浅谈数据中的偏差问题和推荐系统去偏最新研究进展

©作者 | 杨晨
来源 | RUC AI Box

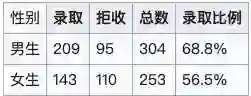
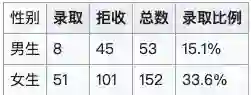
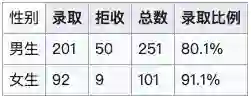

聪明的读者应该能发现,其实本质上没有性别歧视,只是统计数据使得其看起来像是学院招生时对性别有了偏向。进一步分析这个问题,这个现象可以很简单的进行解释,只需要注意到以下两点:
法学院总体录取率低,商学院总体录取率高
报名法学院的女生多,报名商学院的男生多

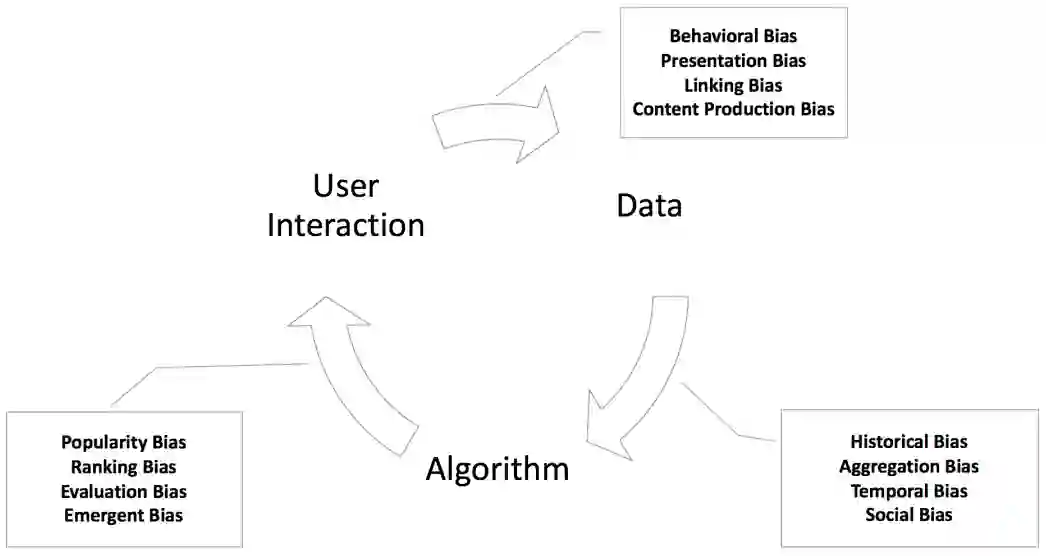

选择偏差:用户的主观选择使数据带有偏向
一致性偏差:用户打分会有从众现象
曝光偏差:未曝光的数据认为不感兴趣
流行度偏差:流行度高的物品越来越流行
公平性问题:对特定群体有偏袒,比如性别
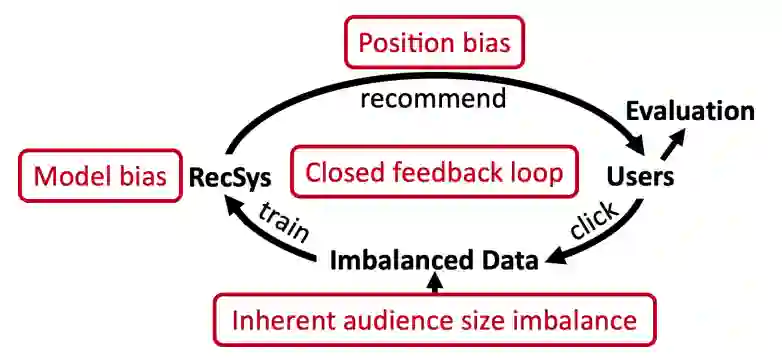
循环偏差:偏差的恶性循环
归纳偏置:模型归纳的经验(不算错误/误差)

推荐曝光的位置有限,曝光哪些商品?
社交平台用户注意力有限,曝光哪些资讯?
打车软件,用户有限,哪些司机接单?
面试机会有限,面试哪些候选人?
其次,推荐偏差是如何引入的?
-
训练数据引入社会偏见
-
模型本身可能会呼应甚至强化数据中的偏差


下面基于最近两年发表在顶级会议(KDD、SIGIR、WWW、AAAI等)的推荐系统去偏的相关论文,介绍部分最新研究工作,简单梳理其背后的技术脉络,也是在上一篇推文的基础上做一个补充和更新。
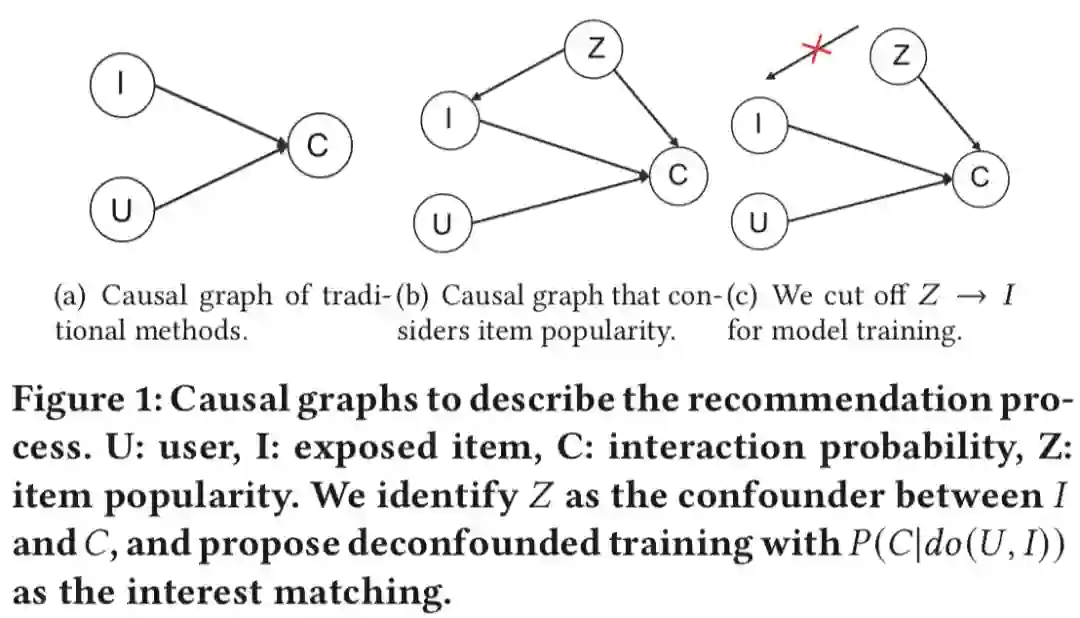
Causal Intervention for Leveraging Popularity Bias in Recommendation. SIGIR 2021
Causal Intervention for Leveraging Popularity Bias in Recommendation. SIGIR 2021
-
训练阶段如何移除流行度偏差的负面影响? -
推理阶段如何利用流行度偏差?
该工作提出了一种新的训练和推理范式,在模型训练时移除混杂的流行度偏差,同时通过因果干预来利用流行度偏差对预测得分进行调整。
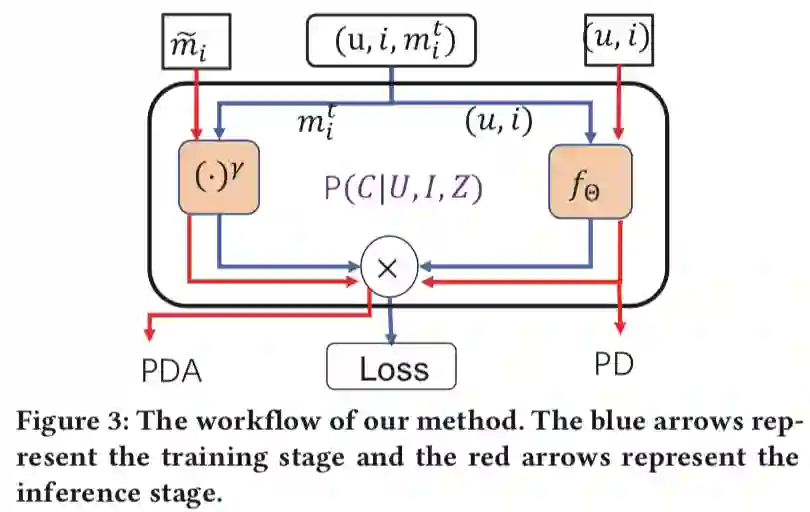
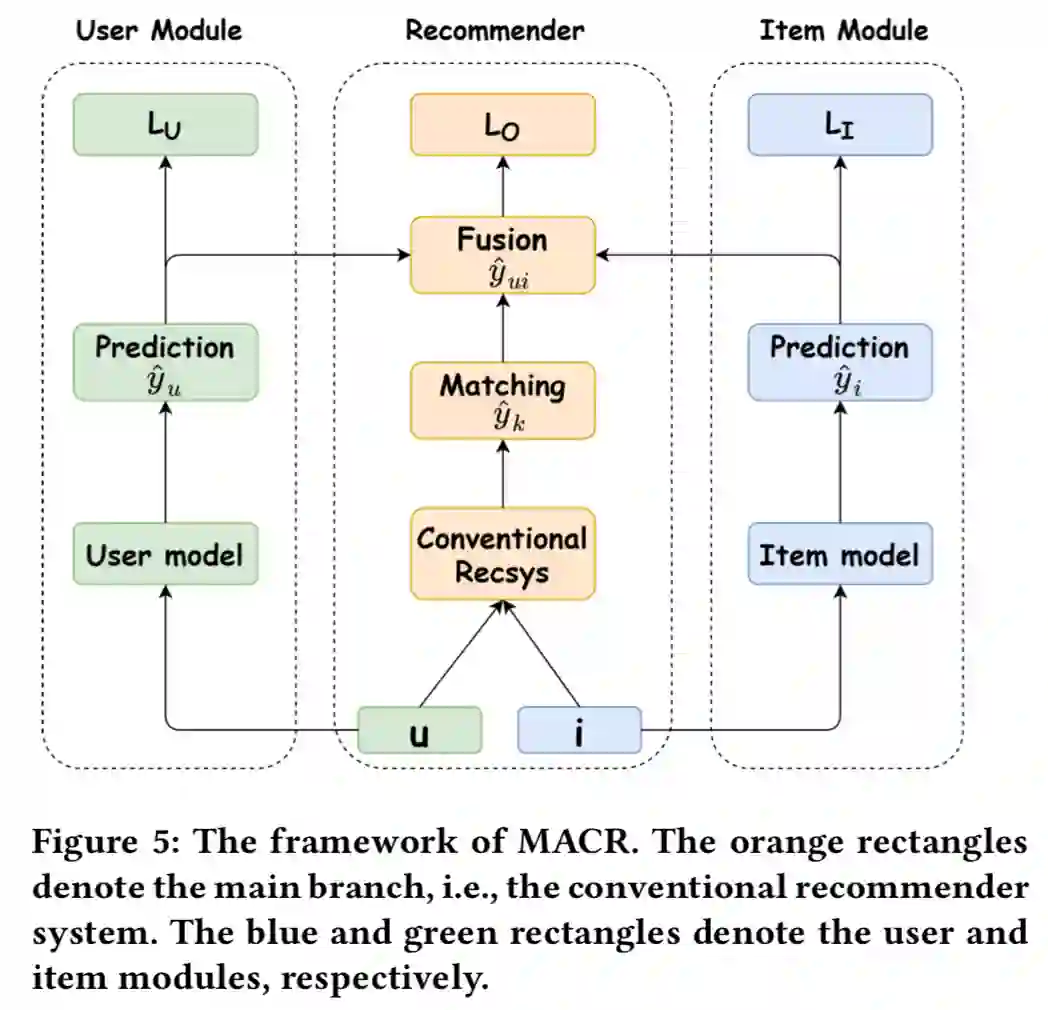
Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in Recommender System. KDD 2021
Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in Recommender System. KDD 2021
关键词:popular bias
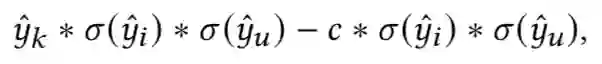
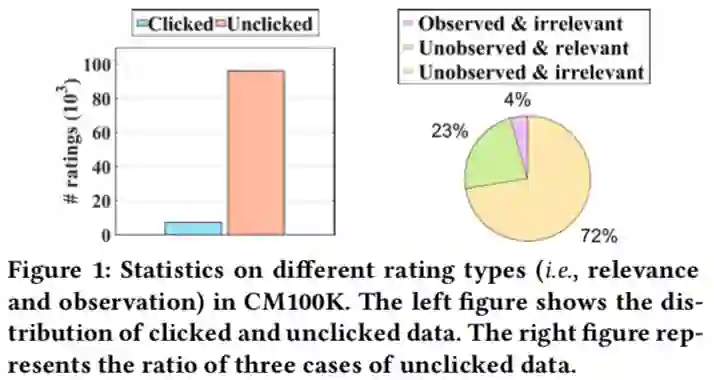
Dual Unbiased Recommender Learning for Implicit Feedback. SIGIR 2021
Dual Unbiased Recommender Learning for Implicit Feedback. SIGIR 2021
关键词:popular bias
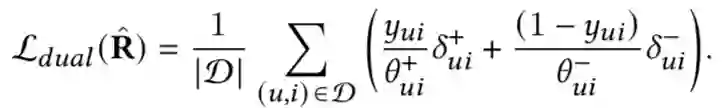
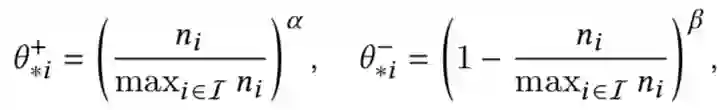
Controlling Fairness and Bias in Dynamic Learning-to-Rank. SIGIR 2020
Controlling Fairness and Bias in Dynamic Learning-to-Rank. SIGIR 2020
关键词:popular bias / Fairness
在双边市场(购物,音乐等)中,物品的排序不仅对用户有效用,而且还决定了物品提供者(供应商、工作室等)的效用(曝光、收入等),只针对用户优化排序算法会对物品提供者不公平。本文核心针对的两个问题:
马太效应:流行的越来越流行(rich-get-richer)
公平性:针对用户的排序算法导致的对物品提供者不公平问题
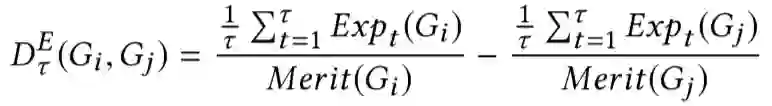
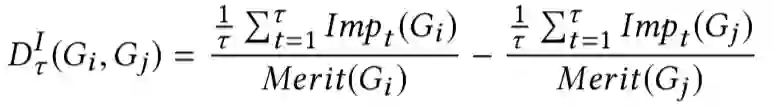
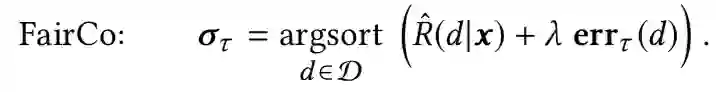
Popularity Bias in Dynamic Recommendation. KDD 2021
Popularity Bias in Dynamic Recommendation. KDD 2021
关键词:popular bias / dynamic
流行度偏差是推荐系统中长期存在的挑战:受欢迎的物品被过度推荐,造成了用户可能感兴趣的不太受欢迎的物品被牺牲,这种偏差对用户和物品提供者都产生了不利影响。大多数现有工作将流行度偏差置于静态环境中,仅针对单轮推荐分析偏差,这些工作没有考虑到现实推荐过程的动态性,主要针对以下几个问题:
流行度偏差在动态场景中如何演变?
动态推荐过程中的独特因素对偏差有什么影响?
如何在这个长期动态过程中消除偏差?
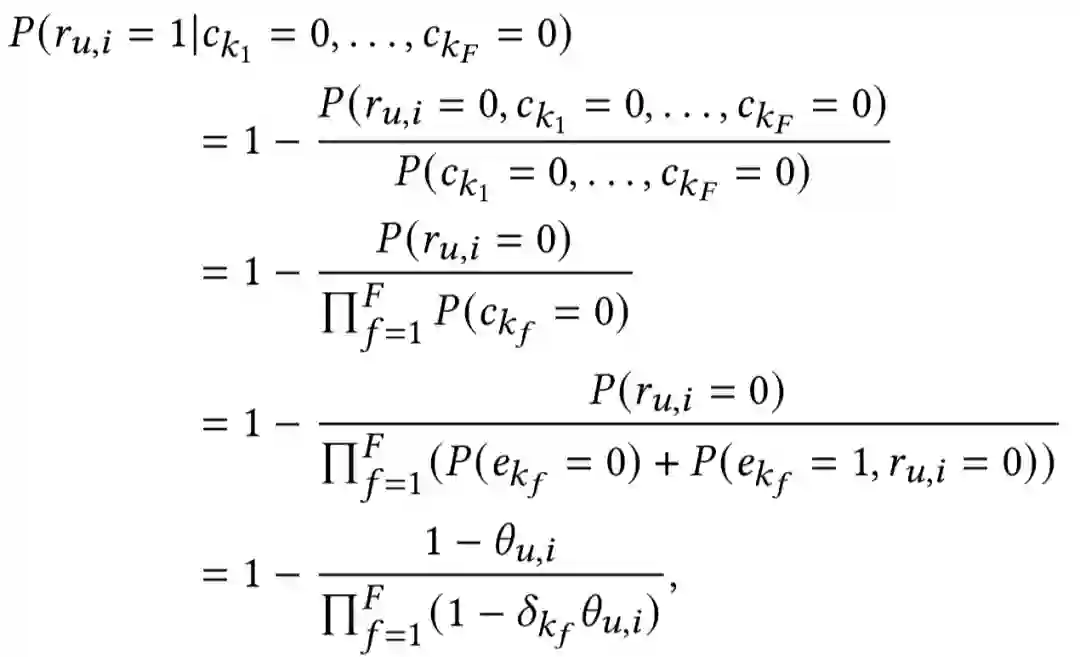
Maximizing Marginal Fairness for Dynamic Learning to Rank. WWW 2021
Maximizing Marginal Fairness for Dynamic Learning to Rank. WWW 2021
关键词:Fairness / Dynamic LTR
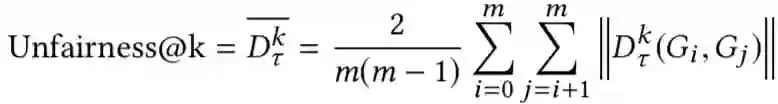
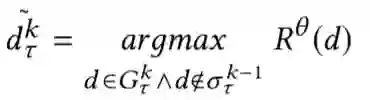
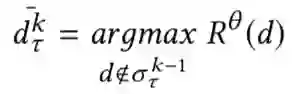
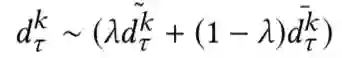
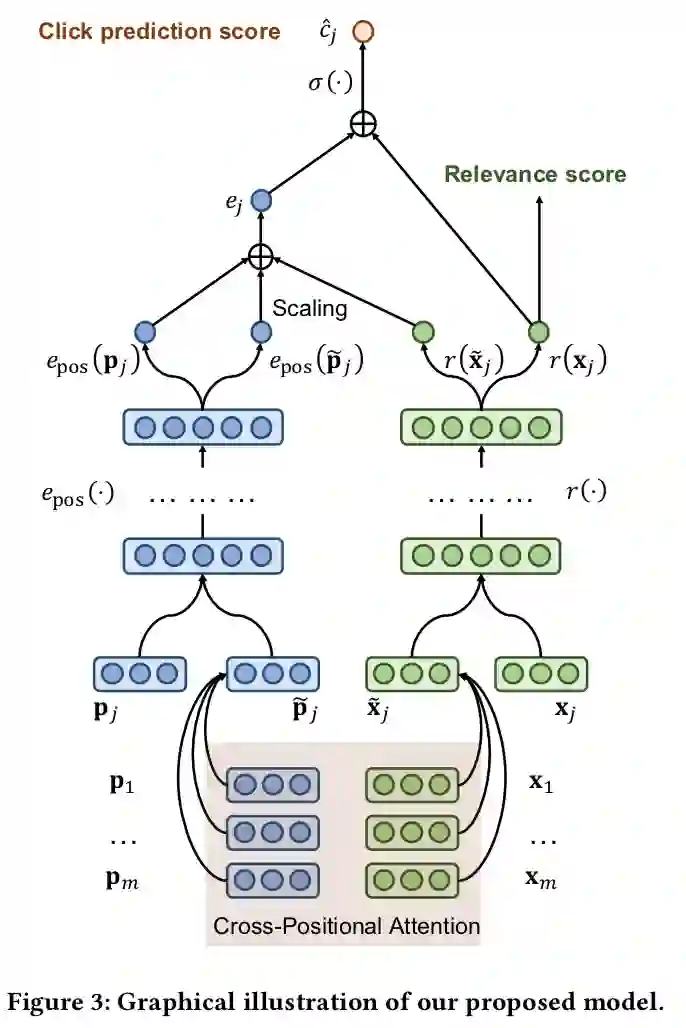
Cross-Positional Attention for Debiasing Clicks. WWW 2021
Cross-Positional Attention for Debiasing Clicks. WWW 2021
关键词:position bias
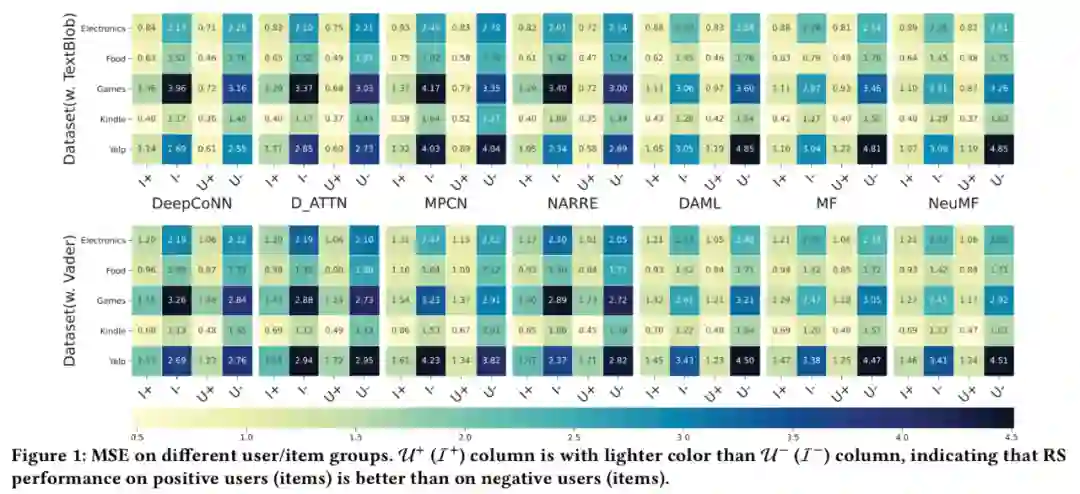
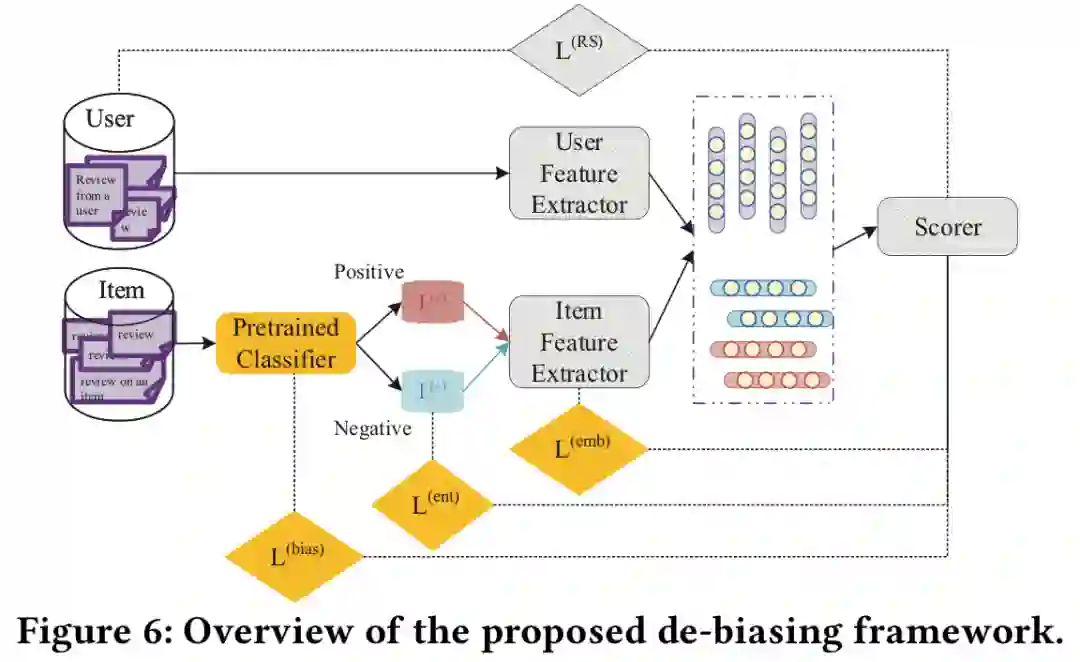
Mitigating Sentiment Bias for Recommender Systems. SIGIR 2021
Mitigating Sentiment Bias for Recommender Systems. SIGIR 2021
关键词:sentiment bias
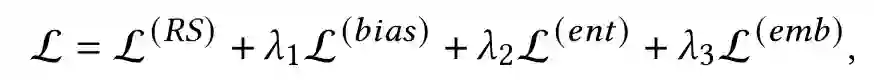

参考文献
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



