【泡泡图灵智库】面向移动相机的概率稠密重建(IROS)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Probabilistic Dense Reconstruction from a Moving Camera
作者:Yonggen Ling, Kaixuan Wang and Shaojie Shen
来源:IROS 2018
编译:凌勇
审核:李阳阳
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,我是来自清华大学人工智能与机器人中心的凌勇,今天为大家带来的文章是——面向移动相机的概率稠密重建,该文章发表于IROS 2018。
本文提出了一种利用单个单目相机在线进行稠密重建的概率方法。与静态立体视觉相比,运动立体视觉的深度估计更具有挑战性,因为视差不足、视觉尺度变化、姿态误差等原因。我们利用连续深度估计问题中的空间与时间相关性来提高单目深度估计的鲁棒性和准确性。本文提出了一种在线递推概率方法,用于计算具有相应协方差和内点概率期望的深度估计。我们将所获得的深度假设以不确定性感知的方式集成到密集3D模型中。通过与TUM RGB-D SLAM和ICL-NUIM数据集中的最新方法进行比较,我们证明了所提出方法的有效性,同时也在室内与室外的实验中展示了性能。
主要贡献
1、本文考虑深度估计与深度集成的联合概率问题。
2、关于聚集成本及其概率建模的详细讨论。
3 、一个使用了空间与时间上相关性的在线递推概率方法。
算法流程

图1 本文方法的完整流程图
整个系统的流程如图1所示,包括了三个部分:深度估计,假设筛选和不确定感知深度集成。
1、动态立体视觉的深度估计
稠密重建的系统是在基于特征的SLAM系统之上的,为我们的系统实时的提供相机的位姿。我们为每一个关键帧计算深度估计。
1) 时域成本聚合:我们将最近的一个关键帧设置为参考帧,并从经过的帧中聚集信息。选择跨越不同视差范围的a(我们设置为5)个帧。它们均匀地覆盖在与参考帧0到p(100)个像素平均视差偏差的范围内。该偏差用带有旋转补偿的跟踪特征的平均角点位置差计算。为了适应不同场景深度的环境,我们根据视差偏差而不是实际距离来选择过去的帧。
为了便于在线计算,我们将每个深度估计限制为L(L=64)个深度样本之一。L个深度样本在可行的深度范围内不是均匀分布的。相反,它们遵循从视差到深度的原则:

基线的设置与预测的环境有关,我们设置视差为0到L-1,根据公式能够得到L个深度的样本,对于参考帧中的一个像素而言,其深度在深度样本中,我们将其投影到选择的个帧当中,得到:
这里使用像素光度的误差来进行损失函数的定义,注意由于像素不一定能投影到每一帧,要结合投影做出剔除:
2) 空域管理:我们注意到,在成本聚合步骤之后使用简单的赢者通吃策略不能产生可靠的深度估计,因为它不能还原深度图像的分段线性性质。此外,在无纹理或具有重复图案的区域中,深度改变的聚合成本是相似的。因此,由赢者通吃策略得到的深度估计受到图像噪声的很大影响。因此,我们通过使用[10]中提出的半全局优化来合并相邻深度之间的空间约束。为了在复杂度和精度之间取得平衡采用了四路径动态规划。
3) 局部深度决策和深度细化: 由于之前估计的深度是离散的,准确性不是很高,所以需要进一步调整。对于第一种情况,先计算抛物线参数,再求解抛物线顶点。对于第二种情况深度估计是不可靠的,我们将其视为外点。

图2 两种深度估计函数情况
1.2 基于贝叶斯高斯Beta过程的假设滤波
1) 准备工作:我们发现前一步会由于遮挡,纹理缺失以及光度强烈变化会导致一些外点。与16中不再考虑外点不同,我们显示的处理了外点。我们假设外点的深度在采样集合中是均匀分布的。我们将其建模为高斯+均匀分布模型。
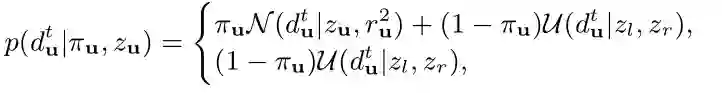
深度的后验概率为:
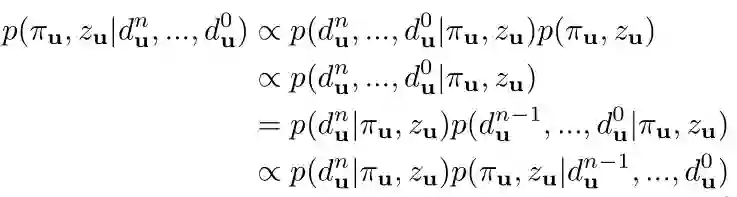
与SVO和REMODE一样,为了概率推断我们将这个概率近似为一个高斯分布与Beta分布的乘积:

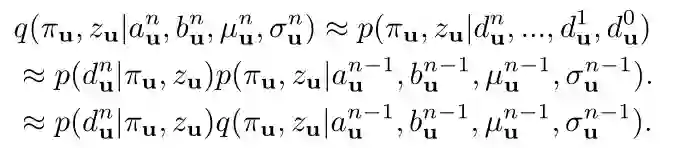
我们推荐从REMODE中阅读更多的详细内容。
2) 递归的估计:这里与SVO和REMODE相反,使用了时域与空域上的关系。具体的内容见图1。
1.3 不确定性感知深度集成
为了建立紧凑、密集的三维模型,我们采用体素融合的思想来整合前一小节中得到的所有深度估计。它们促使我们显式地建模前一小节中每个深度估计的较早概率,并在深度集成步骤中考虑离群值。
我们将世界描述为3D的体素,每一个体素连接着一个有符号的距离函数SDF和一个权重函数W。SDF表示了x与最近的物体表面的有符号距离,W表示了SDF函数的置信度。如文[23]所示,对随时间变化的距离测量进行平均,对于SDF的零等值面,使得到所有射线端点的平方距离的加权和最小。
由于3D世界的主要部分通常是空的,所以我们使用哈希表来索引体素,并且只存储靠近对象表面的SDF及其权重。这些SDFs被称为截断符号距离函数TSDF:
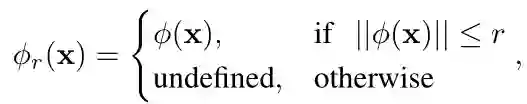

1) TSDF更新:
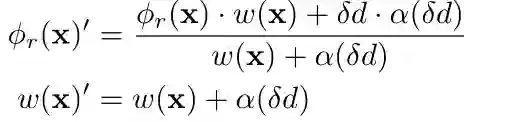
2) 不确定性感知光线追踪:
连通区域中的体素会被扔掉,该操作可以被视为通过可见性约束(即,射线的两个端点之间的段是空的)去除潜在的深度异常值。这之所以有意义,是因为我们更关心场景的哪个部分不包含表面(用于运动规划),而不是对象内部的内容。
虽然体素对于运动规划来说已经足够了,但是颜色和纹理更适合于可视化和调试。我们包含一个可选的步骤,进行立方化,从三维离散标量场中提取等值面的多边形网格。
主要结果
实验基于联想Y50笔记本,拥有一个i7-4720HQ的CPU和GTX-960M的GPU。深度估计模块运行在GPU上,深度假设和不确定性感知都运行在CPU上。
4.1 数据集结果
在这两个数据集验证了我们单目深度估计器的建图性能。我们使用了真实的相机位姿作为输入,并且选用了一些典型序列(表1)作为建图的评估。并且我们使用了三个度量的方法:平均的深度计算时间(ms),平均的深度估计稠密度(%)与深度的错误百分比(%)。
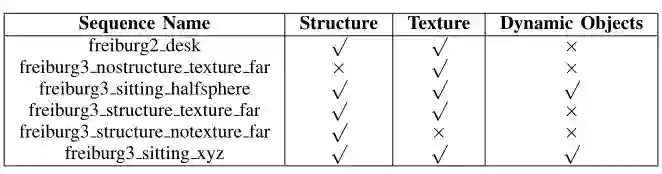
表1 TUM数据集特征分类
由于两个数据集上的图像分辨率都是类似的,因此我们直接在上面计算平均的所用时间。结果如表2所示:

表2 各个方法的平均计算时间
建图的稠密的度量结果如图3,对于REMODE,只有收敛的深度用于了度量。

图3 各个方法的建图稠密度
在不同数据集上各个方法的正确率如图4图5所示:
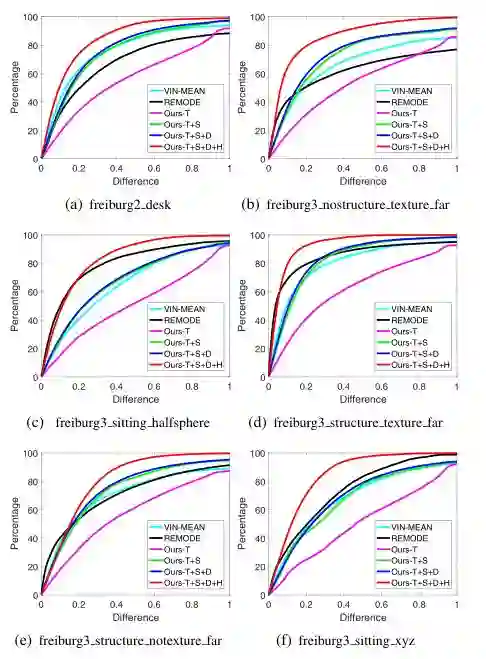
图4 TUM RGB-D数据集结果
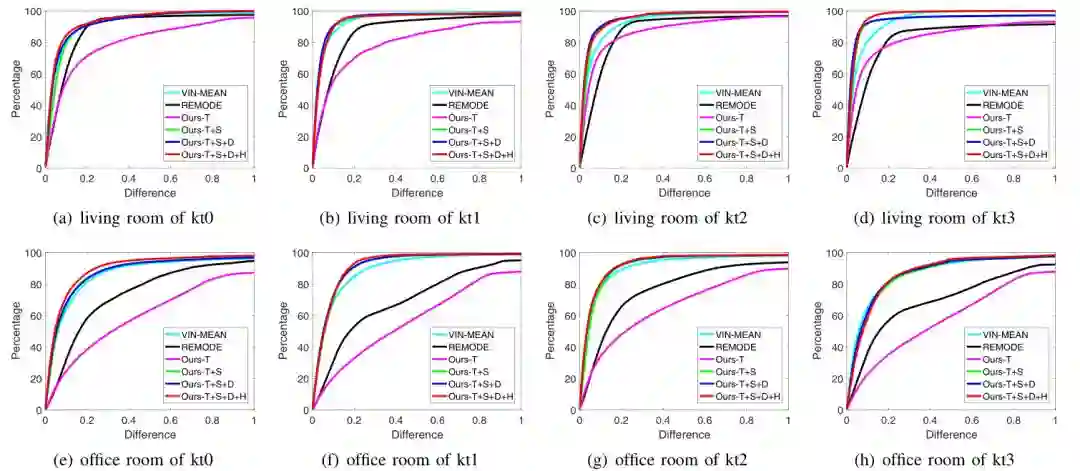
图5 ICL-NUIM数据集结果
我们另外还选择了一张来自TUM数据集的图像展示了深度估计的结果,如图6:

图6 不同方法深度估计的实际截图
我们首先分析不同的组件对我们的方法的影响。时域损失的聚合步骤是最耗时的步骤。它是所有后续计算的基础。在时域损失聚合之后,一个赢者通吃的策略可以获得超过60%的建图密度,但对应的精度非常低。空域调整的步骤利用相邻深度估计的空间相关性,不仅提高了建图的密度,而且提高了精度。局部区域决策步骤通过拒绝不可靠的深度估计而略微降低了地图密度,深度细化步骤略微提高了地图精度。最后一步,假设滤波,以降低地图密度为代价,极大地提高了建图的精度。假设滤波策略明确地利用了连续深度估计的时间和空间相关性。一致的深度值被改善,而不一致的被移除。

Abstract
This paper presents a probabilistic approach for online dense reconstruction using a single monocular camera moving through the environment. Compared to spatial stereo, depth estimation from motion stereo is challenging due to insufficient parallaxes, visual scale changes, pose errors, etc. We utilize both the spatial and temporal correlations of consecutive depth estimates to increase the robustness and accuracy of monocular depth estimation. An online, recursive, probabilistic scheme to compute depth estimates, with corresponding covariances and inlier probability expectations, is proposed in this work. We integrate the obtained depth hypotheses into dense 3D models in an uncertainty-aware way. We show the effectiveness and efficiency of our proposed approach by comparing it with state-of-the-art methods in the TUM RGB-D SLAM & ICL-NUIM dataset. Online indoor and outdoor experiments are also presented for performance demonstration.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



