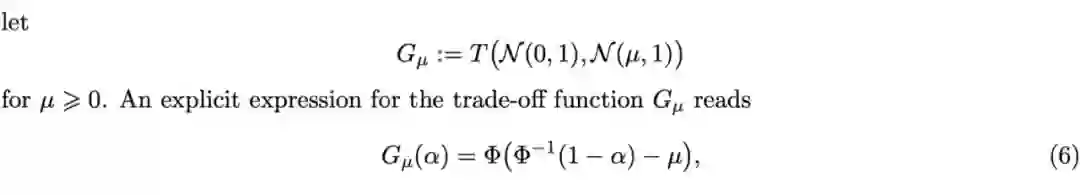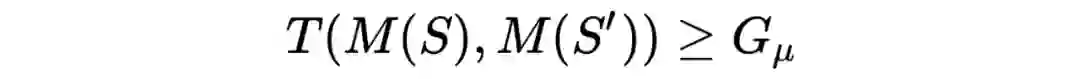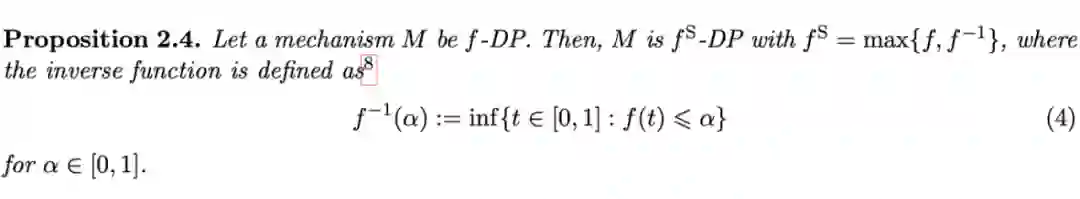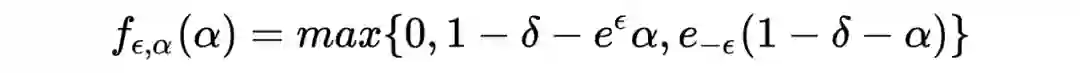©作者 | 李轩宇
单位 | 中国科学院大学博士生
研究方向 | 机器学习
统计视角下的差分隐私
最近在学习统计领域内的差分隐私,一个人只是读论文看资料难免会在细节上有些疏漏,遂决定整理总结自己所看的一些经典或者优秀的论文,把它们做成读书笔记,既巩固自己的知识,也可以服务想要快速了解差分隐私的同学。如果有什么错误或者不严谨,还请多多指教。
差分隐私的概念最早是由 Dwork 在 2006 年的一篇论文中提出来的,Dwork 是一位计算机科学家,在提出 Differential Privacy 的时候也有很多计算机 domain 的考量,但是由于最终的定义是要引入概率的视角,所以在统计的领域内也有学者对这个话题进行研究。而作为一个统计的学生,也应当更多的站在统计的视角去看隐私保护这个 topic,所以我读的文章基本都是在统计的杂志上发表的。
在写文章的时候,我也会把计算机的术语全部转换到统计的语言里。
1.1 背景 Setting
考量这样的一个场景,有一个数据库,它存储了包括你在内一个班 n 个人的家庭年收入信息,这 n 个数据总体记为 D,并且提供数据总体的统计量查询服务,之所以要这样做而不是直接提供所有个人数据是为了保护个人的信息隐私。
你是个转学生,在你来到这个班级之后恰好又离开了一位学生。
而刚在你来之前,那时候的数据总体
也有 n 个人的信息,不过相比于现在的 D,有一位同学和你是分别不属于对方的数据集的。
在你来之前,曾有人查询过数据库的平均值统计量
,在你来后,他为了更新信息,再次查询了你们班的平均值统计量得到了
,通过两次查询的结果相减,他会得到你和离开同学的家庭收入差,也就是
,如果他还知道那位同学的家庭收入信息,那么你的收入信息便遭到了泄露。
1.2 隐私保护方案
那么在这个时候,就需要有一种手段,使得对两个有一个个体差异的数据集,查询关于总体的统计量时不会造成个体信息的泄露,不过,绝对的隐私保护(也就是说完全不泄露任何隐私)最后只能带来无法提供任何信息的查询结果。
所以解决方案就变成了在一定的隐私权限下,如何发布统计量使得个人信息最少程
在引入正式的定义之前,我想先介绍一篇很早的有关统计学家研究保护隐私的文章。
1.3 历史方案
在 1965 年的时候,JASA 上刊登了 Warner 的一篇如何收集可以保护数据隐私的工作,作者指出,在调查中总是存在回避型误差 Invasive Bias,原因是有些问题涉及个人隐私,被访者可能由于安全考虑会错填回答,比如调查高中生是否吸烟。
那么 Warner 的做法就是提供被访者一个指针,它有 p 的概率指向是,有 1-p 的概率指向否,在一个受访者接受敏感问题的回答的时候,他首先需要拨动指针,然后再不告诉调查者指针的指向情况下,回答指针的随机预测是否符合自己的情况就可以了。
该方法之所以可以有效保护隐私是因为就算调查者知道指针的指向概率,只要这个 p 不等于 0 或者 1,我们无法从他的回答中肯定他的真实情况, 比如 p 为 0.9,他回答了符合情况,我们也不能肯定是否他的回答一定是‘是’,因为还是有 0.1 的可能指针是指向了否,而他的情况是'否'的,但是我们知道他大概率是'是',从而可以利用这个信息进行进一步的统计推断,值得注意的是,在 p 为 0.5 的时候,此时收集到的信息将没有任何意义。
Warner 开创性的提出了该方法,也在论文中证明了改方法收集到的数据的统计性质。
从本质上,Warner 的方法其实是在给一个 0、1 变量添加噪声,Warner考虑了一个 01 分布的随机变量的情况,事实上也很容易将其推广到连续变量之上。至此,一个最 intuitive 的差分隐私保护方法已然呈现在我们眼前,就是要将原本 deterministic 的查询结果添加一个随机化的噪声,这样哪怕知道了噪声的分布,也无法确切知道个体的信息,从而达到保护作用。
对于个体的信息发布,该方法已然可以保护隐私,事实上,这种针对个体数据直接发布的保护方法称为 local privacy,而要将它推广到多个个体组成的总体也是不难的,这就是差分隐私的保护机制中最常用的方法——添加随机噪声,下面可以引出 Differential Privacy 的正式概念:
1.4 Differential Privacy 对一个统计量 M,我们定义其具有
限度的差分隐私保护机制如下:
对任意相差一个个体的两个数据集
、
,以及任何的
都有
考虑特殊情况
,此时称 M 具有
限度的差分隐私保护机制。
1.5 统计推断视角下的隐私保护机制
在 Larry Wasserman 与合作者 Shuheng Zhou 2010 年发表于 JASA 上的论文中,他们指出,隐私保护的定义事实上等价于一个假设检验的检验力度(power)。
▲ 定理
从差分隐私到假设检验以及Neyman-Pearson引理
在开始证明这个定理前,先简要的引入必要的数理统计知识。
2.1 数理统计
2.2 假设检验以及检验水平
我们知道假设检验的 setting 是,我们拿到了一批数据(比如说是一维的特征,n 个样本)
,我们想要知道 X 的分布,这时候会提供两个假设
以及
,分别代表原假设(Null Hypothesis)以及备择假设(Alternative Hypothesis),分别代表两种分布
以及
,我们的目的是给出一种判别准则
,来对
属于哪一个分布做一个判断,一般的,我们记
为拒绝原假设
选择备择假设
,记
为接受原假设
,如此一来,由于 X 是随机的,所以相应的,
也是随机的,是一个服从 0 1 分布的随机变量,具体的例子可以在任何一本数理统计书中找到,这里我们只是做一个抽象的总结。
检验水平便可以由下面的方式定义:
若对服从
分布的
,我们有
,则称一个检验统计量
检验水平为
。
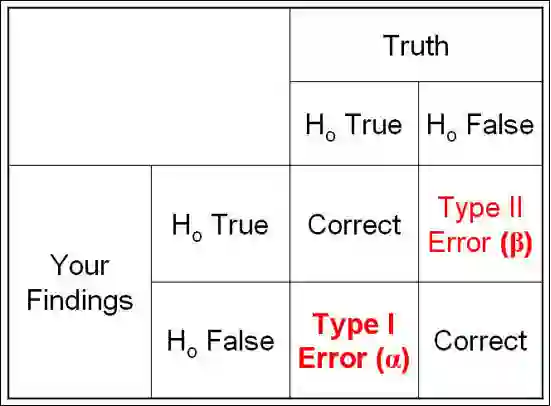
2.3 统计效力(test power)
一种是
服从
时我们错误的拒绝了
,这种错误被称为第一类错误,第一类错误发生的概率为
。
一种是
服从
时我们错误的接受了
,该错误被称为第二种错误,第二类错误发生的概率为
。
▲ 两类错误
在假设检验中,我们的目的是尽可能做出正确的推断,这需要我们选择一个好的检验方法,也就是检验统计量
,但如何衡量检验统计量的好坏呢。
直觉上,一个好的检验方法两种类型的错误概率都很小,但是,可以证明,我们无法让两种错误概率同时变小,所以我们合理比较不同检验统计方法好坏的方法便是在固定第一类错误的前提下,尽可能的减小第二类错误的概率。这就引入了统计效力。
统计效力的定义为在
服从
的分布,且检验水平为
的时候,我们拒绝原假设的概率,即当
的时候,下式的概率:
。
可见,统计效力是与
的取值有关的,在固定了
的情况下,统计效力越高,则检验统计量越好。
2.4 Neyman-Pearson 引理
现如今本科数理统计课本里的绝大多数知识都是来自于 Fisher, Neyman 以及 Pearson 父子四大天王在 20 世纪初开创统计学时的工作。现在要介绍的这个引理也是由其中的两位大牛做出的工作。
考虑
为
的原假设,而
为
的备择假设。我们可以用
来表示第一类和第二类错误的概率。
令
,
分别为
以及
的概率密度函数,我们定义如下的 Neyman-Pearson 检验:
Neyman-Pearson 引理证明了该 Neyman-Pearson 检验是最好的检验函数(在同等检验水平下,检验效力最高),而且有下面的不等式:
2.4.1 Proof of Neyman-Pearson Lemma
另外,如果要寻找在给定检验水平
下的最优检验统计量,我们需要选取合适的 c 使得
的第一类错误概率等于
。
2.5 从统计效力看差分隐私 2.6 Setting
现在有了上述的引理和知识,我们可以对原来的定理进行阐述。
P 是 X 的数据分布,
是一个隐私保护的生成机制,Z 是由该机制生成的查询统计量。
也就是说
是一个有关于
的分布,那么我们要检验的原假设和备择假设就是
以及
。
该定理说明:在差分隐私机制
服从
限度的差分隐私保护限度时,我们关于这个假设的
水平的假设检验统计效力不超过
。
事实上,由于之前所说
是一个有关于
的分布,所以该假设其实是关于
分布的假设。
现在我们可以利用上面所补充的知识,对该定理进行证明:
2.7 Proof of Theory w.l.o.g(不失一般性)令
记
其中,
可以理解为一个区间或者 Borel 集,由 Neyman-Pearson 引理,在检验水平为
的情况下,我们用该引理找到最好的检验统计量: 我们回忆一下差分隐私的定义:
对一个统计量
,我们定义其具有
限度的差分隐私保护机制如果:
对任意相差一个个体的两个数据集
、
,以及任何的
都有
在这里
,
就是
,其中
,所以应用定义,我们有
由此我们证明了相较于原论文更为一般的
形式的差分隐私的假设检验等价形式(当然这个推广很 trivial)。
想要理解这个定理,不妨这样看:当
都比较小,甚至为 0 的时候,统计效力几乎甚至直接等于检验水平,此时,如果我们每次不管数据长什么样而是直接以检验水平的概率拒绝原假设,那么此时的统计效力也是基本等于我们利用了数据得到的最好的检验的统计效力的,因此,这说明此时我们没有什么好的检验方法,因为最好的方法也和我们不看数据乱猜差不多。换句话说,当隐私保护的力度很大的时候,假设检验的困难很大。
2.8 结语
至此,我们通过该定理完成了从差分隐私到假设检验的顺利过渡,在此之后便可以进一步深入,去探索在统计的框架内差分隐私的发展。
Gaussian Differential Privacy (f-DP) - 定义以及基本性质 3.1 前言
在上文中,我介绍了差分隐私的基本概念以及其与统计学中的假设检验的联系,而接下来我想写写最近读的苏炜杰老师在 2019 年与其合作者 Jinshuo Dong 和 Aaron Roth 在此基础上更进一步的工作,该工作于 2021 年发表在Jrrsb上,YouTube 上可以查到 rss 公布的 paper discussion 视频,这篇文章一共约 30 页,内容涵盖众多,所以我想分两节来对这篇文章的内容进行介绍,当然,太过详细的述说就不免失去了我写这篇读书笔记的意义了,所以我会尽量精简的对该文章进行说明与介绍,希望可以使得读者对文章的主要思想有所了解,感兴趣的话去阅读原文就更好啦。
在第一节中,我打算先介绍 Gaussian Differential Privacy 这篇文章给出的新定义以及该定义所具备的基础性质,而在第二节中,我会给出该定义所具备的更多超越其他隐私度量的优良性质。
3.2 定义
3.2.1 基于假设检验的视角看差分隐私 前面的笔记已经证明,满足
的差分隐私保护机制是可以推导出任意两个相邻数据集(相差一个单一个体)的假设检验效力函数上界的,那么该文章的想法很 intuitive,为什么不直接用任意两个相邻数据集的假设检验难度来定义差分隐私呢?那么首先,我们需要给出假设检验难度的一个衡量。 3.2.2 Trade-off 函数
trade-off 的意思就是两个事物有某种权衡,此消彼长。
该函数用简单的语言来理解就是在第一类错误固定为 x 的时候,将第二类错误的误差下确界作为 y。
可以证明的是,一个定义域和值域都在 01 区间的函数如果拥有凸性,连续性,单调下降以及被 1-x 上 bound 的性质的话,等价于该函数就是一个 Trade-off 函数。
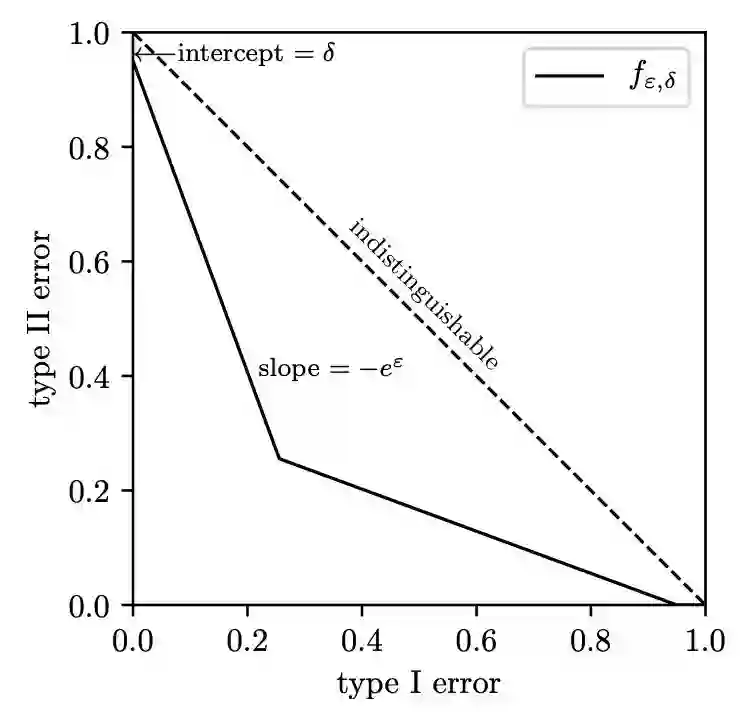
▲ 定义
我们称一个满足上述条件的算法为满足 f-DP 隐私保护的算法,也就是说,f-DP 给出了关于任意两个相邻数据集的 trade-off 函数的下界,其实本质上就是用假设检验的难度来衡量隐私的保护力度。
3.2.4 特殊的trade-off函数 -- Gaussian Differential Privacy
前面说过,trade-off 函数是由两个分布检验难度得到的,那么有没有比较特殊的 trade-off 函数呢?也就是说有没有特殊的两个分布,他们的 trade-off 函数具有非常重要的地位呢?
这里解释一下什么叫做’地位‘,在一个数学体系中,如果一个东西非常常见,可以与这个体系中的其他概念产生广泛的联系,那么称这个东西的地位很高。比如说在离散型随机变量的分布中,01 分布是最重要的,因为所有的离散型随机变量都可以表示成它的线性组合。在连续型随机变量中,正态分布是最重要的,因为中心极限定理的存在,所有的随机变量都可以用一定的方式逼近它。
这篇文章指出,对于这样一类由两个正态分布所得到的 trade-off 函数,它具有非常重要的地位。当然这就涉及到第二篇读书笔记要讲的东西了,我们这里先暂且承认这件事。作者给出了该 trade-of f函数的显式表达。
至此,终于出现了该文章的标题所说的术语- guassian differential privacy 的定义了:
3.3 性质
3.3.1 对称性
对称性其实很容易用直觉感受,因为 trade-off 函数的两个数据集是可以互换位置的,所以最后得出的下界一定是一个对称的函数。 3.3.2 与
-DP 的关系
我们定义一类特殊的 trade-off 函数族:
如下图实线所示
那么可以证明如下性质
▲ 关系
也就是说,其实
差分隐私保护机制是一种特殊形式的 f-DP 机制。
3.3.3 后处理以及信息充分性(Post-Processing and the Informativeness)
后处理性质是 dwork 提出来的
-DP 的优良性质,直观上,如果我们发布了一个具有某种隐私保护程度的统计量,那么如果这个统计量被一个函数(可以是随机的)处理后,新统计量的隐私保护程度不应该比原来的统计量隐私保护程度低。同样的 f-DP 也是具备该性质的,数学语言表述如下:
后处理性质:
定义
为一个随机化的映射,将统计量
映射到一个新统计量,则如果M满足
,则
也是满足
的。 3.3.4 Primal-Dual:f-DP与
-DP的相互转换
3.3.4.1 Primal-Dual
Primal-Dual 在凸分析中是一个重要的话题,学过凸分析的话就会接触这个内容,感兴趣的话可以自行翻阅相关书籍讲义,在这里我们不对优化中的 Primal-Dual 进行过多介绍,简单来说,duality 就是对一个原问题(比如说最优化问题)找到一个对偶问题,二者的最值有一定的关系,在某些情况下是相等的,所以 duality可以说是找到一个问题的另一种视角。
在这篇文章中,作者引用 Primal-Dual 这个术语是想类比 f-DP 与
-DP 之间的关系。具体来说,将 f-DP 视为原始问题,将一组
-DP 视为对偶问题。
3.3.4.2 Dual to Primal
也就是说从
-DP到 f-DP:
记 I 为指标集,则一个统计量对所有
都满足
-DP 等价于该统计量是如下定义的 f-DP:
。
3.3.4.3 Primal to Dual
反过来也是可以的,假如一个统计量是 f-DP 的,那么等价于它对所有的
是满足
的。 3.4 结语
至此我们完成了 f-DP 基本定义以及基础性质的介绍,我们也知道了标题中的 Gaussian Differential Privacy 的具体含义,而且可以看到 f-DP 与
-DP 也是有诸多关系的,这在后面的优良性质推导中会起到重要作用,在接下来的笔记中,我会对 f-DP 所具备的超越其他隐私定义(比如 renyi-DP,
-DP)的地方进行阐述。
Gaussian Differential Privacy - 中心地位及优良性质
我介绍了由苏炜杰老师及合作者所提出来的 f-DP 和 GDP 的定义和基本性质,在这篇文章中,我会先简要介绍当然包括经典的
-DP 定义在内的差分隐私定义,然后聚焦于 GDP 优于其他隐私刻画方式的优良性质,介绍其在复合情形下的隐私保护的优良刻画性质。
由于 f-DP 使用函数来对隐私机制进行量化,相比于只使用两个参数的
隐私保护机制,函数的无限参数使得 f-DP 可以对隐私的度量更加准确。
在举例子之前,这里要给出在
-DP 的框架下保护隐私的具体方式。
第一节中说到在目前的研究中,针对一个统计量,普遍采用的保护隐私的方法是在发布该统计量之前,对其添加一定量的随机噪声 ,下面的定理就给出了如何对一个统计量
添加噪声,使得最后释放的统计量
是满足
-DP 的:
也就是说敏感度反应了两个相邻数据集统计量的最大差异值 。
定理2 添加 Gauss 噪声的
-DP(Dwork 的经典定理)
分析:从参数的外观上,不难发现,第一个定理的参数还算比较自然,但第二个定理的参数就非常不自然,事实上,这是由于第二个定理的证明应用到一些尾概率不等式,而且放缩并不是那么严格和苛刻的,所以这里加入的噪声其实是比较‘大’的,换句话说,在达到要求的
-DP 的前提下,是可以加入比该定理方差更小的正态分布噪声的,那么具体最精确能加多少呢?后续的文献 [9] 中对该问题进行了探讨,篇幅问题,这里只列出结论:
对一个统计量
,
,其中 N 是正态分布,则
是符合
-DP 的统计量只需要:
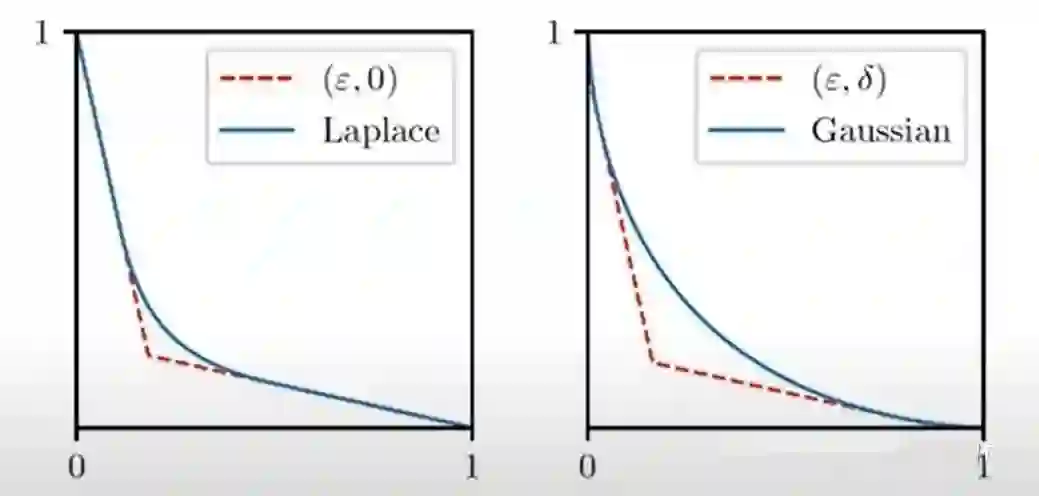
光是看这些,可能会觉得头疼,但是接下来,在 f-DP 的框架下,我们可以直观的看到这三个定理给出的 trade-off 曲线对比。
这里借用 [8] 苏炜杰老师在 Online Discussion 的图:
▲ Laplace 机制和 Gauss 机制的 Trade-off 函数
从第一张图的示意可以看出,在添加 Laplace 噪声的时候,其 trade-off 函数正好能和某个
函数相切,所以定理 1 的结果不算难看,左图的蓝色曲线就是 Laplace 噪声后的 trade-off 函数,但到了 gauss 噪声的时候,在两个端点(0,1)和(1,0)处的斜率都是坐标轴方向,所以不可能得到
形式的 DP 机制,但是如果允许截距的存在,则就可以被
函数相切了。在右边的图中,刚好相切的蓝线就是由定理 3 的解析解所表示的,如果使用定理 2,则最终的线其实是在图中蓝线之上的。
Concentrated Differential Privacy
需要用到一些次高斯和 Divergence 的知识,由于篇幅问题,给出原论文 [11] 供查阅。
R´enyi differential privacy
R´enyi Divergence 是一种特殊的Divergence:
对两个概率分布 P 和 Q,order 为
的 R´enyi Divergence 定义为:
称一个统计量
具有 R´enyi-DP 当且仅当对任意相邻的数据集
和
:
Truncated concentrated differential privacy
Concentrated Differential Privacy 的推广,篇幅原因这里只给出原文献 [12]。
4.3 复合隐私保护
复合隐私保护考虑数据分析者对同一个数据集多次进行分析的情况,这其中的问题在于如何衡量在多次在保护隐私地查询(释放统计量)后,一个数据集隐私保护力度的变化情况。我们称这种情况为复合后的差分隐私。
记
为数据集,令
为释放的第一个统计量,
为释放的第二个统计量,依次定义
,我们定义这 n 个统计量的复合为:
为了后续结论,现在定义两个 trade-off 函数的张量积为:
令
对
满足
-DP,则 n 次复合统计量
是满足
-DP 的。
一般来说,两个 trade-off 函数的张量积的解析表达是复杂的。
n 次
-GDP 的复合统计量是符合
-GDP 的。
不过,这还没有奠定 GD P在 f-DP 中的核心地位,如下的中心极限定理表明了 GDP 的核心地位。
令
为一列 trade-off 函数,对
,
,当
的时候:
这个定理说明:当每次的隐私保护力度都很小的时候,最终的隐私保护力度会趋于一个 GDP,这也对应着在随机变量中的中心极限定理。
从之前的结论可以看出,在单次的隐私保护下,由于 f-DP 拥有更灵活的参数,所以最终的刻画是十分精准的,而在复合隐私保护的情况下,这种精确性也是更为明显的,这里我们还是举例
-DP(因为好画图直观说明)。
下图红线表明的是在 10 次
-DP 复合后的 trade-off 函数曲线,而蓝线则为使用上述中心极限定理得到的逼近曲线。虚线表示用
-DP 所能达到的最好刻画。
从蓝线和红线的贴近,我们可以看到中心极限定理的强大:它便于粗略计算而且效果很好。
从红线和虚线的空隙,我们可以看到 f-DP 在刻画复合隐私保护时的精准。
当然,如果我们改变
-DP 中的
进行刻画的话是会有不一样的效果的,但是此时也还是会和真实 trade-off 函数有不小的距离。
在这一节中,我们简介了一些现有的差分隐私保护机制,介绍了具体的添加噪声的算法,最后介绍了复合差分隐私的概念以及 GDP 在复合查分隐私里的重要性。
[1] https://www.ece.rutgers.edu/~asarwate/nips2017/
[2] Wasserman, L., & Zhou, S. (2010). A statistical framework for differential privacy. Journal of the American Statistical Association, 105(489), 375–389. https://doi.org/10.1198/jasa.2009.tm08651
[3] Warner, S. L. (1965). Randomized Response: A Survey Technique for Eliminating Evasive Answer Bias. Journal of the American Statistical Association, 60(309), 63–69. https://doi.org/10.1080/01621459.1965.10480775
[4] Dong, J., Roth, A., & Su, W. J. (2021). Gaussian differential privacy. Journal of the Royal Statistical Society. Series B: Statistical Methodology. https://doi.org/10.1111/rssb.12455
[5] https://www.youtube.com/watch?v=QbMxd0dTexo
[6] Hiriart-Urruty, Jean-Baptiste, and Claude Lemaréchal. Fundamentals of convex analysis. Springer Science & Business Media, 2004.
[7] Dong, J., Roth, A., & Su, W. J. (2021). Gaussian differential privacy. Journal of the Royal Statistical Society. Series B: Statistical Methodology. https://doi.org/10.1111/rssb.12455
[8] https://www.youtube.com/watch?v=QbMxd0dTexo
[9] Balle B, Wang Y X. Improving the gaussian mechanism for differential privacy: Analytical calibration and optimal denoising[C]//International Conference on Machine Learning. PMLR, 2018: 394-403.
[10] Shiva Prasad Kasiviswanathan, Homin K Lee, Kobbi Nissim, Sofya Raskhodnikova, and Adam Smith. What can we learn privately? SIAM Journal on Computing, 40(3):793–826, 2011.
[11] Cynthia Dwork and Guy N Rothblum. Concentrated differential privacy. arXiv preprint arXiv:1603.01887, 2016.
[12] Mark Bun, Cynthia Dwork, Guy N Rothblum, and Thomas Steinke. Composable and versatile privacy via truncated cdp. In Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing, pages 74–86. ACM, 2018.
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧


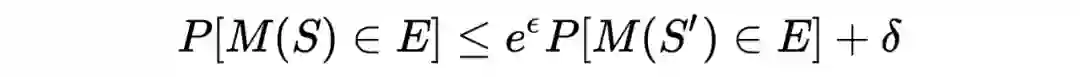


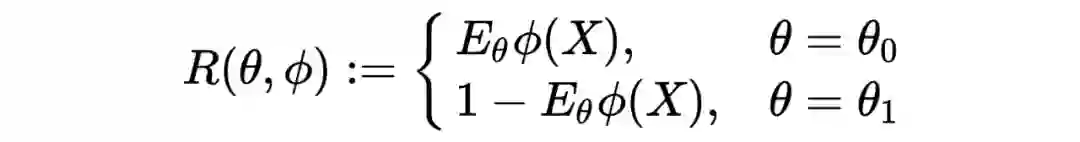
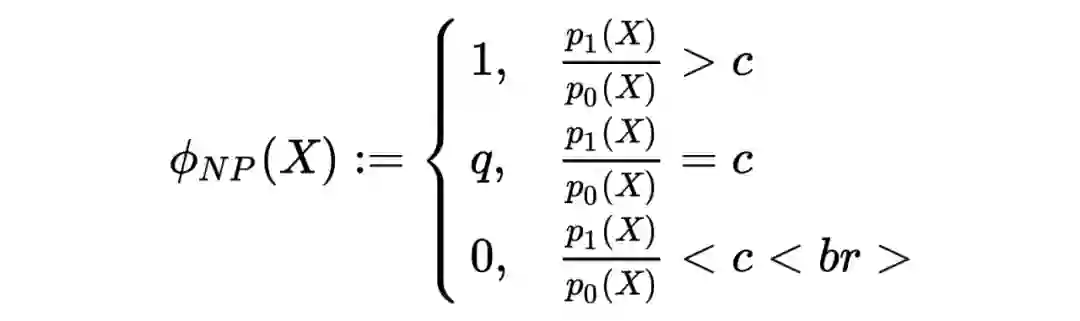
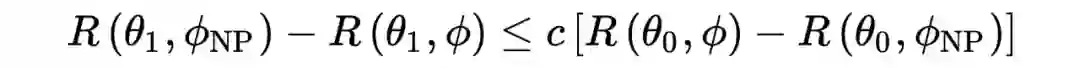
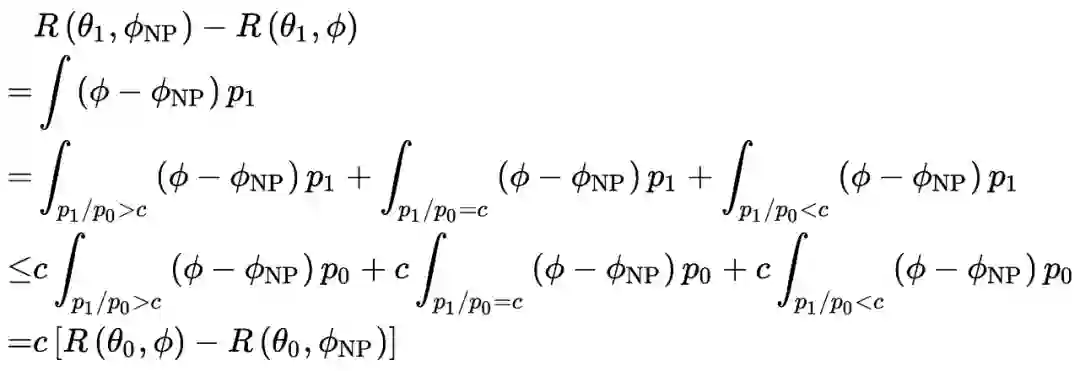
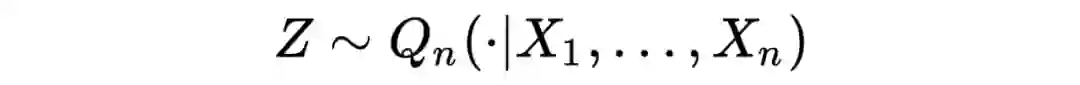
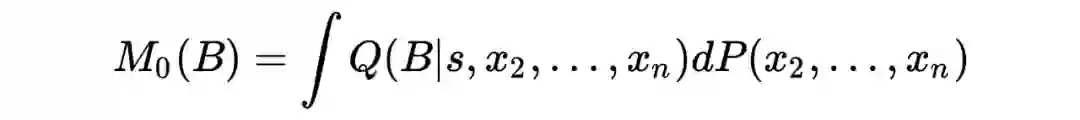
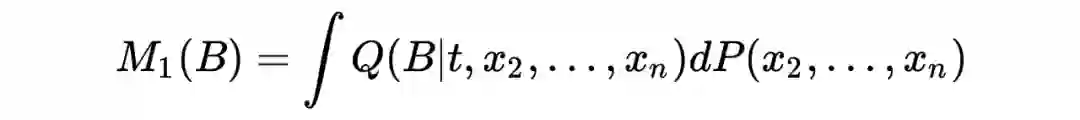
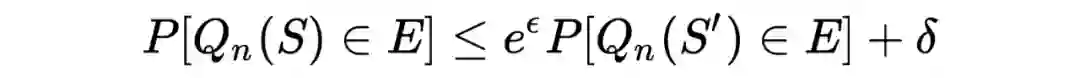
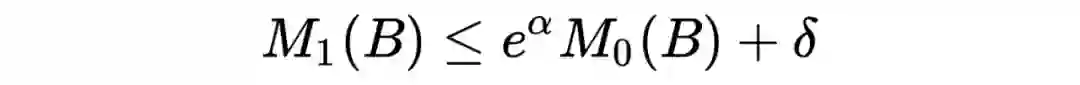
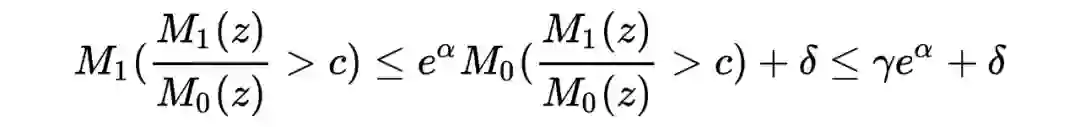


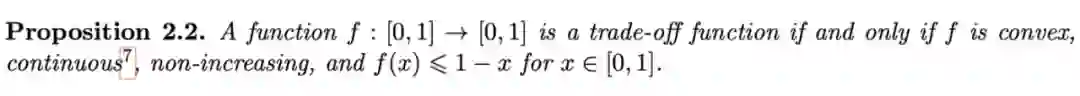
 ▲ 定义
▲ 定义