零基础概率论入门:最大似然估计
编者按:本文是数据科学家Jonny Brooks-Bartlett撰写的零基础概率论教程的第二篇,介绍了最大似然估计方法。

在这篇文章中,我将解释用于参数估计的最大似然方法是什么,然后通过一个简单的例子来展示这一方法。其中一些内容需要概率论的一些基础概念,例如联合概率和独立事件。所以如果你觉得需要温习一下这些概念的话,可以参考我的上一篇文章。
什么是参数?
在机器学习中,我们经常使用模型描述从数据中观测结果的过程。例如,我们可能使用随机森林模型来分类客户是否会退订某项服务(称为客户翻转),也可能使用线性模型来基于广告开销预测利润(这将是线性回归的一个例子)。每个模型都包含各自的参数集合,参数集合最终定义了模型是什么样的。
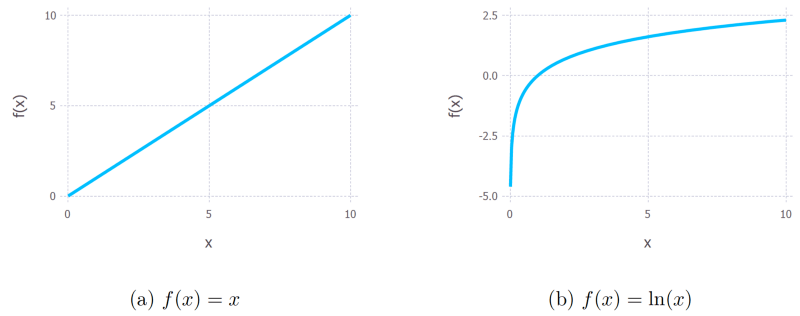
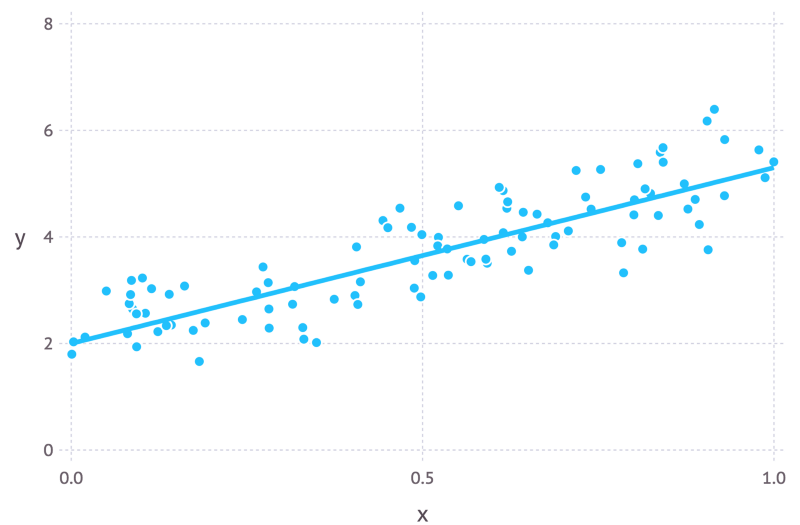
我们可以用y = mx + c来表示线性模型。在这个例子中,x可能表示广告开销,y可能表示产生的利润。m和c是这个模型的参数。不同的参数将给出不同的曲线(见下图)。
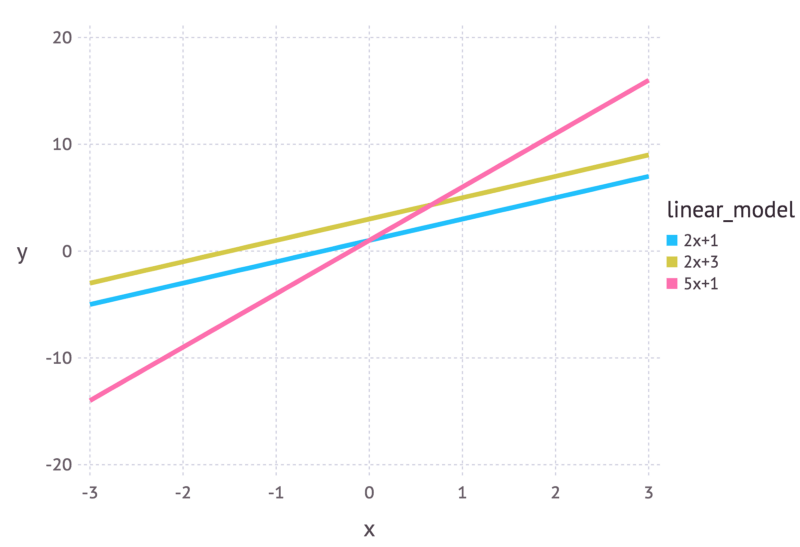
所以参数描述了模型的蓝图。仅当我们选定参数值的时候,我们得到了描述给定现象的模型实例。
最大似然估计的直觉解释
最大似然估计是一个决定模型参数值的方法。参数值的选定最大化模型描述的过程的结果与数据实际观测所得的似然。
以上的定义可能仍然比较晦涩,所以让我们通过一个例子来理解这一概念。
假定我们从某一过程中观测到了10个数据点。例如,每个数据点可能表示一个学生回答一道考题的时长。
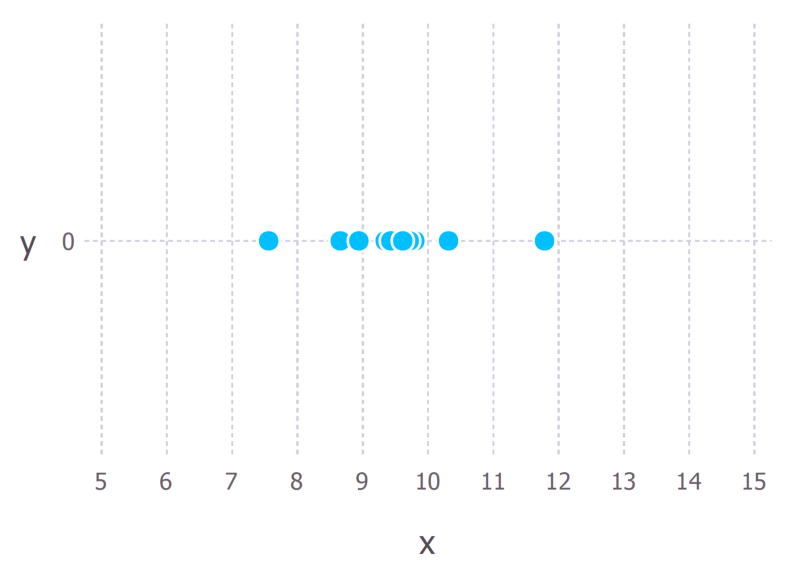
我们首先要决定,我们认为哪种模型是描述生成这些数据的最佳模型。这部分非常重要。至少,我们对使用哪种模型要有个概念。这通常源于某些专门的领域知识,不过我们这里不讨论这个。
对这些数据而言,我们假定数据生成过程可以通过高斯(正态)分布充分表达。从上图我们可以看到,10个点中的大部分都聚类在当中,少数点散布在左侧和右侧,因此,高斯分布看起来会是一个不错的选择。(仅仅只有10个数据点的情况下就做出这样的决定实在是欠考虑,不过既然其实是我生成了这些数据点,那我们姑且就这样吧。)
回忆一下,高斯分布有两个参数,均值μ和标注差σ。这些参数的不同值将造就不同的曲线(和前文的直线一样)。我们想知道哪条曲线最可能生成了我们观测到的数据点?(见下图)。最大似然估计是一个寻找拟合数据的最佳曲线的参数μ、σ的值的方法。
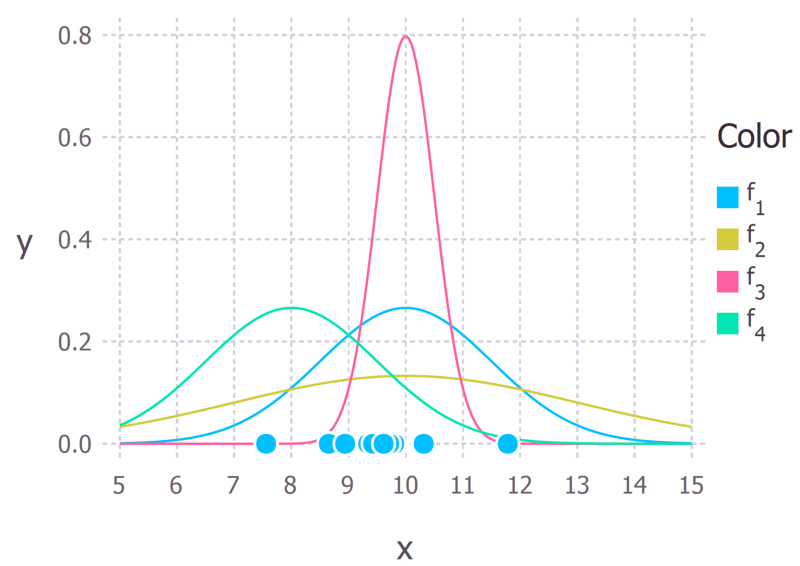
上图给出了可能从中抽取数据点的高斯分布。f1是均值为10、方差为2.25(方差等于标准差的平方)的正态分布,记为f1 ~ N(10, 2.25)。其他几条曲线相应地记为f2 ~ N(10, 9)、f3 ~ N(10, 0.25)、f4 ~ N(8, 2.25)。最大似然的目标是找到一些参数值,这些参数值对应的分布可以最大化观测到数据的概率。
生成数据的真正分布是f1 ~ N(10, 2.25),也就是上图中蓝色的曲线。
计算最大似然估计
既然我们已经具备了最大似然估计的直觉理解,我们可以继续学习如何计算参数值了。我们找的值称为最大似然估计(MLE)。
同样,我们将通过一个例子加以说明。这次我们假设有3个数据点,产生这3个数据点的过程可以通过高斯分布充分表达。这三个点分别是9、9.5、11。我们如何计算高斯分布的参数μ 、σ的最大似然估计呢?
我们想要计算的是观测到所有数据的全概率,即所有观测到的数据点的联合概率分布。为此我们需要计算一些条件概率,这可能会很困难。所以这里我们将做出我们的第一个假设。假设每个数据点的生成和其他点是独立的。这一假设让数学容易很多。如果事件(即生成数据的过程)是独立的,那么观测到所有数据的全概率是分别观测到每个数据点的概率的乘积(即边缘概率的乘积)。
观测到高斯分布生成的单个数据点x的(边缘)概率为:
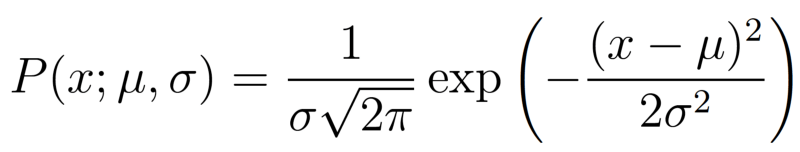
P(x; μ, σ)中的分号强调之后的符号代表概率分布的参数,而不是条件概率(条件概率通常用竖线分割,例如P(A|B))。
在我们的例子中,观测到3个数据点的全(联合)概率为:
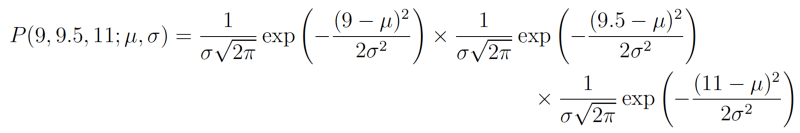
我们只需找出能最大化以上表达式的值的μ和σ的值。
如果你的数学课覆盖了微积分的话,你大概能意识到有一个帮助我们找到函数的最大(最小)值的技术。它叫做微分。我们只需找到函数的导数,将导数设为零,重新整理等式,将需要搜索的参数转变为等式的主题。看,我们得到了参数的MLE值。下面我将详细讲解这些步骤,不过我会假设读者知道常见函数如何求导。如果你希望看到更详细的解释,请留言。
对数似然
实际上,对上面的全概率表达式求导很麻烦。所以我们基本上总是通过取自然对数对其加以简化。由于自然对数是单调递增函数,所以这么做绝对没问题。单调递增函数意味着随着x轴的值增加,y轴的值也同样增加(见下图)。这很重要,因为这确保了当概率的对数达到最大值时,原概率函数同样达到最大值。因此我们可以操作简化了的对数似然,而不是原本的似然。
对原表达式取对数,我们得到:
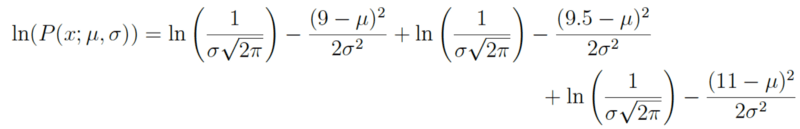
据对数定律,上式可以简化为:
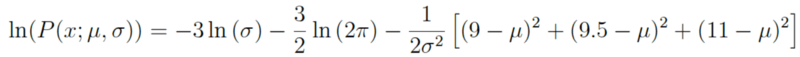
对以上表达式求导以找到最大值。在这个例子中,我们将寻找均值μ的MLE。为此,我们求函数关于μ的偏导数:
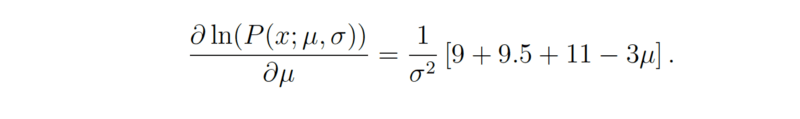
最后,我们将等式的左半部分设为0,据μ整理等式得到:
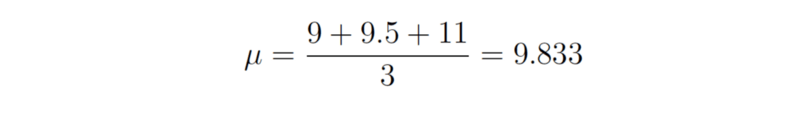
这样我们就得到了μ的最大似然估计。同理,我们可以求得σ的最大似然估计,这个作为习题留给敏锐的读者。
结语
最大似然估计总是能以精确的方式解决吗?
短答案是不。在现实世界的场景中,对数似然函数的导数往往仍然难以解析(也就是说,手工求导太困难甚至不可能)。因此,最大期望算法之类的迭代方法被用于寻找参数估计的数值解。不过总体思路是一样的。
为什么是最大似然,而不是最大概率?
好吧,这只是统计学家在卖弄学问(不过他们的理由很充分)。大部分人倾向于混用概率和似然,但是统计学家和概率论学者区分了两者。以下等式突显了两者之所以容易混淆的原因:
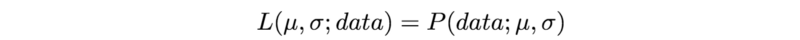
这两个表达式是相等的!所以这意味着什么?让我们先来定义P(data; μ, σ)。它的意思是“基于模型参数μ和σ观测到数据的概率”。值得注意的是,我们可以将其推广到任意数目的参数和任意分布。
另一方面,L(μ, σ; data)的意思是“我们已经观测到一组数据,参数μ和σ取特定值的似然”。
上面的等式意味着给定参数得到数据的概率等于给定数据得到参数的似然。然而,尽管两者相等,似然和概率根本上问的是不同的问题——一为数据,一为参数。这就是这一方法叫做最大似然而不是最大概率的原因。
什么时候最小二乘法和最大似然估计是一样的?
最小二乘法是另一个估计机器学习模型的参数值的方法。当模型像上文的例子中一样呈高斯分布的时候,MLE估计等价于最小二乘法。关于两者在数学上的深层渊源,可以参考这些幻灯片。
直觉上,我们可以通过理解两者的目标来解释两个方法之间的联系。最小二乘法想要找到最小化数据点和回归线之间的距离平方和的直线(见下图)。最大似然估计想要最大化数据的全概率。如果数据符合高斯分布,那么当数据点接近均值时,我们找到了最大概率。由于高斯分布是对称的,因此这等价于最小化数据点和均值之间的距离。
如果你有任何不明白的地方,或者我有在文章中有弄错的地方,欢迎留言。下一篇文章我将介绍贝叶斯推断,以及如何将其用于参数估计。
谢谢阅读。
谢谢Ludovic Benistant在本文发表前给出的反馈。
原文地址:https://towardsdatascience.com/probability-concepts-explained-maximum-likelihood-estimation-c7b4342fdbb1







