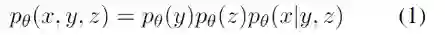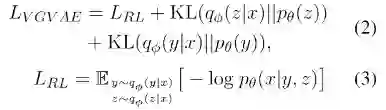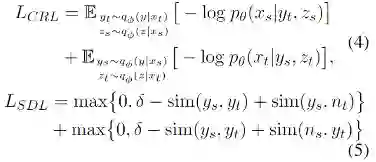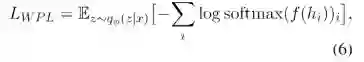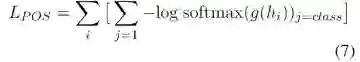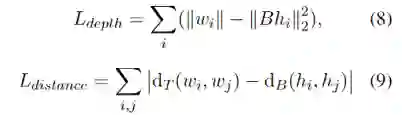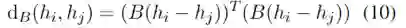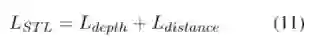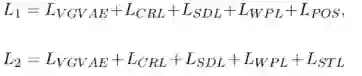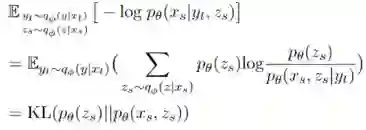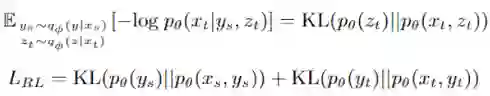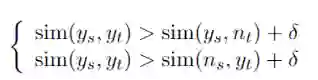![]()
©作者 | 吴林娟
论文标题:
Learning Disentangled Semantic Representations for Zero-Shot Cross-Lingual Transfer in Multilingual Machine Reading Comprehension
ACL 2022
http://arxiv.org/abs/2204.00996
https://github.com/wulinjuan/SSDM_MRC
![]()
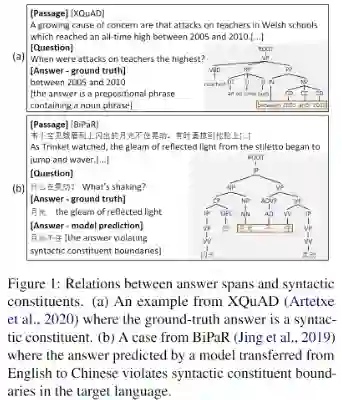
多语言预训练模型在机器阅读理解 (Machine Reading Comprehension, MRC) 任务上能够将知识从资源丰富的语言上零资源迁移到低资源语言。然而,不同语言中固有的语言差异可能会使零资源迁移后预测的答案跨度违反目标语言的句法约束。
我们提出了一种新的
多语言机器阅读理解框架
,该框架配备了孪生语义解耦模型(Siamese Semantic Disentanglement Model,
),实现在多语言预训练模型学习的表示中将语义与语法分离。为了显式地将丰富的语义知识迁移到目标语言,我们提出了两组针对语义和句法编码和解开的损失。在三个多语言机器阅读理解评估集上实验证明了我们提出的方法的有效性。
![]()
随着多语言预训练模型和多语言机器阅读理解评估数据集的提出,多语言机器阅读理解任务受到了越来越多的关注。基于多语言预训练模型的跨语言迁移方法也成为了多语言MRC的主流方法。但是我们发现基于预训练模型的迁移方法在目标语言上获取的答案跨度存在不符合句法约束的现象,如下图(b)中的例子所示,跨语言迁移模型获得的答案“月光不住”跨越了句法树的两个子树。在双语语料BiPaR上我们也进行了实验统计,跨语言迁移的方法降低了目标语言答案跨度和句法约束的一致性。
为了解决这类由于语言间句法差异带来的目标语言答案跨度不符合句法约束的问题,我们提出了基于多语言语义解耦表示的跨语言迁移方法实现多语言阅读理解。将多语言预训练表示的语义和句法部分分离,通过迁移解耦的语义表示减少句法信息对于跨语言带来的消极影响。
![]()
贡献
我们的贡献包括以下三点:
1. 提出了一种多语言MRC框架,通过显式迁移源语言解耦的语义知识来减少由于句法差异带给目标语言答案跨度识别的消极影响;
2.提出了一种多语言孪生语义解耦模型,可以有效将多语言预训练模型中的语义和句法分离;
3.在三个公开权威的多语言MRC数据集(XQuAD、MLQA和TyDiQA)上证明了我们的模型相比。
![]()
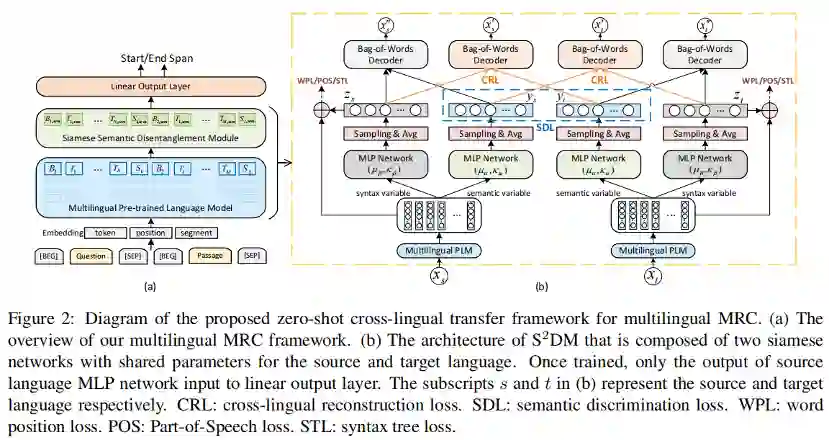
模型
我们提出了一种新的多语言机器阅读理解框架,如图(a)所示,主要由多语言预训练模型、语义解耦模块和用于MRC预测的线性输出层组成。其中语义解耦模块来自于孪生解耦语义模型(Siamese Semantic Disentanglement Model,
)的一部分,模型最终输出对于答案跨度的起始和终止位置的预测。
我们的多语言MRC模型的训练主要分为两步:首先使用带标注的平行语料对孪生语义解耦模型S2DM进行训练,期间固定预训练模型的参数;然后将训练好的
模型中的语义编码模块((b)中绿色的模块)嵌入到MRC框架中,通过在源语言MRC数据集上微调预训练模型和线性输出层实现阅读理解。训练好的模型可以在其他目标语言上测试阅读理解的效果。
模型构建的假设是:句子
是由语义变量
和句法变量
组成。模型基于VGVAE将语义变量假设为vMF分布,将句法变量假设为高斯分布,句子和两个变量的联合分布形式化为:
VGVAE的目标函数为:
![]()
包括重构损失RL和两个变量分布的KL散度损失。除此之外,为了让句法和语义变量获取更多相应的信息我们设计了多个损失。
为了鼓励语义变量y捕捉语义信息,我们额外设计了跨语言重构损失CRL和语义辨别损失SDL:
![]()
其中下标s表示源语言,下标t表示目标语言,n代表非平行的样例,sim()是相似度计算函数。
为了让句法信息和语义分离,我们也引入了了句法相关的损失,包含无监督的词序预测损失WPL和有监督的词性标注损失POS以及句法树预测损失STL。WPL和POS表示如下:
也就是对每个词进行位置的预测和词性的预测,然后计算交叉熵损失。
为了学习结构化的句法信息,我们设计了句法树损失STL。这也是基于现有工作研究发现,预训练模型已经编码了句子的句法结构。为了将结构信息转化为序列信号进行学习和预测,我们参考结构探针的设计把句法树的预测看作两个子任务:单个词在句法树的深度预测以及两个词在句法树中的距离预测。通过给定一个矩阵
对解耦的句法变量表示进行线性变换,两个子任务的损失计算为:
其中
表示句子树中第i和第j个词之间的边数,而
是经过线性变换后两个词表示的L2距离平方:
为了验证不同粒度的句法信息对于解耦模型的影响,我们根据不同的句法任务设置了两个解耦模型:
和
,对应的损失分别为:
由于解耦模型需要在带有标注的平行语料上训练,然而不是所有语言都有相应的训练语料,于是我们对模型的泛化性进行了分析。从两个重构损失和语义判别损失分别证明了解耦后的语义和句法表示的语言无关性。
由于无论源语言还是目标语言的句法(或语义)变量最终都会拟合到相同的分布:标准正态分布和均匀vMF分布。所以
和
最终会拟合到相同的分布,
和
最终也会拟合到相同的分布。这符合我们使用孪生网络结构的动机。
最大化
鼓励目标语言语义向量接近并行的源语言语义向量,保障了语义向量的语言无关性。
综上可以证明
模型获得的语义和句法向量的语言无关性。
![]()
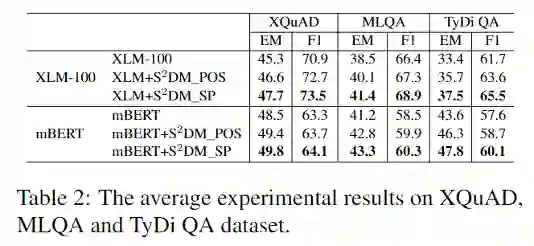
基于mBERT和XLM-100实现了我们的MRC模型,两阶段的训练集分别来自多语言通用依存树库UD 2.7和英语MRC数据集SQuAD1.0。我们在三个公开的多语言评估数据集上对模型进行了评估,基线模型为基于mBERT和XLM-100微调的多语言MRC模型,在MLQA数据集上和现有工作LAKM进行了比较(在预训练模型的基础上引入短语知识库增加了短语边界检测预训练任务)。实验结果如下几个表格:
我们的模型在三个数据集上有效提升了基于mBERT和XLM-100微调的多语言MRC模型,而且对于没有S2DM模型训练集的语言也得到了提升,例如XQuAD中和XLM相比,模型在希腊语(el)、 罗马尼亚语(ro)和越南语(vi)上的EM值分别提升了6.2%、2.4%和1.8%。
和LAKM对比,其外部训练数据大小高于我们三个数量级,但是我们获得了和LAKM差不多的效果。
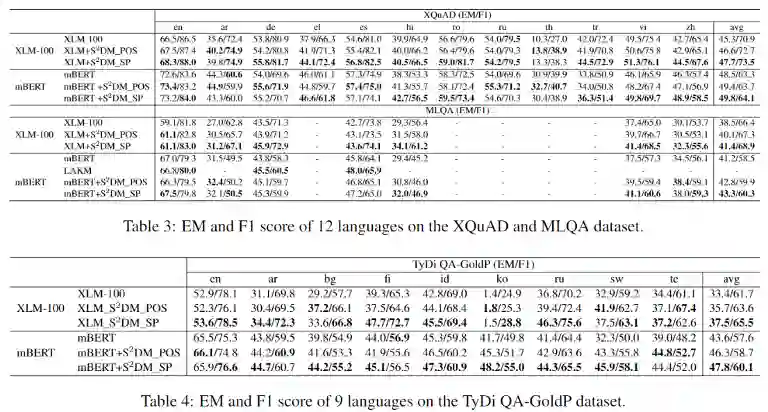
TyDiQA-GoldP数据集比XQuAD和MLQA更具挑战性。模型在所有8种低资源目标语言的EM或F1分数上都有提升。其中,在与英语语系不同的芬兰语(fi)和俄语(ru)中,模型
的EM性能相比基线分别提高8.4%和9.5%。
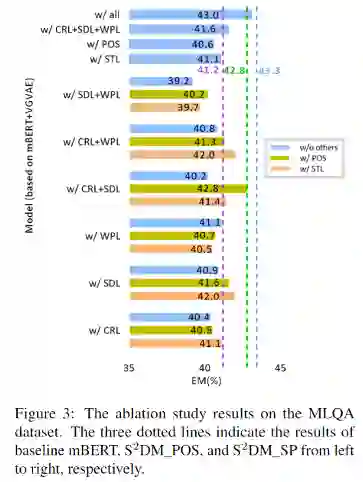
在无解耦训练语料的斯瓦希里语(sw)的EM比mBERT基线高13.6%。我们对设计的loss也进行了消融实验,证明了每个loss的有效性和必要性。消融实验结果如下:
更进一步的,我们对孪生网络结构、解耦效果进行了验证,结合语义表示可视化说明解耦的效果。在BiPaR数据集中证明了我们的模型有效提高了目标语言答案跨度和句法约束的一致性,符合我们的动机。
![]()
总结
本文对由于句法差异导致跨语言迁移过程中存在目标语言答案跨度和句法约束不一致的问题进行了探究,通过解耦多语言的语义和句法表示,然后显式迁移语义表示减少句法差异带来的消极影响。通过在三个多语言阅读理解评估集上证明我们方法的有效性,并进一步通过理论分析和实验验证证明了MRC模型的泛化性以及解耦的有效性。文章从句法入手解决跨语言阅读理解的问题,初步证明了句法对于跨语言语义理解任务的助益,后期工作将深入探索句法信息和跨语言任务的结合,欢迎大家与我们探讨交流。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()