学界 | 香港科技大学提出L2T框架:学习如何迁移学习
选自arXiv
机器之心编译
参与:蒋思源
本论文提出了 L2T 框架,即一种学习迁移什么及如何迁移的算法。这种新型迁移学习算法从以前的迁移学习经验中学习迁移学习技能,然后应用这些技能去推断迁移什么及如何在以后的源域和目标域之间迁移。机器之心对该论文进行了简要介绍。
这 20 年当中我们积累了大量的知识,并且有很多种迁移学习的算法,但现在我们常常遇到一个新的机器学习问题却不知道到底该用哪个算法。其实,既然有了这么多的算法和文章,那么我们可以把这些经验总结起来训练一个新的算法。而这个算法的老师就是所有这些机器学习算法、文章、经历和数据。所以,这种学习如何迁移,就好像我们常说的学习如何学习,这个才是学习的最高境界,也就是学习方法的获取。

论文地址:https://arxiv.org/abs/1708.05629
迁移学习从源域学习知识,并利用这些知识促进目标域中的学习。迁移学习中需要解决的两个主要问题是迁移什么及如何迁移。对于源域和目标域,采用不同的迁移学习算法会产生不同的知识迁移。为了研究能最大化目标域学习效果的最优迁移学习算法,研究者必须全面探索所有现存的迁移学习算法,这种算法在计算上是十分困难的。作为一种权衡,我们选择了一种次优的算法,它以特定的方式要求大量的专业知识。同时,教育心理学普遍认为人类是通过元认知(meta-cognitive)反思归纳性迁移学习实践而提高迁移学习的能力并决定什么该迁移。受此启发,我们提出了一种新型迁移学习框架——Learning to Transfer(L2T)。L2T 能利用前面的迁移学习经验自动地判定迁移什么及如何迁移。我们从两个阶段建立起 L2T 框架:1)我们首先学习一个反射函数(reflection function)从经验中加密(encrypting)迁移学习技能。2)然后我们通过优化反射函数以推断迁移什么及如何迁移到一个新的目标域中。广泛的实验表明 L2T 与几个顶尖迁移学习算法相比有优越的性能,并且它在开发更多可迁移知识上十分高效。
3 学习如何迁移(Learning to Transfer)
这一章节首先介绍提出的 L2T 框架。然后再详细地推导该框架包含的两个阶段,即从以前的迁移学习经验中学习迁移学习技能,然后应用这些技能去推断迁移什么及如何在以后的源域和目标域之间迁移。
3.1 L2T 框架
若一个 L2T 智能体前面引导过几次迁移学习,并且 N_e 记录了迁移学习经验(如图 1 第(1)步所示)。我们可以定义每个每个迁移学习经验为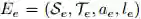
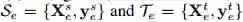
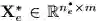
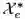
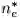
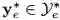
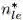

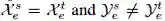
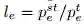
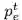
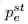
图 1:L2T 框架的图示
通过将前面所有的迁移学习经验作为输入,L2T 智能体旨在学习一个函数 f,因此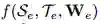
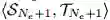
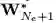
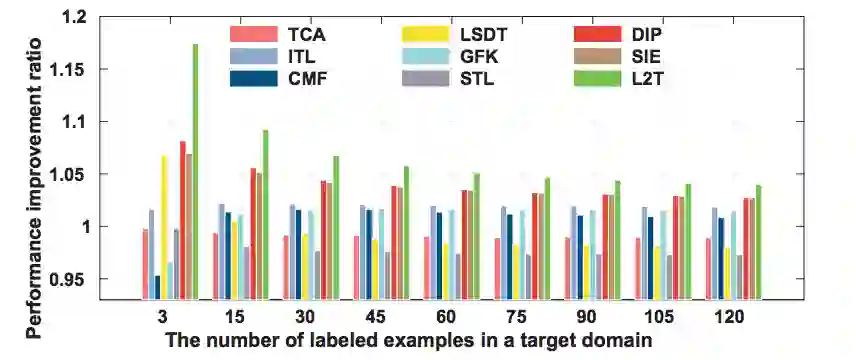
图 2:500 个源域和目标域测试对的平均性能提升率对比。
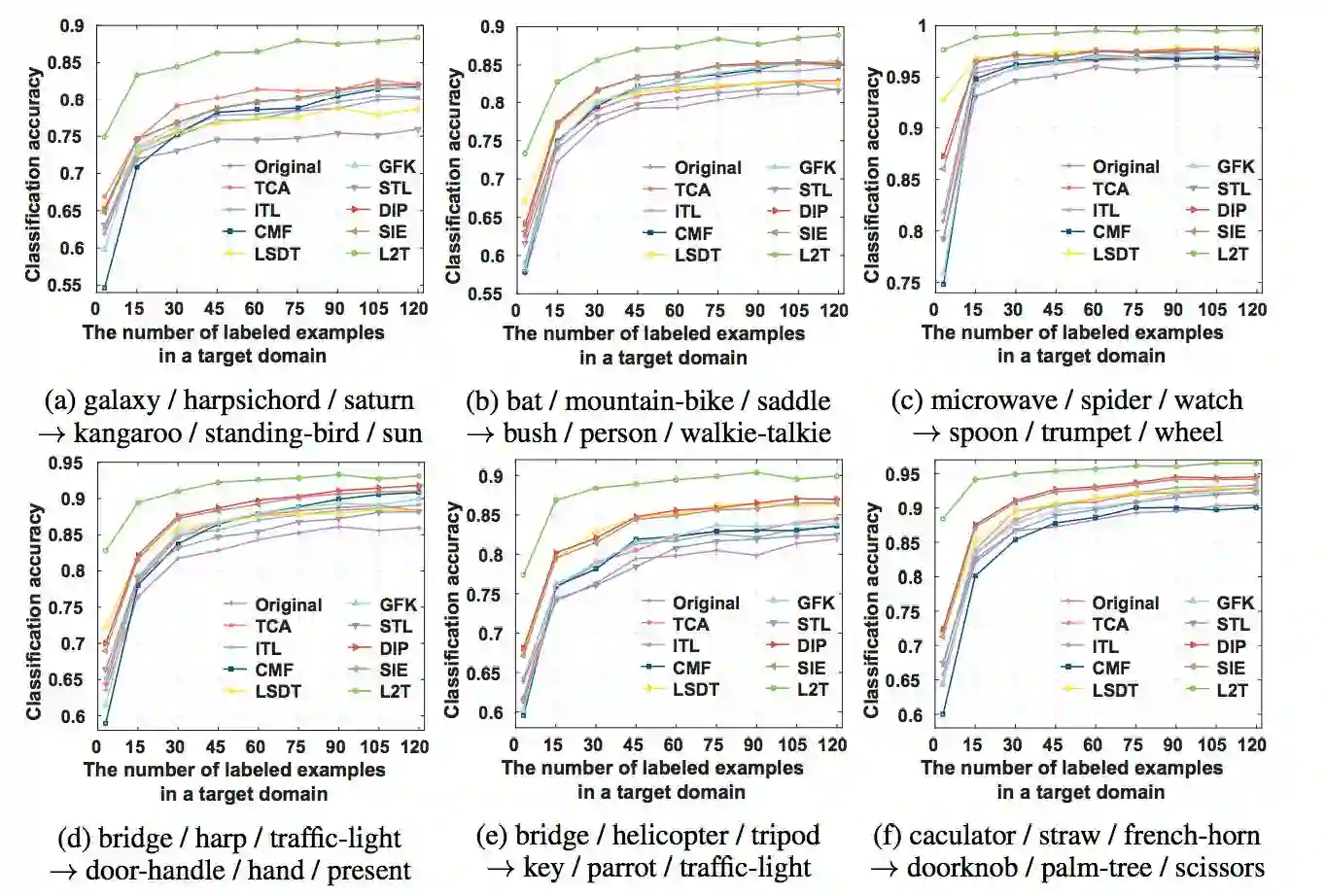
图 3:在 6 个源域和目标域对之间的分类准确度。
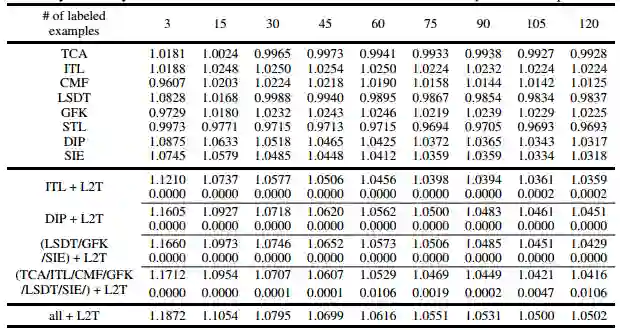
表 1:用于生成迁移学习经验的不同方法及它们带来的性能提升率。
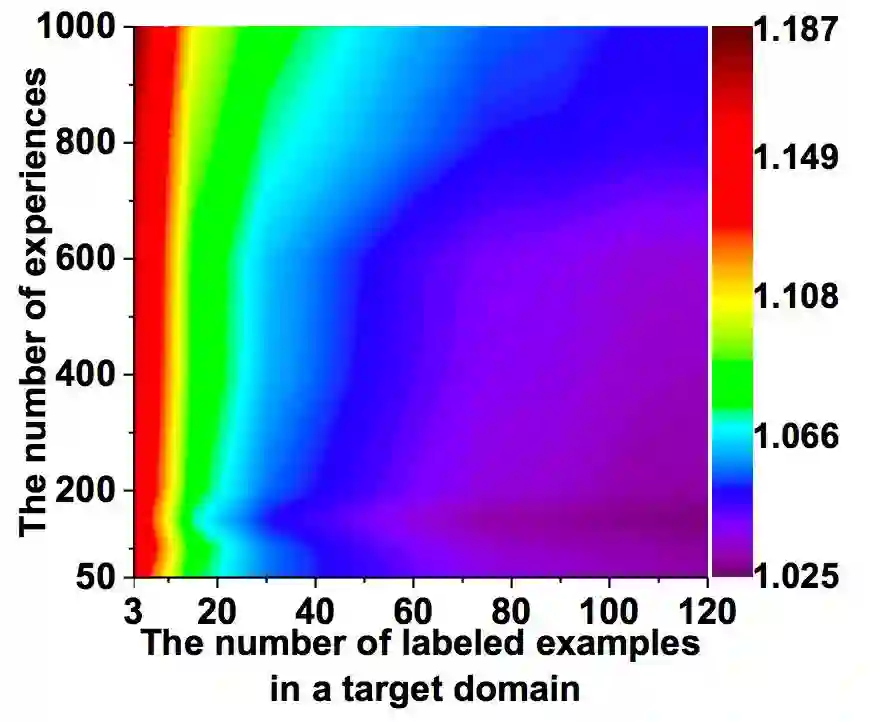
图 4:迁移学习经验和目标域标注样本数量的变化趋势。
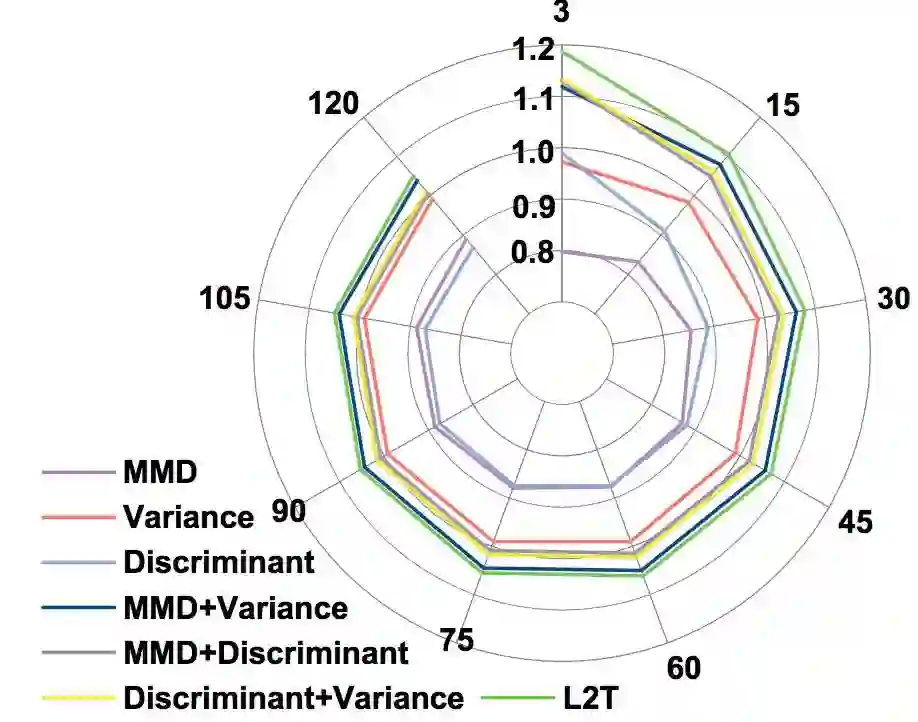
图 5:f 函数组成成分的变化。
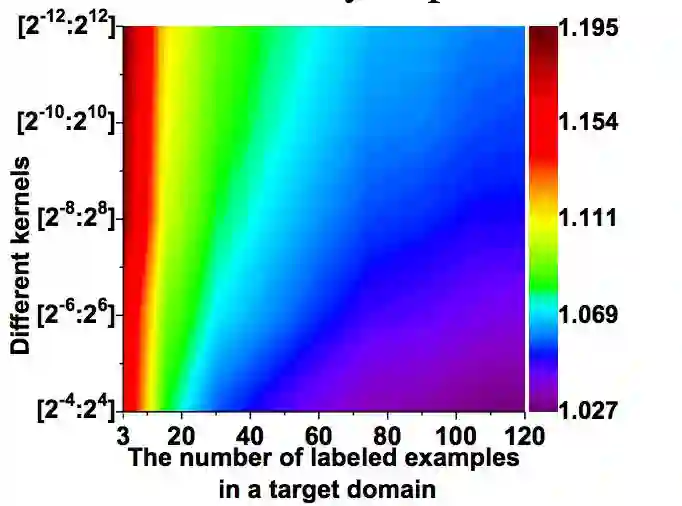
图 6:反射函数 f 中不同数量的核和目标域标注样本数量的变化趋势。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



