论文浅尝 | 改善多语言KGQA的 Zero-shot 跨语言转换

笔记整理:谭亦鸣, 东南大学博士生
来源:NAACL'21
链接:https://aclanthology.org/2021.naacl-main.465/
概述
为了扩展多语言知识图谱问答的应用,Zero-shot方法成为一个研究趋势。在Zero-shot的设定下,通过高资源语言的训练数据构建模型,解决无标注的多语言问题。一个直观的方法是使用多语言的预训练模型(例如m-BERT)来做跨语言的转换,但目前优势语言与其他语言的问答性能之间仍然存在明显的差异。在这篇论文中,作者提出了一种无监督双语词归纳方法(BLI)将优势语言的问题(论文中的原语言)映射到其他语言上,作为扩展训练集。从而解决训练和推理之间的语言不一致问题。进一步的,通过一个对抗学习策略来解决扩展集存在的语法障碍问题,使得到的模型具有语言和语法的独立性。在一个具有11种Zero-shot数据集上实验验证的该方法的有效性。
动机
对于多语言图谱问答任务, 现有的benchmark广泛使用了翻译方法, 即利用机器翻译将优势语言资源的训练数据翻译为其他语言, 从而扩充为多语言训练集. 但是这类方法严重依赖于翻译方法的性能, 显然高性能翻译器并不是满地都是.
为了使方法能够适用于更多的语言, 作者假设这个任务场景里不具备人工译者和平行语料的资源. 对应的, 为了解决训练数据扩充, 作者引入了一个基于BLI的完全无监督机器翻译方法. 作者判断BLI方法有效的依据在于KGQA面对的往往是短句, 对于长距离依赖的影响不大, 而语言一致性能够带来更大收益.
为了缓解BLI引起的句法障碍问题, 作者使用了一个对抗学习策略, 即在编码器顶层设置一个分类器用于区分输入的是源语言句子还是BLI翻译得到的句子, 通过这种做法使编码器对于语言的敏感性减少, 从而适用于多语言任务.
方法
作者首先建立了一个面向单语问题的基础框架, 包含三个主要模块, 如图1:
1.推理链排序: 对于链接到的问题实体, 首先找到其潜在的候选链(来自链接实体+两跳之内的另据), 而后与将链与问题计算相关性, 取Top-1作为目标推理链2.类型约束排序: 对于1中给出的推理链, 枚举出已知变量和lambda变量的类型候选,因为这两个变量之间几乎没有黄金类型约束的重叠,一个的语义匹配模型对两者都是足够的,从而确定了推理链上的节点(变量)的类型.3.聚合分类器: 针对问题中涉及的聚合操作如: 布尔, 计数和事实, 构建分类器判断聚合类型, 而后将聚合操作约束也添加到生成的查询图中
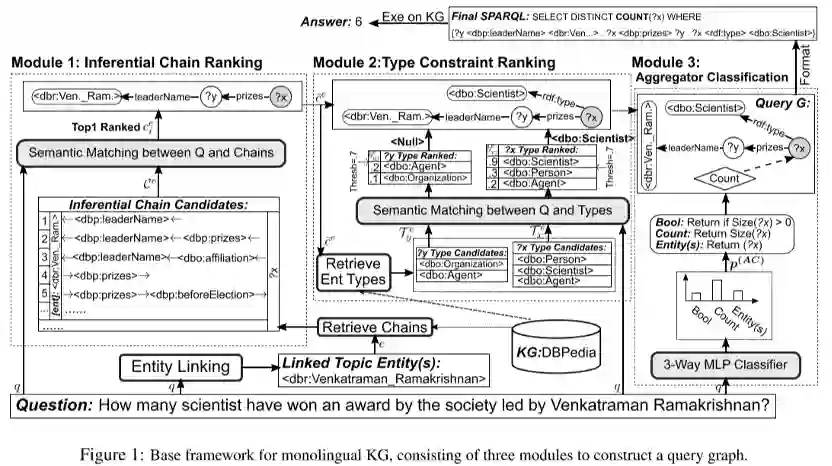
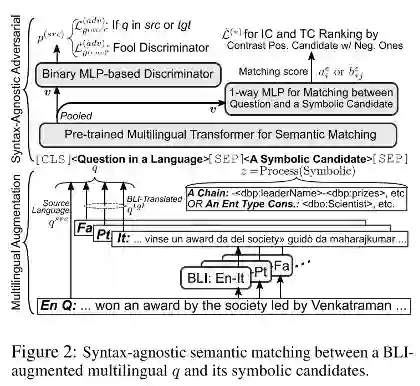
图2是作者提出的基于BLI的多语言问题语义匹配模型.
首先, BLI方法实际上是通过找到一个线性转换矩阵, 使得不同语言的预训练单语词向量之间差异最小, 即如公式6:
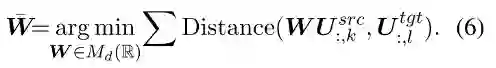
基于BLI作者建立了一个字对字翻译器
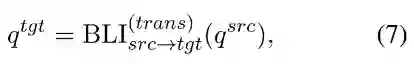
考虑到图谱问答主要是词或短语级别的匹配, 通过字对字翻译得到的序列可以满足这个需要, 另一方面, 关于翻译错误带来的影响, 作者描述为, 直观上, 他们的词向量在空间上接近, 错误的词级别翻译可以视作微量的噪声, 对于具备鲁棒性的Transformer-based编码器来说, 不会造成什么影响.
在多语言问答场景中, 基础模型主要又以下一些变化:
1.推理链排序: 对于每个推理链, 通过三种方式丰富它的谓词: a. 将camel表示的短语转换为序列格式的词; b. 增加或减少方向信息的前缀; c. 在局部封闭假设下链接高频类型;2.类型约束排序: 待匹配的问题和符号候选通过[CLS],[SEP]的标记连接起来, 输入预训练编码器后在经过Pool(.), 后者表示使用[CLS]的上下问来表示整个输入. 这里的预训练编码器使用的是m-BERT
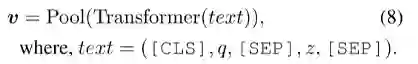
3.聚合分类器: 由多语言预训练编码器+MLP-based的预测层构成.
实验:
数据集:
作者主要使用了两个知识图谱问答数据集:
LC-QuAD(单语) 包含5000个英语问题-SPARQL对, 其中1000用作测试集
QALD-multilingual(多语言), 包含12种语言, 429个问题全部作为测试集, 使用LC-QuAD作为训练集.
实验结果:
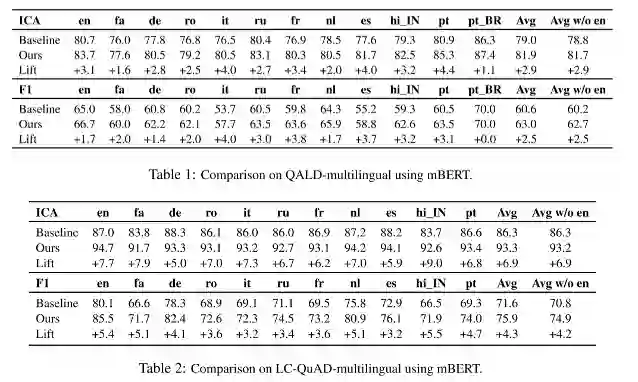
主要结果(评价指标为ICA与F1)
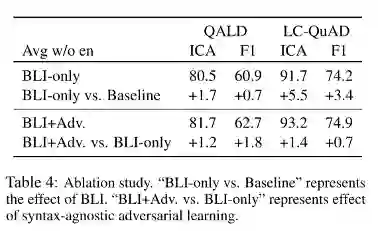
消融分析:
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。



