学界 | 伯克利联合OpenAI发布新型深度学习方法TCML:学习通用型算法
选自arXiv
机器之心编译
参与:Smith
快速学习的能力是区分人类智能和人工智能的关键特征。人类可以有效地利用先验知识和经验来快速学习新的技能。然而,用传统的监督式学习或强化学习方法进行训练的人工学习者(artificial learner),通常在仅有少量数据可用时,或当它们需要根据任务进行相应调整时,表现的很差。而元学习法(Meta-learning)则拥有着广阔的前景,它可以让人工智能体去学习通用型算法,并且可以通过重复利用先验知识来对新技能进行高效学习。

论文链接:https://arxiv.org/abs/1707.03141
摘要:深度神经网络往往可以在大量数据之中游刃有余,但是在数据不足,或当它们需要对任务中产生的变化作出迅速调整时,往往表现的很挣扎。近期,关于元学习(meta-learning)的相关研究工作试图通过在一个相似任务分布中去训练一个元学习者(meta-learner),从而克服这一缺点;目的是让元学习者通过学习一个可以采集它亟待解决问题的本质的高等级策略,从而对新型且相关性的任务进行归一化。然而,现在大部分关于元学习的方法往往都是手动设计的,要么是使用一个专用于某一特定应用的结构,或者是应用可以告诉元学习者怎样去解决任务的硬编码算法部分。而我们提出了一种简单且通用的元学习者结构,是基于时序卷积(temporal convolutions)的,它具有领域不可知性并且没有编入特定的策略或算法。我们通过监督学习与强化学习的相关实验,对我们提出的基于时序卷积的元学习者(temporal-convolution-based meta-learner —— TCML)进行了验证,并且说明了它的结果是超出现有的那些不通用且更加复杂的最新型方法的。
我们方法的动机源于下列关键准则:
简易性与多面性(Simplicity and versatility):一个元学习者应该在监督式学习和强化学习这两种环境中都是通用的。它应该具有足够的普适性,并且善于表达,从而可以学习到一个最优策略,而不是事先赋予其相应的解决策略。
学习过程中的时间本质(The temporal nature of the learning process):即使是在一个数据没有次序的监督性分类或回归环境中,元学习在本质上仍然是一个时序性过程,因为元学习者能够根据它的成功和失败来做出相应调整。
TCML 结构与深层堆叠式卷积神经网络相类似,这使得它们简单,通用,且用途广泛,而且因果性的结构(causal structure)使它们在复杂情况下也能处理时序数据(sequential data)。
TCML 也能更好的保留输入次序的时序结构;卷积结构则提供了更直接的,且高带宽的获取过去信息的能力,允许它们在固定时序段中运行更复杂的计算。
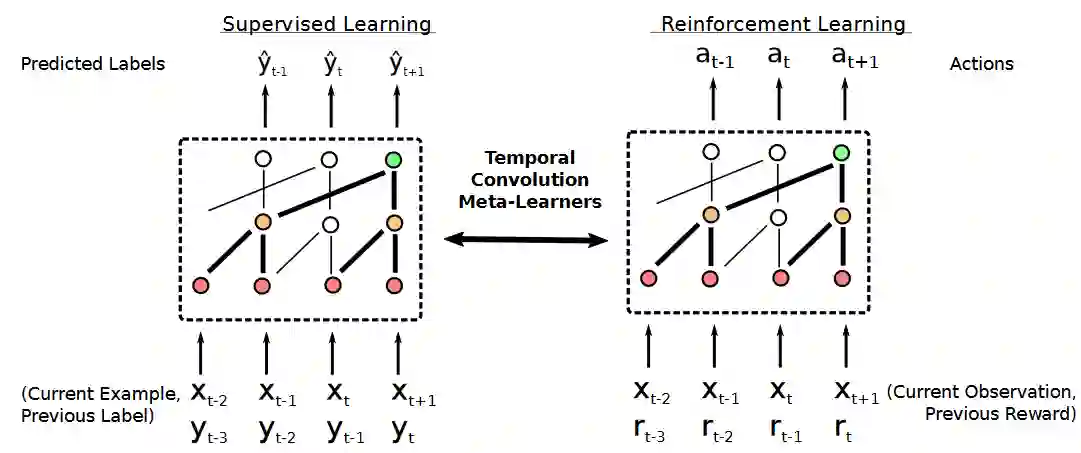
图 1:基于时序卷积的元学习者(TCML)的概况图。同种模型结构在监督性学习和强化学习中都可以被应用。
在监督型环境中,TCML 在每一时序步骤中都会接收一个输入实例(以进行分类或回归),以及前一个实例的正确标注(级联在一起),并且为当前实例输出预测结果。在强化学习环境中,它会从前一时序步骤(级联在一起)中接收环境中的当前观测值和奖励标量(scalar reward),并且输出一个关于未来动作的分布。如果任意的输入都为图像,我们就采用一个附加的堆叠式空间卷积结构(内嵌函数也会被学习),这样就可以在图像传输进TCML 前,把图像转化成特征向量。
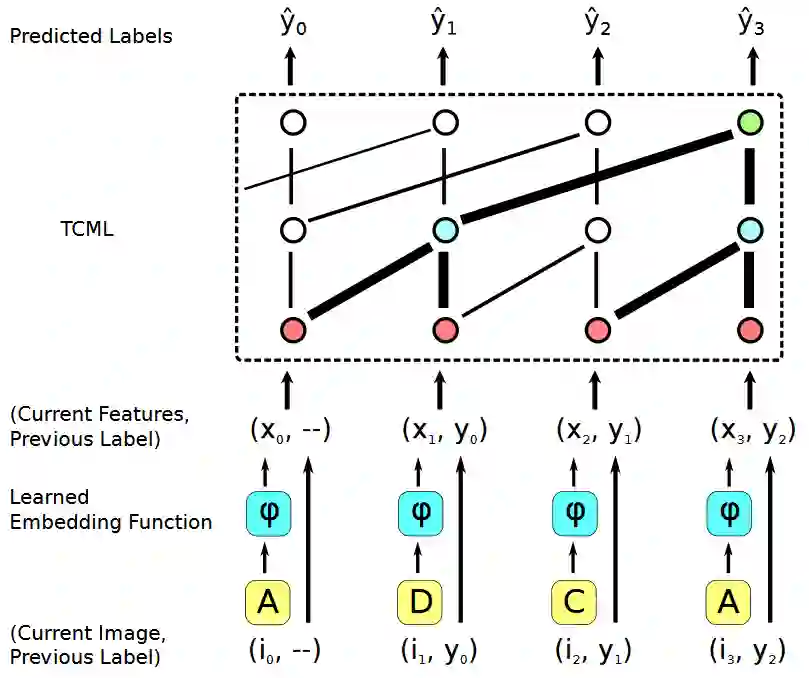
图 2:使用TCML 进行few-shot 图像分类的片段。给定一张图像,TCML 的输入是特征向量xt (由内嵌函数 xt = φ(it) 生成)以及前一图像 it−1 的标注 yt−1 。内嵌函数是通过TCML 进行联合学习的,训练TCML 以在基于相同片段中先前时序步骤的图像 i0, . . . , it−1 的情况下,为每一图像进行分类。举例说明,为了在时间 t = 3 时做出正确预测,TCML 需要(i)确定 x3, x0 看起来比 x3, x1 或 x3, x2 更相似,(ii)记住 x0 的标注是 y0,(iii)所以输出 y0 以作为 y3 的预测值。因此,为了使 TCML 在 few-shot 图像分类中取得成功,它需要去学习如何对图像进行比较,和如何评估它们的相似性,但是值得注意的是,在模型中并没有嵌入任何基于对比的策略。
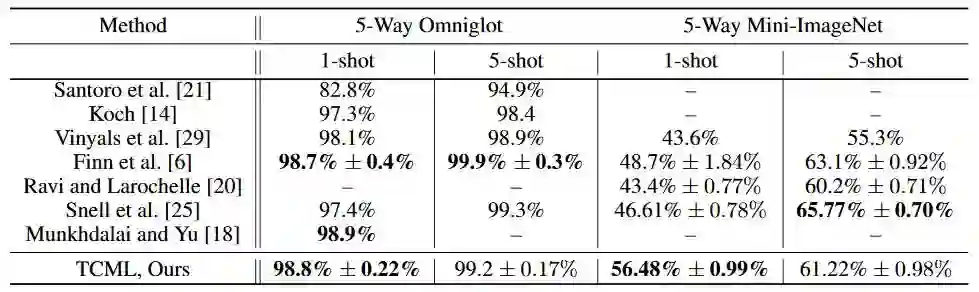
下表为 5-way, 1-shot 和 5-way, 5-shot 分类问题在每一数据集上的测试结果;可以看见TCML 大体上可以与那些手动设计的或特定领域的最新型方法相媲美,甚至是超过它们。
附录:
A. 用于Few-Shot 图像分类的TCML 结构
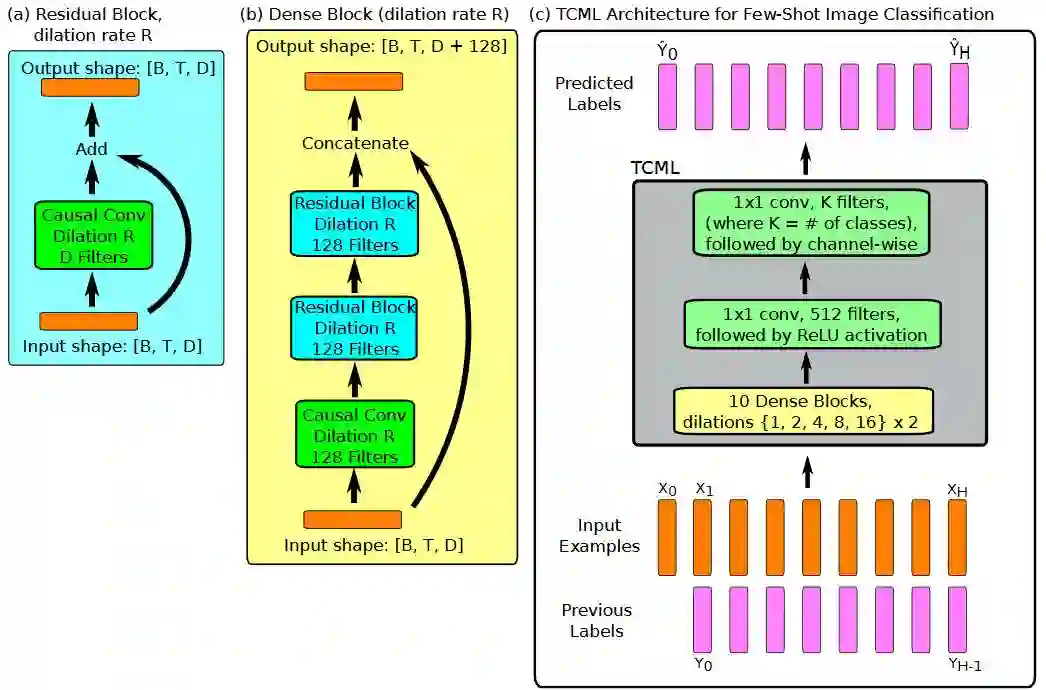
图 4:用于Few-Shot 图像分类的TCML 结构。输入和输出的形式已经被指定,维度是 ( batch size,B )×( sequence length, T ) × ( number of channels,D )。从左至右:(a)一个残差模块用来进行因果性卷积(causal convolution),并且将输入也添加到输出当中。(b)模型中的密集模块使用了一系列的因果性卷积和(a)中的残差模块,并且将输入与输出相连接。(c)整个模型主要包扩一系列这样的密集模块。上图所示的扩张率(dilation rate)是适用于Omniglot 数据集的;对于mini-Imagenet,我们使用的扩张率是 { 1,2,1,2,1,2,1,2,1,2,4,8,16 } 。
B. 用于mini-Imagenet 的内嵌函数结构
用于mini-Imagenet 的内嵌函数也使用了残差式连接(residual connection)。我们使用包含一系列卷积层的残差模块,其后是一个残差连接,然后是一个 2×2 的 max-pooling 处理。残差模块和整个网络的结构如图5 所示 。
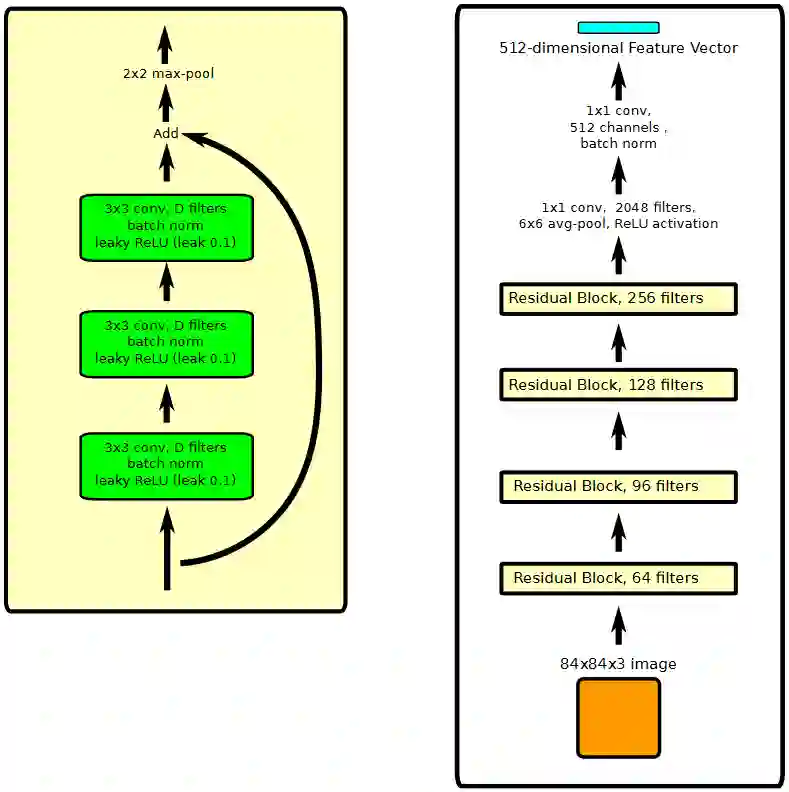
图 5:左图(a),用于mini-Imagenet 的内嵌残差模块;右图(b)整个网络结构,共有14层,大约300万个参数。它的输入是一个 84×84 的彩色图像,它的输出是一个 512 维的特征向量。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击阅读原文,查看机器之心官网↓↓↓



