这个机制就像人类翻译句子时会分解句子结构:不是看一眼句子接着头也不回地翻译整个句子,这个网络会反复「回瞥(glimpse)」句子,选择接下来翻译哪个单词,这点和人类更像:写句子时,偶然回过头来看一下关键词。[3] 多跳注意是这一机制的增强版本,可以让神经网络多次「回瞥」,以生成更好的翻译效果。多次「回瞥」也会彼此依存。比如,头次「回瞥」关注动词,那么,第二次「回瞥」就会与助动词有关。
在下图中,我们给出了该系统读取法语短语(编码)并输出其英语翻译(解码)的情形。我们首先使用一个 CNN 运行其编码器以为每个法语词创建一个向量,同时完成计算。接下来,其解码器 CNN 会一次得到一个英语词。在每一步,该注意都会「回瞥」原法语句子来确定翻译句子中最相关的下一个英语词。解码器中有两个所谓的层,下面的动画给出了每层中注意完成的方式。绿线的强度表示了该网络对每个法语词的关注度。当该网络被训练时,其一直可以提供翻译,同时也可以完成对英语词的计算。

我们的系统另一方面是门控(gating),其控制了神经网络中的信息流。在每一个神经网络中,信息流也就是通过隐藏单元的数据。我们的门控机制将具体控制哪些信息应该需要传递到下一个神经元中,以便产生一个优良的翻译效果。例如,当预测下一个词时,神经网络会考虑迄今为止完成的翻译。而门控允许放大翻译中一个特定的方面或取得广义的概览,这一切都取决于神经网络在当前语境中认为哪个是适当。
未来开发
这种方法是一种可选的机器翻译架构,也为其它文本处理任务开启了新的大门。比如说,在对话系统中的多跳注意(multi-hop attention)让神经网络可以关注到对话中距离较远的部分(比如两个分开的事实),然后将它们联系到一起以便更好地对复杂问题作出响应。
以下为相关论文的摘要介绍:
论文:卷积序列到序列学习(Convolutional Sequence to Sequence Learning)

序列到序列学习(sequence to sequence learning)的普遍方法是通过循环神经网络将一个输入序列映射到一个可变长度的输出序列。我们引入了一种完全基于卷积神经网络的架构。相比于循环模型,其在训练阶段中所有元素上的计算都是完全并行的,且其优化更简单,因为非线性的数量是固定的且独立于输入的长度。我们使用门控线性单元简化了梯度传播(gradient propagation),而且我们为每个解码器层都装备了一的单独的注意模块(attention module)。我们在 WMT'14 英语-德语翻译和 WMT'14 英语-法语翻译上的准确度表现都超过了 Wu et al. (2016) 的深度 LSTM 设置,且在 GPU 和 CPU 上的速度都实现了一个数量级的提升。
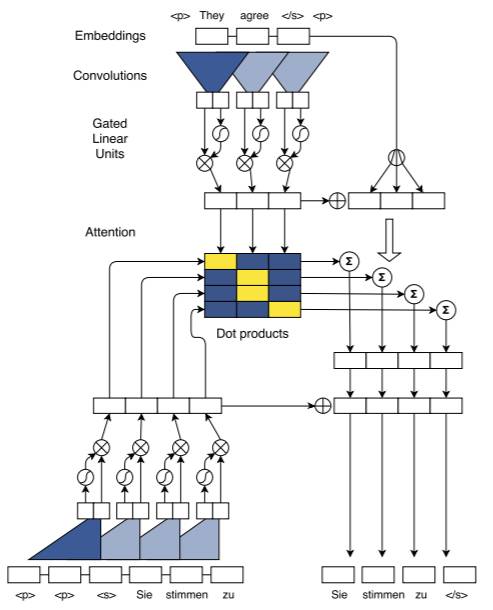
图 1:训练中批处理(batching)的图示。顶部是英语源句子被编码,同时我们为 4 个德语目标词计算所有的注意值(中间)。我们的注意只是解码器上下文表征(底部左侧)和编码器表征之间的点积。我们为解码器上下文增加了由该注意模块计算出来的条件输入(中部右侧),其可以预测目标词(底部右侧)。S 型和乘法框表示门控线性单元。

博客文章参考文献
[1] Convolutional Sequence to Sequence Learning. Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, Yann N. Dauphin.(即本论文)
[2] Google‘s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, Jeffrey Dean. Technical Report, 2016. 参考机器之心文章《重磅 | 谷歌翻译整合神经网络:机器翻译实现颠覆性突破(附论文)》
[3] Neural Machine Translation by Jointly Learning to Align and Translate. Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. International Conference on Learning Representations, 2015. 地址:https://arxiv.org/abs/1409.0473
原文链接:https://code.facebook.com/posts/1978007565818999/a-novel-approach-to-neural-machine-translation/
点击阅读原文,报名参与机器之心 GMIS 2017 ↓↓↓





