【像训练CNN一样快速训练RNN】全新RNN实现,比优化后的LSTM快10倍
1新智元报道
来源:ArXiv
作者:文强
【新智元导读】如何有效训练RNN是一个活跃的研究领域,有很多方法,但还没有哪种表现出了明显的优势,因此也让今天要介绍的这项工作值得注意。来自ASAPP公司和MIT的两位研究人员提出了一种名为“简单循环单元”(Simple Recurrent Unit,SRU)的结构,对现有门控单元做了调整,简化了状态计算的过程,从而展现出了与CNN、注意力和前馈网络相同的并行性。实验结果表明,SRU训练速度与CNN一样,并在图像分类、机器翻译、问答、语音识别等各种不同任务中证明了有效性。
项目已经开源:https://github.com/taolei87/sru
先看论文摘要,有个大概的了解:
标题非常直接,也是很多人都想实现的——《像训练CNN一样快速训练RNN》:

摘要
RNN因其状态计算固有的特性难以并行化因而很难扩展。例如,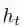
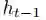
近来深度学习取得的许多进展都源于模型容量的增加和计算力的相应提升。模型容量增大,通常会涉及使用更大、更深的网络,而这些网络又需要复杂的超参数设置和调整。因此,不断增大的模型和超参数数量也大大增加了训练时间。
显然,计算力已经成为深度学习研究的一大主要瓶颈。作为应对,研究人员开始深入挖掘并行计算的潜力,很多人使用GPU加速训练来扩展深度学习。不过,虽然诸如卷积和注意力的运算非常适合于多线程/GPU计算,但是循环神经网络(RNN)仍然不太适合并行化。在典型的RNN实现中,输出状态
图1展示了cuDNN优化后的LSTM和使用conv2d的字级卷积的处理时间。可以看出,两者区别非常明显,即使是优化后的LSTM,运行速度也可能慢10倍多。
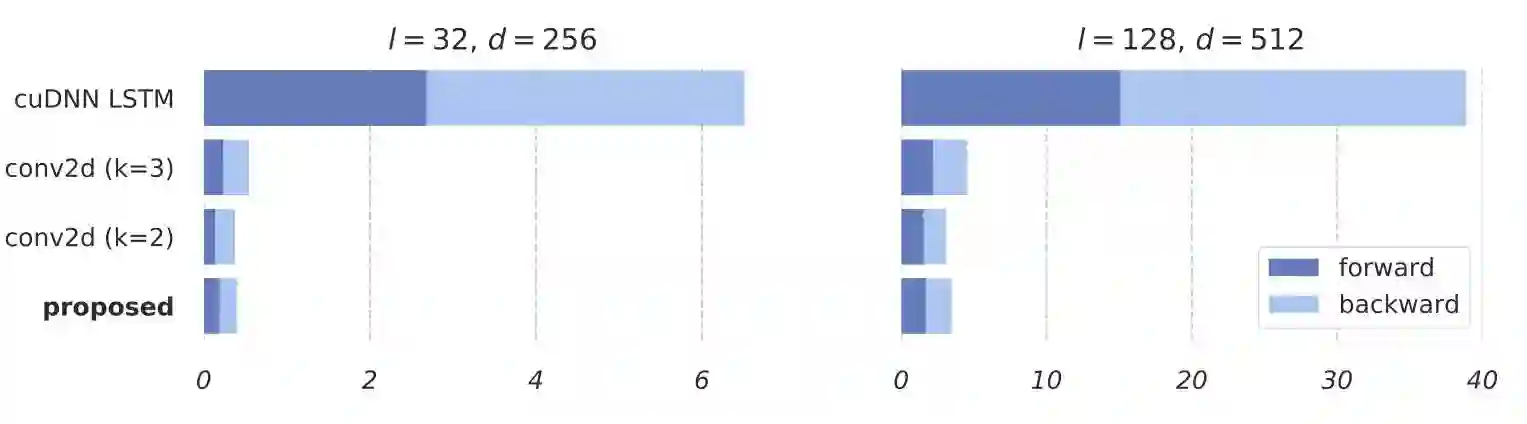
图1:cuDNN优化后的LSTM和使用conv2d的字级卷积的处理时间:即使是优化后的LSTM,运行速度也可能慢10倍多
于是,作者提出了“简单循环单元”(Simple Recurrent Unit,SRU),并在论文中表示其计算速度明显快于现有的循环实现。SRU简化了状态计算的过程,从而展现出了与CNN、注意力和前馈网络相同的并行性。
具体说,虽然SRU的内部状态ct的更新仍然与前一个状态ct-1有关,但是在循环步骤中不再依赖于
那么,SRU是怎么实现的呢?
作者指出,当前性能最佳的RNN,比如LSTM和GRU,都使用神经门(neural gate)控制信息流,缓解梯度消失(或爆炸)的问题。
因此,他们在此基础上,对门控单元进行了调整。具体说,作者新增加了两个特征:首先,他们在循环层之间增加了highway连接,因为此前的研究已经证明,像highway连接这样的skip connections,在训练深度网络时非常有效;其次,在将RNN正则化时,他们在标准的dropout外,增加了变分dropout,变分dropout在时间步长t与dropout使用相同的mask。
然后,作者将
经过这样的改善后,对于现有的深度学习库,SRU已经可以实现超过5倍的加速。接下来,作者还进行了CUDA级的优化,并在一系列不同的基准上进行测试,评估SRU的效果。
作者还在分类、问答、语言建模、翻译和语音识别等一系列不同任务中评估了SRU。
实验结果证实了SRU的有效性——与这些任务的循环(或卷积)基准模型相比,SRU在实现更好性能的同时,训练速度也更快。
图像分类

斯坦福SQuAD文本处理
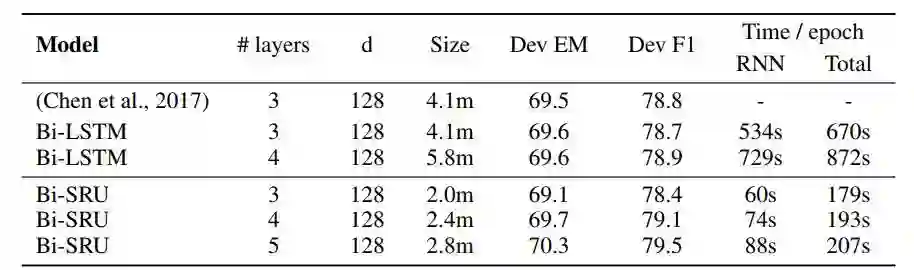
语言建模
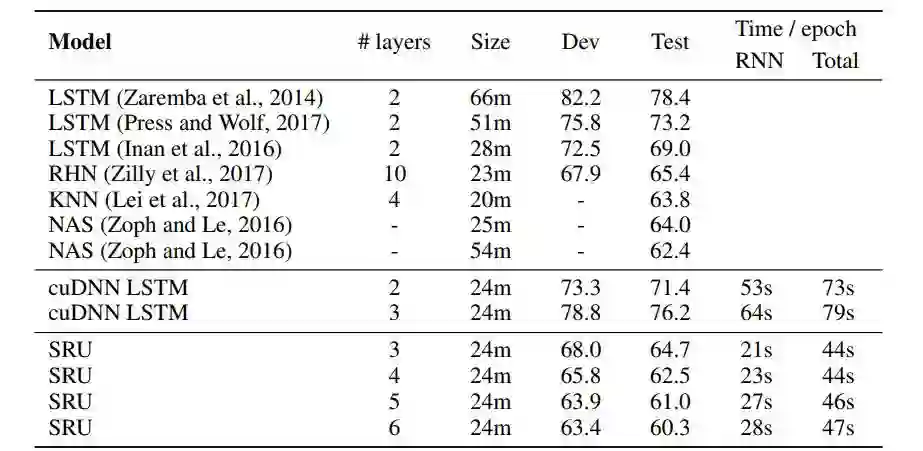
语音识别
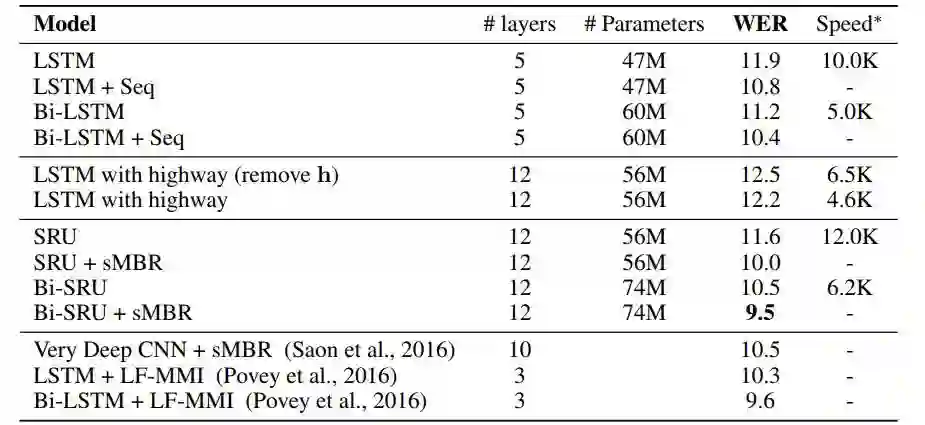
机器翻译
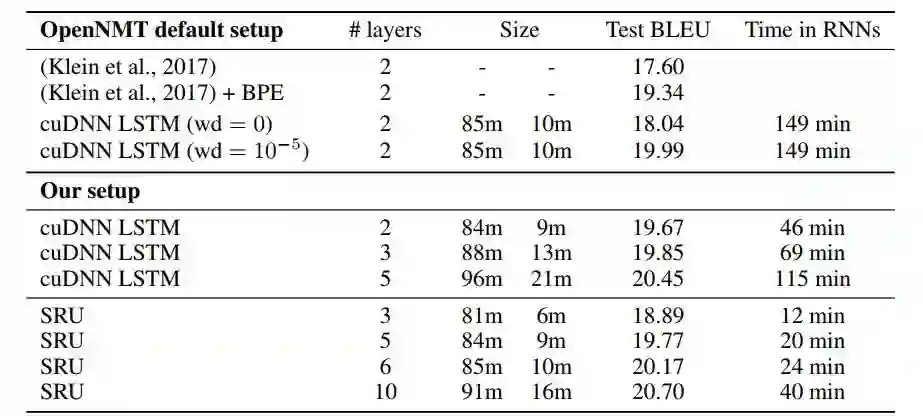
论文地址:https://arxiv.org/pdf/1709.02755.pdf
Github地址:https://github.com/taolei87/sru
说明:论文未经同行评议,这里有更多讨论:https://www.reddit.com/r/MachineLearning/comments/6zduh2/r_170902755_training_rnns_as_fast_as_cnns/
【号外】新智元正在进行新一轮招聘,飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~





