学界 | 华为诺亚方舟实验室提出新型元学习法 Meta-SGD ,在回归与分类任务中表现超群
选自arXiv
机器之心编译
参与:Smith
从小数据中进行学习和调整的能力对于智能化来说是至关重要的,然而,我们现有的深度学习方面的成功则需要高度依赖大量标注数据。最近,华为公司诺亚方舟实验室的几名研究员提出了一种新型优化器 Meta-SGD,它非常易于训练,而且比其它元学习方法速度更快。机器之心对本文做出了概述。

原文链接:https://arxiv.org/pdf/1707.09835.pdf
Few-shot 学习对于那些对每一个任务都进行从零开始的孤立学习的算法来说是很有挑战性的。与之相反,元学习(meta-learning)则可以从很多相关性任务中进行学习,一个元学习者仅利用少量的样本实例就可以更精准且快速地对一个新的任务进行学习,在这里,元学习者的相关选择则是至关重要的。在本篇文章中,我们研发了一种类似于随机梯度下降(SGD),且易于训练的元学习方法,叫做 Meta-SGD,它可以仅在单步中就对任意可微分学习者进行初始化和调整。与流行的元学习者 LSTM 相比较,Meta-SGD 在概念上很简单,易于执行,并且可以被有效地学习。与最新的元学习者 MAML 相比,Meta-SGD 则有着更高的容量,不仅会对学习者初始化(learner initialization)进行学习,而且会对学习者的更新方向(update direction)和学习速率进行学习,所有的过程都是在一个单一元学习流程中完成的。Meta-SGD 在与回归(regression)和分类(classification)相关的 few-shot 学习方面展现出了具有高度竞争力的性能表现。
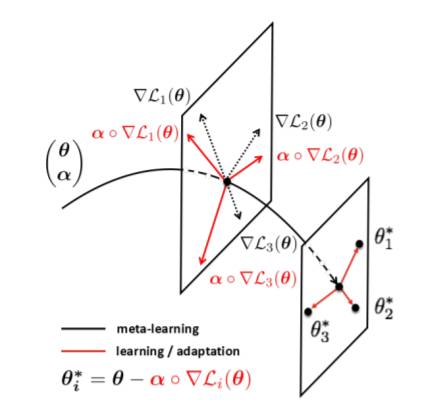
图 1: Meta-SGD 的 2 级学习过程的相关说明。逐步学习(Gradual learning) 在元空间 (θ, α) 中的不同任务中被执行,以对元学习者(meta-learner)进行学习。快速学习(Rapid learning) 在学习者空间 θ 中通过学习者被执行,以对特定任务学习者(task-specific learners)进行学习。
元训练
我们的目标是对元学习者进行训练,以让其在多个相关任务中表现出色。出于此种目的,假定在相关性任务空间中有一个分布 p(T),在这里我们可以随机地对任务进行采样。一个任务 T 包含被记为 train(T) 的一组训练数据以及被记为 test(T) 的一组测试数据。测试集中测试样本的标签也是已知的。我们的目的是使元学习者在任务空间中的期望泛化能力(expected generalization power)最大化。具体来说,给定一个从 p(T) 中采样出来的任务 T,元学习者基于训练集 train(T) 对学习者进行学习,但是泛化损失( generalization loss)是在测试集 test(T) 上被衡量的。我们的目的是对元学习者进行训练,以对期望泛化损失(expected generalization loss)进行最小化。在数学上,元学习者的学习法作为最优化问题被建立,如下式:
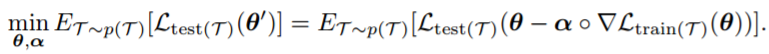
我们可以看到目标函数对 θ 和 α 来说都是可微分的,可以使用随机梯度下降来高效地解决上述优化问题,如图 2 和算法 1 所示。
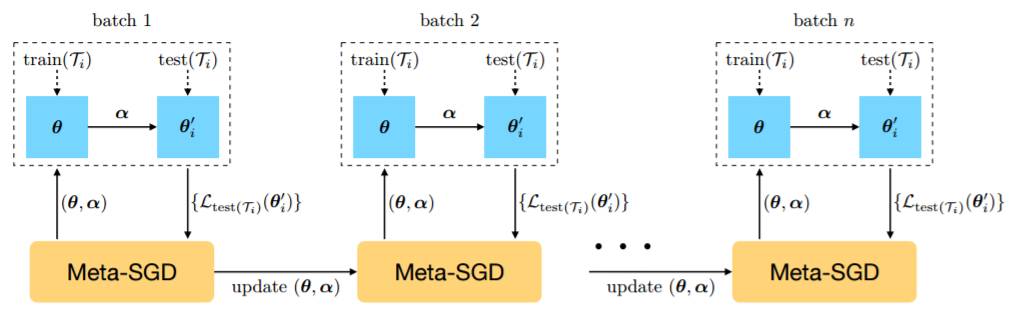
图 2:Meta-SGD 的元训练过程。

部分实验结果:
1.回归 (Regression)
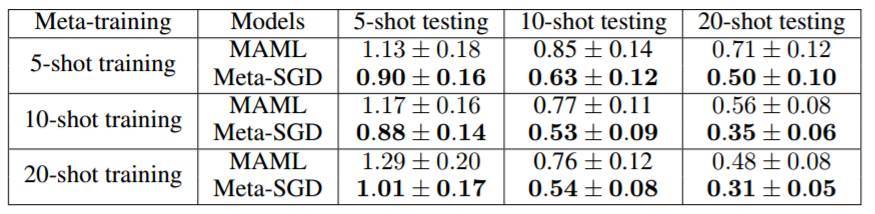
表 1:Meta-SGD 与 MAML 在 few-shot 回归方面的对比情况。
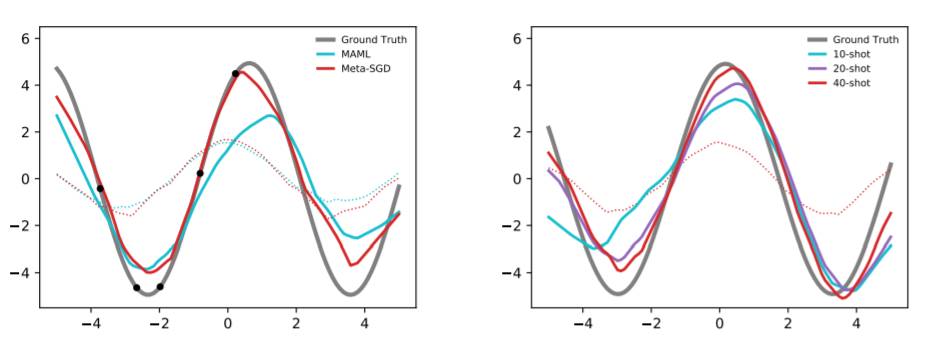
图 3:左:在一个随机 5-shot 回归任务中 Meta-SGD 与 MAML 的对比情况,两种情况下的初始化(虚线)和单步调适(adaption)后的结果(实线)如该图所示。右:在训练样本更多的情况下,Meta-SGD(10-shot 元训练)在元测试中表现地更好。
2. 分类(Classification)

表 2:在 Omniglot 上的分类精度。
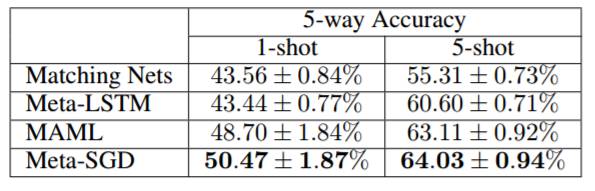
表 3:在 MiniImagenet 上的分类精度。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



