用于神经网络机器翻译的全并行文本生成
在过去的几年里,神经网络为文本分类和问题回答等自然语言任务的准确性和质量带来了快速的提高。深度学习导致的令人印象深刻的结果的一个领域是需要机器生成自然语言文本的任务;其中两个任务是基于神经网络的模型需要具有最先进性能的文本摘要和机器翻译。
然而,到目前为止,所有基于神经网络和深度学习的文本生成模型都具有相同的,令人惊讶的人类局限性:像我们一样,他们只能逐字,甚至逐字母地生成语言。今天Salesforce正宣布一个能够克服这个限制的神经网络机器翻译系统,以完全并行的方式一次翻译整个句子。这意味着用户等待时间降低了10倍,而翻译质量与最好的逐字翻译模型相近。
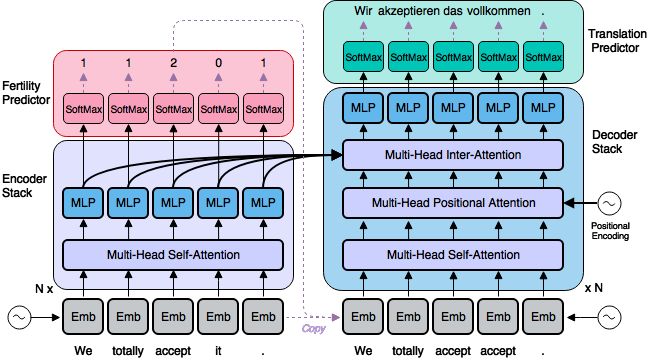
图一:我们的模型的概述。我们使用的所有层(包括文字嵌入,注意力,MLP和softmax层)可以并行操作,而尽管有这种并行机制,下面所描述的“派生预测器”,也可以实现高质量,有条理的输出转换。
高效的神经机器翻译
自2014年以来,随着神经网络和深度学习的应用,或者所谓的神经网络机器翻译,机器翻译领域已取得了巨大的进展。注意力的使用使机器翻译在2015年出现了一个跃进,这就是现在的从涉及到问题解答的自然语言处理任务的关键技术。
尽管神经网络机器翻译模型提供了比传统方法高得多的翻译质量,但神经MT模型在一个关键的方式中,也要慢得多:他们有更高的延迟,更多的完成翻译用户提供的新文本的时间。这是因为现有的神经网络机器翻译系统每次翻译一个单词都要运行整个神经网络,为生成每个单词都要用数十亿次计算。
因此,计算效率一直是最近神经网络机器翻译研究的主要目标。大约一年前,四个研究小组已经发表了关于更高效的神经MT模型的论文,主要是为了消除在深度学习序列模型中常见的递归神经网络层(RNN)的使用,但是由于它们固有的并行化的困难,所以进展缓慢。 DeepMind引入了ByteNet,它使用基于卷积神经网络的并行树结构来替代RNN。 Salesforce Research公司提出了QRNN,这是一种高效的RNN层替代方案,可以提高在机器翻译和其他任务中的性能。今年早些时候,Faceboookk AI Research发布了完全卷积神经网络MT模型,而Google Brain则描述了Transformer,一个最先进的完全基于注意力的MT模型。
所有这些方法都可以使模型训练更快,并且还可以在翻译时提高效率,但是它们都受到前面所述的同样问题的限制:它们都是逐字输出的。
克服逐字输出限制的困难
这是现有神经网络序列模型的基本技术特性的结果:它们是自回归的,这意味着它们的解码器(产生输出文本的组件)需要使用先前输出的文本来产生其输出的下一个字。也就是说,自回归解码器使得后面的单词依赖于前面的单词。这个属性有几个好处;特别是,它使自回归模型更容易训练。
我们的模型(非自回归,因为它没有这个属性)从最近出版的Transformer开始,具有相同的基本神经网络层,但是引入了一个完全不同的文本生成过程,这个过程基于一个新的“派生”应用,这是一个来自于IBM在20世纪90年代初推出的传统机器翻译研究。这种潜在的派生模式是本文的主要贡献。
非自回归神经机器翻译
之前的神经机器翻译模型和我们的新的非自回归模型之间的区别在以下两个动画中表示。紫色圆点代表“编码器1”中的神经网络层,“编码器1”是其工作是理解和解释输入句子(这里是英文)的网络;蓝色点代表“解码器2”中的层,其工作是将这种理解转换成另一种语言(这里是德语)的句子;而彩色的线代表层之间的注意力连接,允许网络结合来自句子不同部分的信息。请注意,两个模型中的紫色编码器层可以同时运行(动画的第一部分,具有密集的红色注意力连接),而蓝色解码器层必须在第一个动画中一次处理一个字,因为每个输出字在解码器开始产生下一个之前,必须准备好(见棕色箭头)。
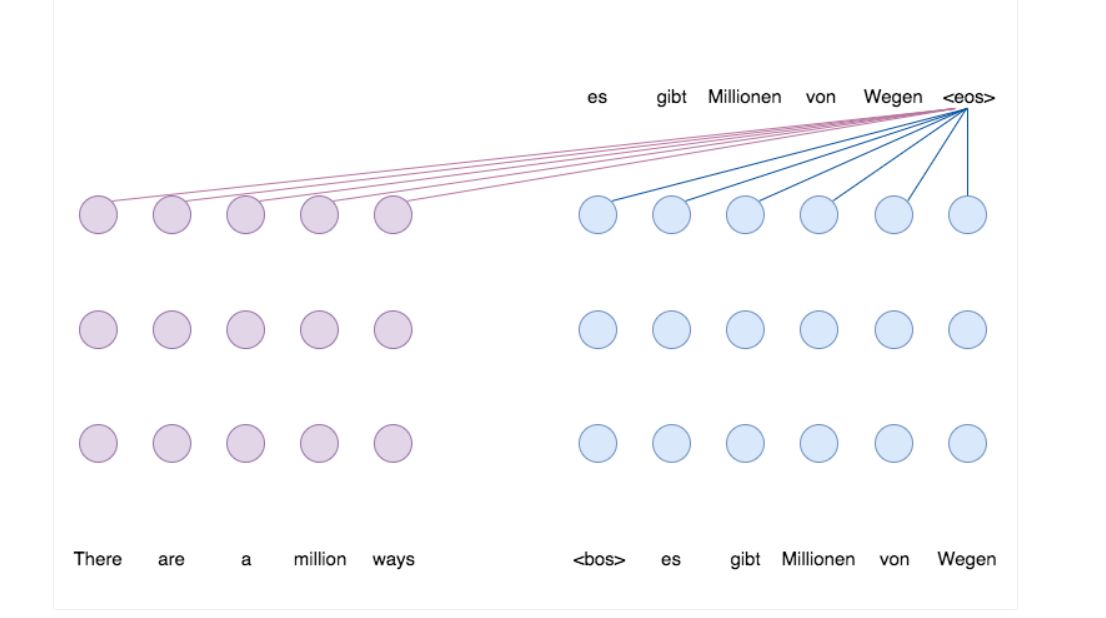
图2:自回归神经机器翻译。输出句子是逐字产生的,因为每个输出步骤在不知道先前产生的词的情况下不能开始。
下一个动画展示了我们模型的基本工作方式。这里编码器和解码器都可以并行工作,而不是一个字一个字。现在编码器有两个工作:首先它必须理解和解释输入句子,但它也必须预测一系列数字(2,0,0,2,1),然后通过直接复制来启动并行解码器从输入的文本中而不需要代表自动回归的棕色箭头。这些数字被称为派生;他们代表了每个单词在输出句子中要求多少空间。所以如果一个字的派生是2,那么这意味着模型决定在输出中分配两个单词来翻译它。

图3: 非自回归神经网络机器翻译使用我们的潜在派生模型。输出句子是并行生成的。
派生序列为解码器提供了一个计划或框架,使其能够并行地生成整个翻译。如果没有像这样的计划(称为潜在变量),并行解码器的任务就像一组翻译器,每个翻译器都必须提供一个输出翻译的单词,但是不能提前告诉对方他们准备说什么。我们将派生能力作为一个潜在的变量,确保这个隐喻小组的所有翻译人员都能够做出彼此一致的翻译决定。
实验
尽管数量级有较低的延迟,但我们的模型将我们测试过的语言对之一(英语译成罗马尼亚语)的最佳翻译质量(以BLEU评分衡量)与其他语言对联系起来,并取得了可喜的结果。
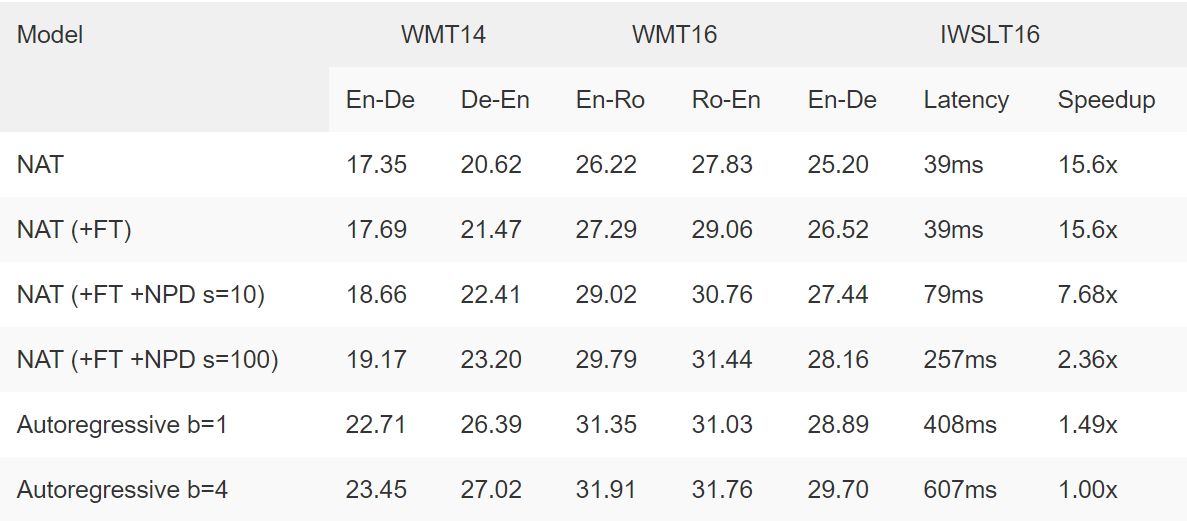
表1:五个流行数据集的非自回归翻译模型的结果。标有“NAT”的行显示了我们模型的性能,没有我们称之为微调的额外训练步骤; “NAT-FT”包括这些步骤。 “NPD”是指嘈杂的并行解码,这意味着并行地尝试几个不同的派生计划,然后选择最好的一个。自回归模型使用相同的架构和相同的模型大小; “b = 4”表示集束大小为4的集束搜索。
示例
我们模式的好处之一是有一个简单的方法来获得更好的翻译:并行地尝试几个不同的派生计划,然后从另一个同样快速的翻译模型中选择最好的输出。下面以罗马尼亚语为英语的示例显示“噪音并行解码”过程:
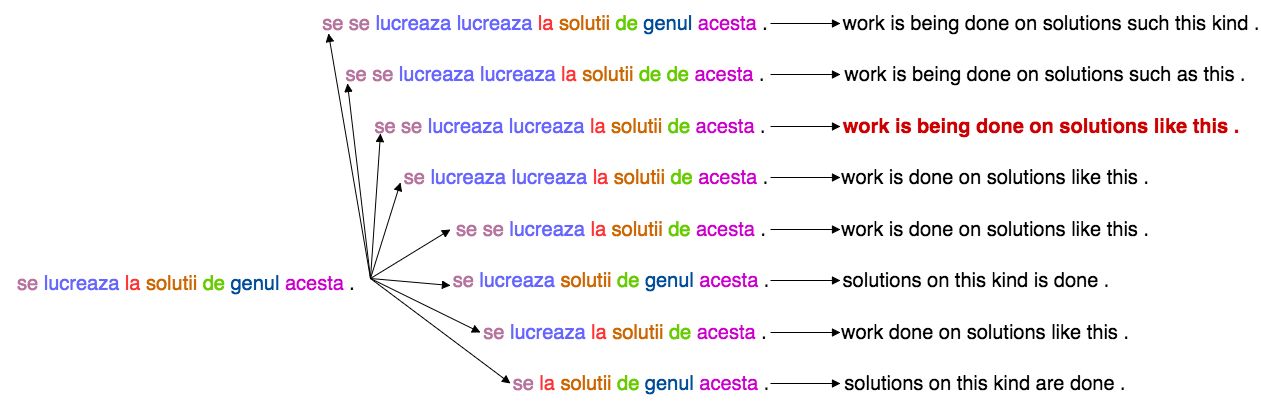
图4:噪声并行解码的例子。首先,编码器在输出句子中产生几个可能的计划,如中间所示,用于分配空间。这些派生计划中的每一个导致不同的可能的输出翻译,如右图所示。然后,一个自回归MT模型选择最好的翻译,用红色表示,这个过程比直接使用它产生输出要快得多。总之,NPD的两个步骤导致总延迟仅为非自回归模型的两倍。
引用出处
如果您在出版的作品中使用这篇博客文章,请注明引用自:
Jiatao Gu, James Bradbury, Caiming Xiong, Victor O.K. Li, and Richard Socher. 2017.
Non-Autoregressive Neural Machine Translation
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!




