【泡泡一分钟】泡泡一分钟一周总结(20181008-20181014)
每天一分钟,带你读遍机器人顶级会议文章
来源:International Conference on Computer Vision (ICCV 2017)
播音员:水蘸墨
汇总:陈世浪,颜青松
编译:泡泡一分钟全体组员
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

2018年10月8日至2018年10月14日,泡泡一分钟共推送了14篇文章,其内容涉及到立体视觉(8篇)、语义分割(2篇)、场景定位(2篇)、图像测量(1篇)和特殊场景理解(1篇)等。
立体视觉是本周的重点,总推送8篇文章。
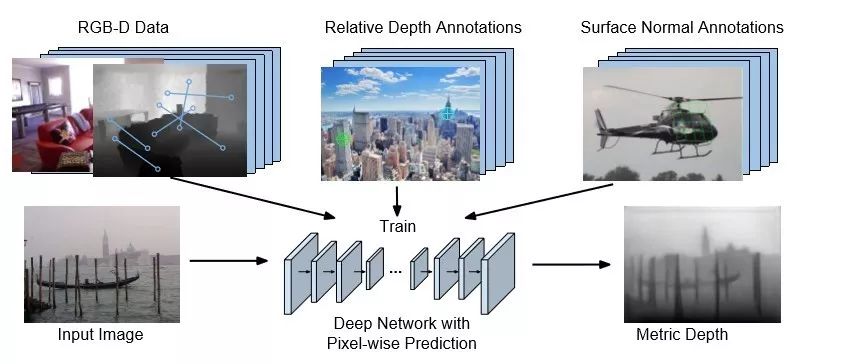
在单幅图像上,介绍了端到端估计4D RGBD光场和利用物体表面法向量提升深度估计的方法。

学习从单个图像合成4D RGBD光场
自然中的表面法向量
在双目上,有三篇文章各自介绍了如何利用非监督或若监督的方法来解决双目GroundTruth数据较少的问题。

无监督学习的立体匹配方法
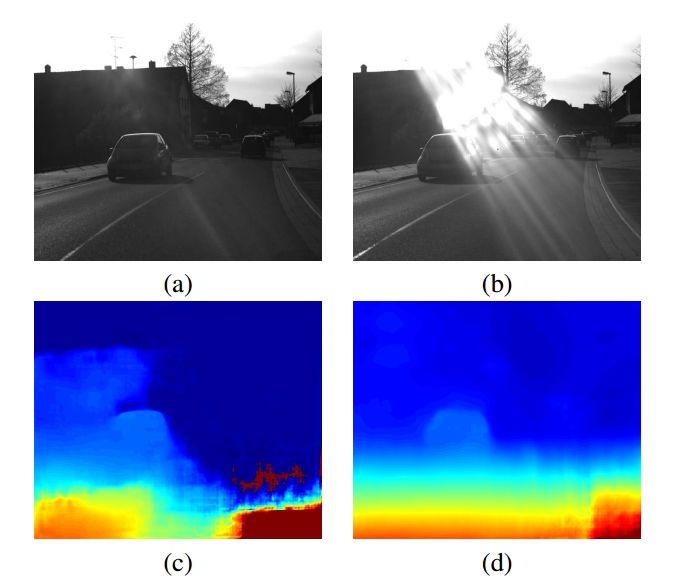
用于深度双目的非监督适应方法

用于双目视觉重建的弱监督深度度量学习方法
在多目上,有一篇文章介绍了如何利用深度学习进行多视图相似度计算,另外两篇文章则主要介绍如何进行端到端的输出三维重建结果。
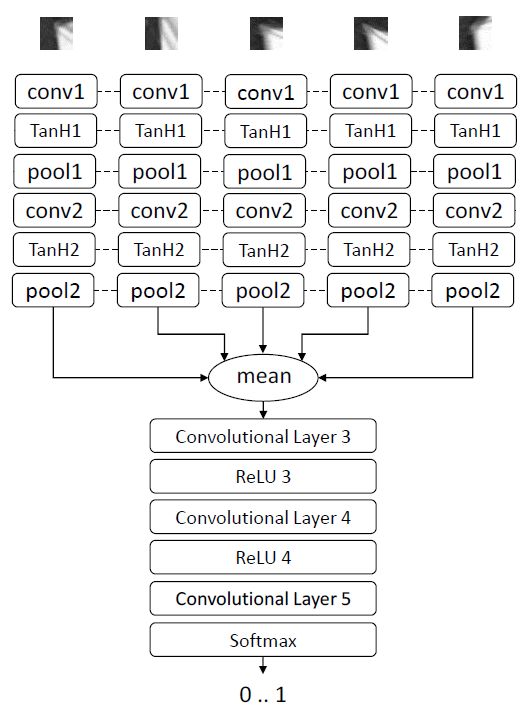
学习多视图相似度
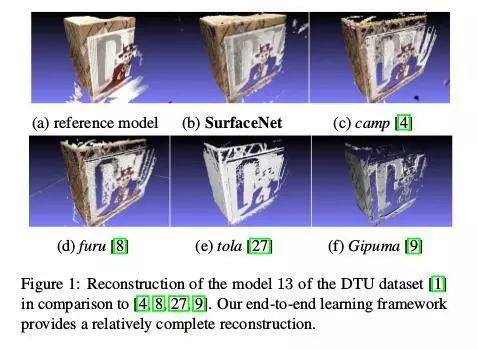
SurfaceNet:一种端到端的3D多视立体视觉神经网络
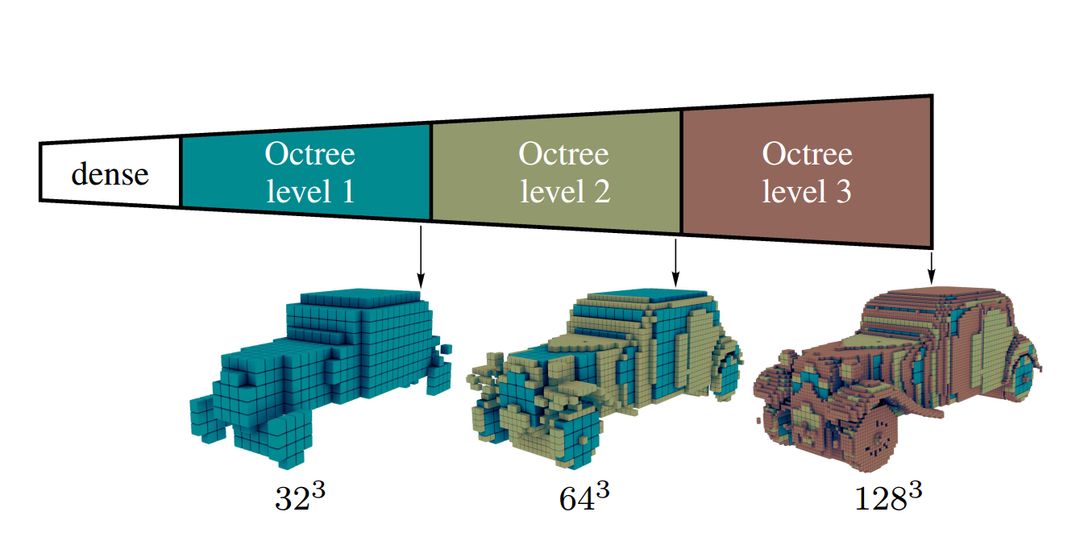
八叉树生成网络:用于高分辨率3D输出的高效卷积架构
语义分割
语义分割本周共两篇文章,第一篇介绍了基于RGB-D的语义分割,充分利用深度信息来提高语义分割的性能;另一篇文章则介绍了如何将道路语义分割模型进行城市级迁移,从而减少人工标注。
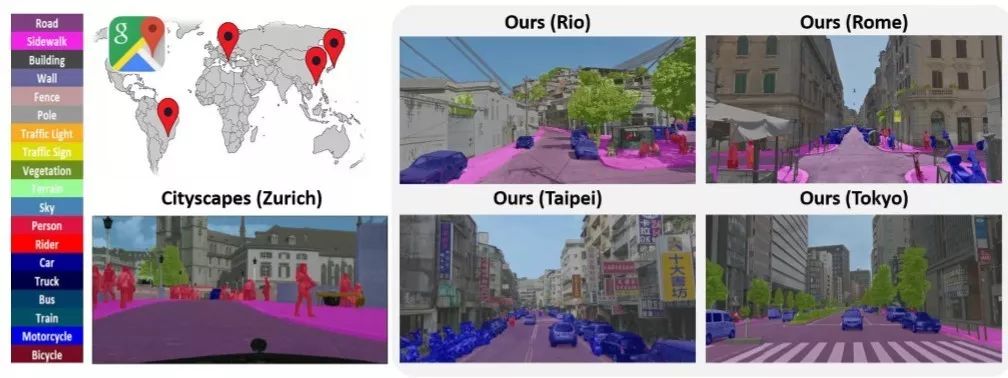
不再区分:道路场景分割器的跨城市适应

基于级联特征网络的RBG-D图像语义分割
场景定位
场景定位本周介绍了SSD-6D和ChromaTag。SSD-6D扩展了传统SSD,使其能够进行三维实例检测并估计物体位姿信息。ChromaTag的核心在于引入了颜色信息,提高了靶标的检测速度,更加利于实时检测。

SSD6D:基于RGB的三维检测和6自由度位姿估计
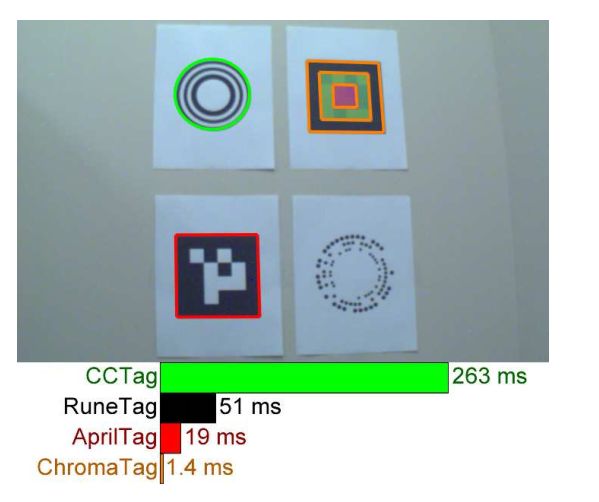
ChromaTag:彩色靶标及其快速检测
图像测量
图像测量方面,本周介绍的是基于复合焦点的测量方法,换句话说即使用同一个镜头在不同的焦距下对场景进行拍摄,最后再利用这些图像进行深度测量。
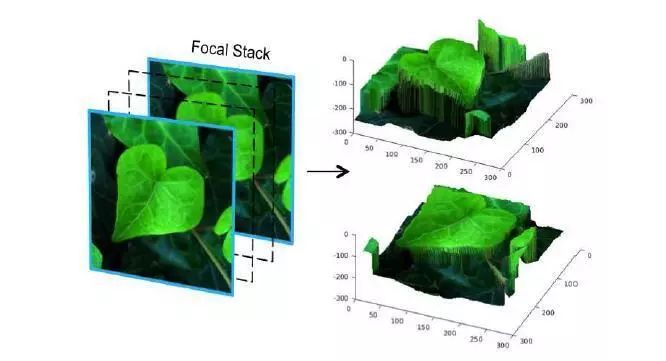
高质量深度图的复合焦点测量
特殊场景理解
特殊场景理解本周介绍的是针对容器中液体的理解。众所周知人类对容器中液体含量和液体类型有非常丰富的经验;但目前该方面的研究非常薄弱,因此学者们专门设计了数据集并进行了一次尝试,取得了非常不错的实验效果。

一种计算液体容器的体积和理解其内容物的方法

如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




