深度 | 蚂蚁金服DASFAA论文带你深入了解GBDT模型

小蚂蚁说:
2018年5月21日,国际顶级数据库会议DASFAA 2018(International Conference on Database Systems for Advanced Applications)在澳大利亚黄金海岸举办。
本文是蚂蚁金服录用于DASFAA的论文Unpack Local Model Interpretation for GBDT(作者:方文静、周俊、李小龙、朱其立)的简要介绍。
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和SVM一起被认为是泛化能力(generalization)较强的算法,近些年更因为被用于搜索排序的机器学习模型而引起大家关注。
GBDT模型自被提出以来,一直在有监督的机器学习任务中扮演重要角色,在各种机器学习算法竞赛中数见不鲜,因此对其应用的算法业务中对模型结果解释的需求也日益增加。本文设计并解释了一种GBDT模型行之有效的局部解释性方案。
引言
GBDT(Gradient Boosting Decision Tree)模型自被提出以来,一直在有监督的机器学习任务中扮演重要角色,在各种机器学习算法竞赛中数见不鲜。GBDT是一系列决策树弱分类器的集成,将所有决策树的分值相加获得最终预测结果,由于这种集成方法的本质,GBDT在众多问题中具有较优的表现,因此吸引了研究者们对算法进行不断优化,出现不同的变式。树形模型虽然在诸多任务上取得比线性模型更好的效果,但线性模型的一大优势在于天然能提供特征重要性的评判,因此在一些需要模型解释的场景,树形模型的应用受到了局限。本文关注为GBDT模型及其各种变式,提供一种统一的局部解释方案,对每一个预测样本可以给出各个特征的贡献度,从而对模型预测结果进行归因。
下文是对蚂蚁金服在DASFAA的论文Unpack Local Model Interpretation for GBDT的介绍,论文链接:
https://link.springer.com/content/pdf/10.1007%2F978-3-319-91458-9_48.pdf
请将链接复制至浏览器中打开,或点击文末阅读原文查看。
问题说明:
模型解释分为两类,一类是全局的解释性,衡量特征在模型中起的整体作用,另一类是局部的解释性,目的是对一个特定的预测条目,衡量该条样本预测分高的原因。
两类解释具有较大区别,以线性模型的解释为例,对于进行了归一化处理后的特征而言,最终的模型权重绝对值即为全局的特征重要性,因为权值越大该特征对最终分值影响越大,而对于一个取得高分的具体预测实例而言,可能在全局最重要的特征上,其分值较小,在该条样本的得分计算上并无多大贡献,因此对于线性模型单条样本的局部解释性,会使用权值乘以特征值来作为该维特征的贡献度,从而得到各个特征间的重要性排序。
对于GBDT模型全局的解释性,Freidman基于树模型中分裂点对均方误差的影响,提出了评估特征重要性的方法,并被广泛用在特征筛选和模型分析当中。然而,对于对其局部解释性则需要将特征值纳入考虑,希望能够在有解释性需求的场景,对GBDT的单条结果提供个性化的解释。
问题分析
对于GBDT的局部解释性,需要考虑到几个方面的问题。
第一,不同于线性模型,模型权值与各维特征一一对应,GBDT这种树形模型的权值存在于叶子结点上,一个叶子结点实际上是从根节点开始,由一系列特征分裂点、特征分裂值决定的一条路径,也就是一个叶节点上的分值是多个特征共同决定的,所以问题的难点就在于需要对单个特征的贡献度进行定义。
第二,由于GBDT模型的特点,它的每一棵树拟合的都是当前的残差,同一特征在不同的树上贡献度也是不同的,因为随着残差的逐渐减小,后面的树对最后预测分值的贡献度也是更小的,因此随机森林RF(Random Forest)模型那种基于样本标签分布变化的局部解释性方案不适用于GBDT模型。此外,GBDT还具有不同的变式,可能采用不同的损失函数和优化策略,解释性方案应该具有通用性。
方法介绍
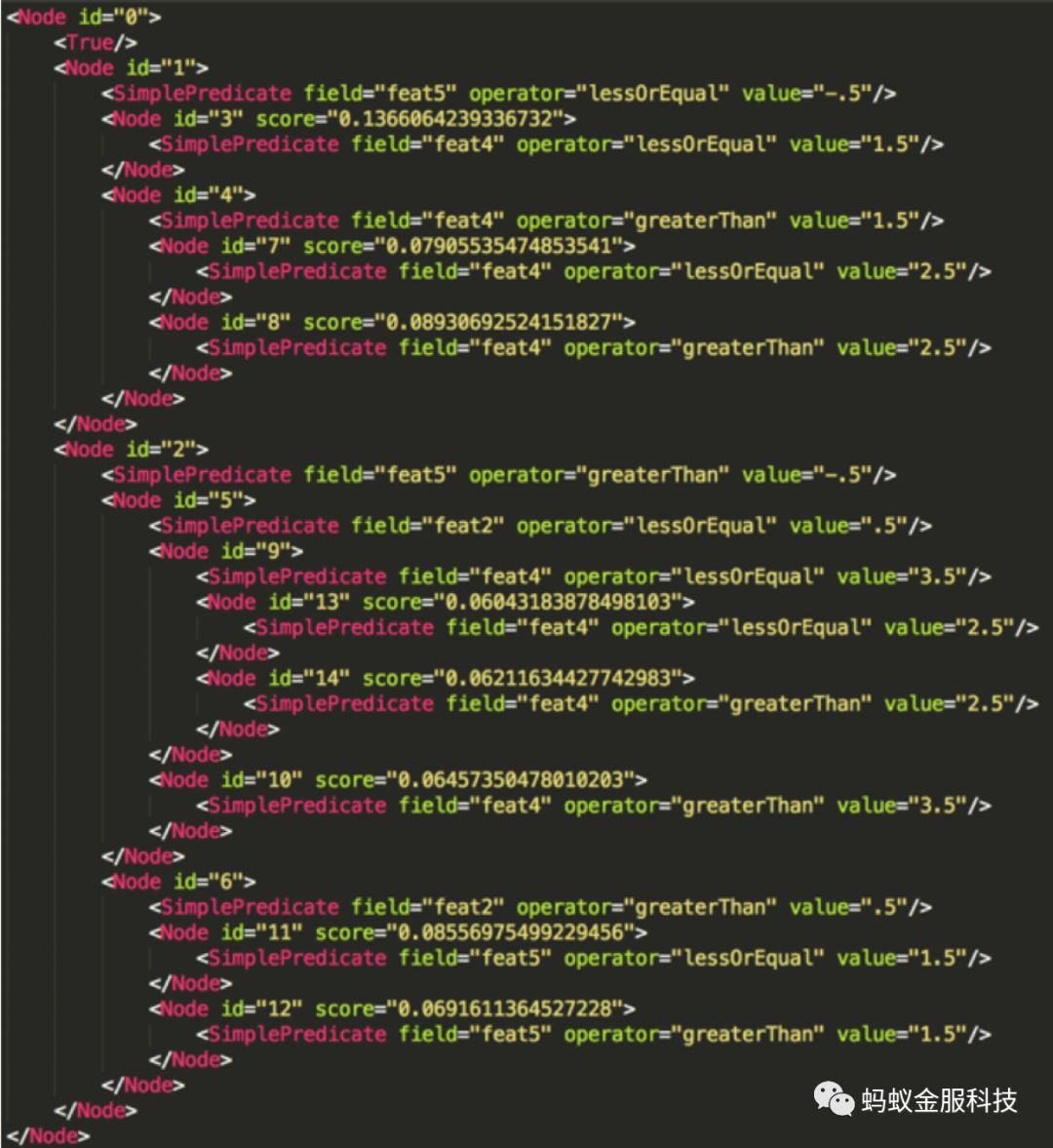
图1:GBDT模型的PMML文件
模型解释的关键在于对特征贡献度的定义,需要把分数的计算分配到每个途径的特征上。并且,对于不同的GBDT实现来说,虽然其优化的原理和过程有所不同,但最终的模型输出是相同的,即叶节点上的分值。为了不失解释的一般性,我们的方案就基于这些分值和单条样本的各维特征值来计算。
GBDT的模型可以使用PMML (Predictive Model Markup Language)的格式来记录,图1即为一个GBDT模型的训练结果的一部分,记录了其中一棵树的表示。Node元素标记的是一个树节点,每个树节点还包含了一条断定规则,决定一个样本是落向它还是它的兄弟节点,每一个节点的id属性是其唯一标识,只有叶节点拥有score属性,也就是一个样本落到该叶节点时获得的分值,可以将图1中表示的树画成图2的形式。
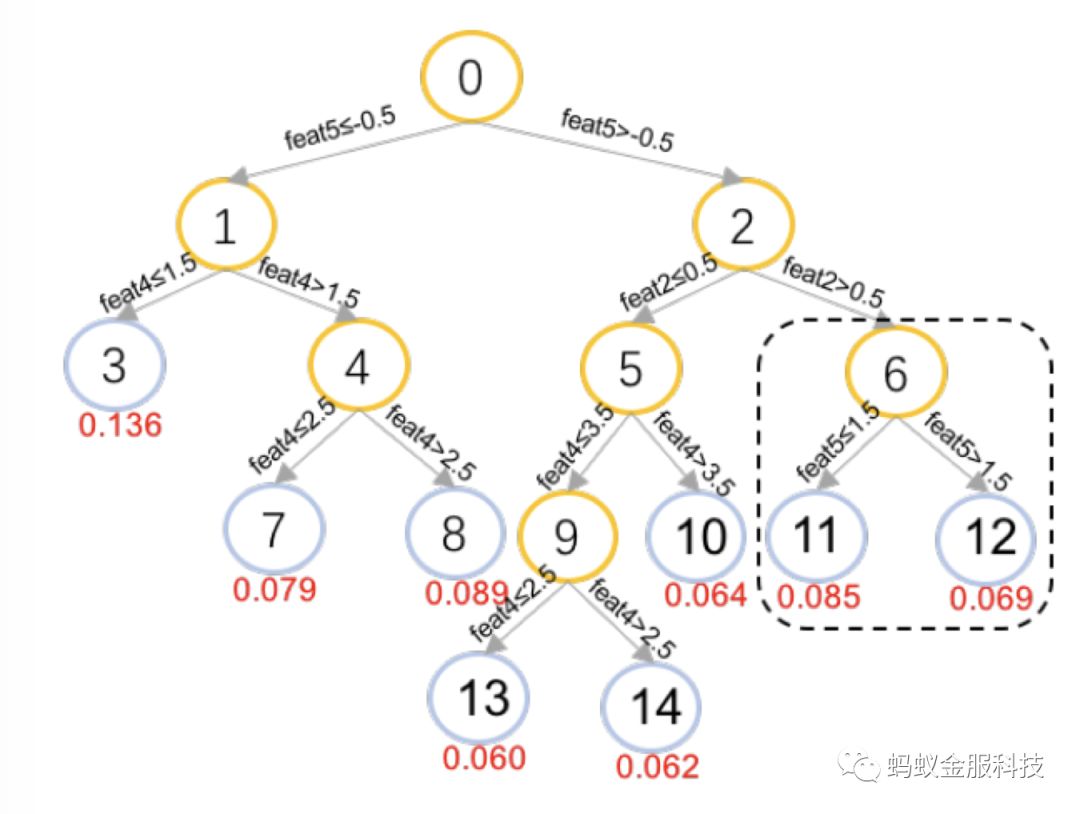
观察图2中的节点6、节点11和节点12,由父节点6向两个子节点前进的过程中,会对特征feat5进行判断,若其小于等于1.5则落向节点11获得0.085的预测分,否则落向节点12获得0.069的预测分。也就是在这一步的前进当中,由于特征feat5的不同,一个样本可能会获得的分值差异为Sn11 − Sn12 = 0.085 – 0.069 = 0.016,Snk表示在节点k上的得分。所以,可以通过求两个叶节点的平均值获得对节点6的分值估计,再通过自底向上回溯的方式,可以将分数回溯到所有中间节点最后到达根节点。分裂特征f落到叶节点c后的局部的特征贡献(LI:local increment)则可由子节点分值(Sc)与父节点分值(Sp)的差表示:

这样就实现了局部特征贡献度的定义,将分数分摊到各个特征上,图2示例的处理结果标识在图3当中。蓝色的分值表示中间节点获得的分值估计,边上的橙色
部分表示了经过该条边时的贡献特征和贡献分值。
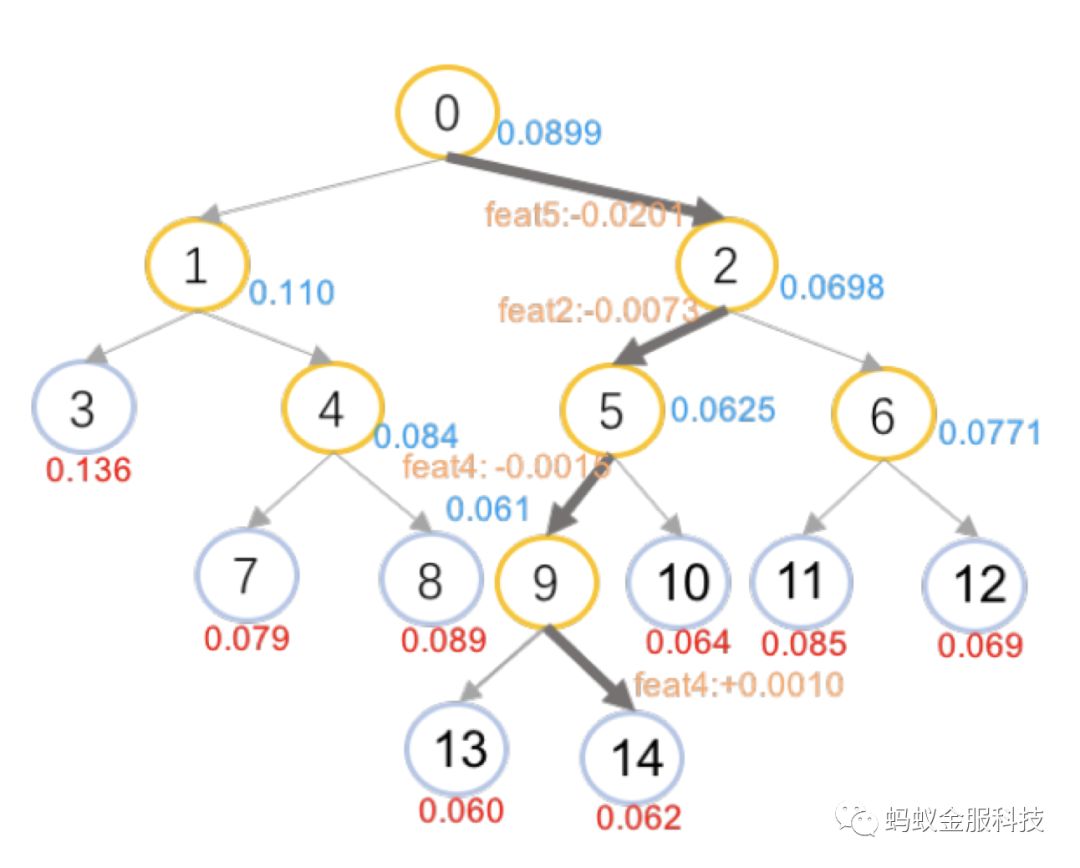
值得注意的是,从父节点落入左右两个子节点的样本数并不相同,所以在求平均值的时候,为了得到父节点更准确的估计,应该使用样本数进行加权,即:
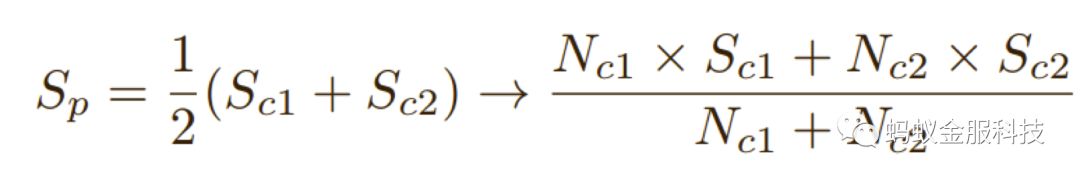
其中Sp表示父节点的分值,Sc1、Sc2分别表示两个子节点的分值,Nc1、Nc2则对应训练集中子节点c1,c2所包含的样本数。上面的预处理需要在训练阶段,记录下每个节点上的样本数量,再结合模型文件,对所有的树进行预处
理,贡献分值的大小和每棵树上的分值息息相关。
有了预处理好的局部特征贡献度,要得到一个样本预测时的特征重要性解释,只需要获得它在所有树上经过的所有路径上的特征贡献,并按照特征维度进行累积。例如对于图3中表示的一条路径n0->n2->n5->n9->n14,则可计算出特征feat4的特征贡献为:
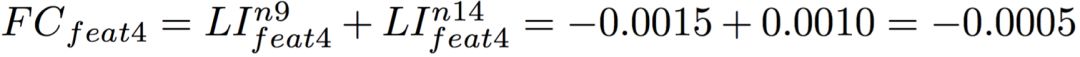
计算可以形式化地表示为:
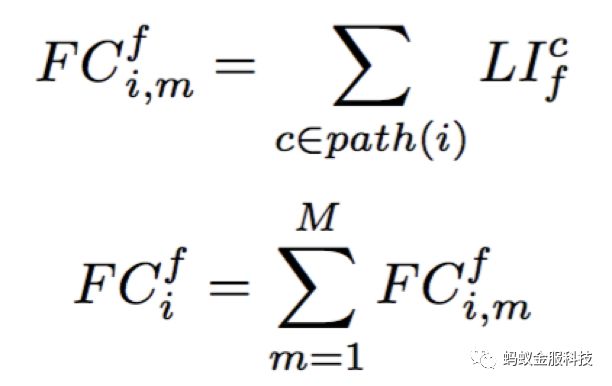
其中,第一步表示的是计算特征f在样本i、单棵树m上的贡献度,第二步表示在所有树上进行贡献度的累加,获得最终贡献度总计。
通过这样两阶段的操作,我们可以获得GBDT模型对每个样本预测的局部解释。第一步的预处理过程会提供预测时所需的局部特征贡献,并不会在第二步的预测过程中引入过多的计算而影响预测性能,因此样本解释可以实时获得。
实验结果
我们使用阿里内部基于参数服务器的GBDT分布式版本SMART(Scalable Multiple Additive Regression Tree)进行模型的训练,并记录样本在节点上的分布情况。在预测阶段,使用JPMML作为预测器,并修改其代码以支持模型解释的输出。训练样本是支付宝转账交易的部分抽样,其中正样本定义为被用户举报并定性为欺诈的案件。
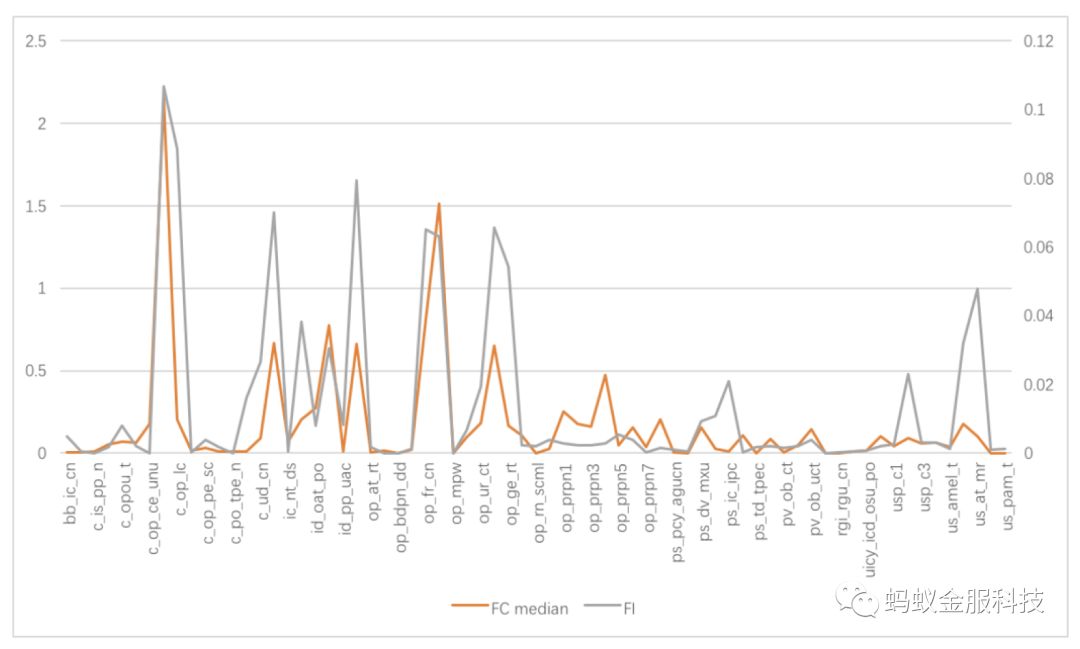
首先,我们检查了本文局部模型解释方案与全局模型解释方案的一致性。局部模型解释方案是对单条样本进行的,我们对大量样本输出的解释观察时,对于每一维特征存在一个贡献度的分布,我们取这个分布的中位数作为其一般衡量,它应该与全局模型解释对各个特征重要性大小的判断保持一致,分析结果如图4所示,橙色、灰色分别表示各个特征的局部、全局解释,具有我们预估的一致性,说明本文GBDT的局部解释方案较为可靠。
然后,延续上面特征贡献度中位数作为特征重要性评估,我们将其排序结果同随机森林RF的局部解释方案进行对比。IV(Information Value)作为一种特征预测力的评测指标,经常被用在特征选择中,我们测试了两种局部解释方案的重要性排序在前50位的特征,对比它们对IV的前50特征的分段覆盖率(为了公平,我们引入了IV特征重要性,而不是使用GBDT全局特征重要性),二者对比结果如图5所示。
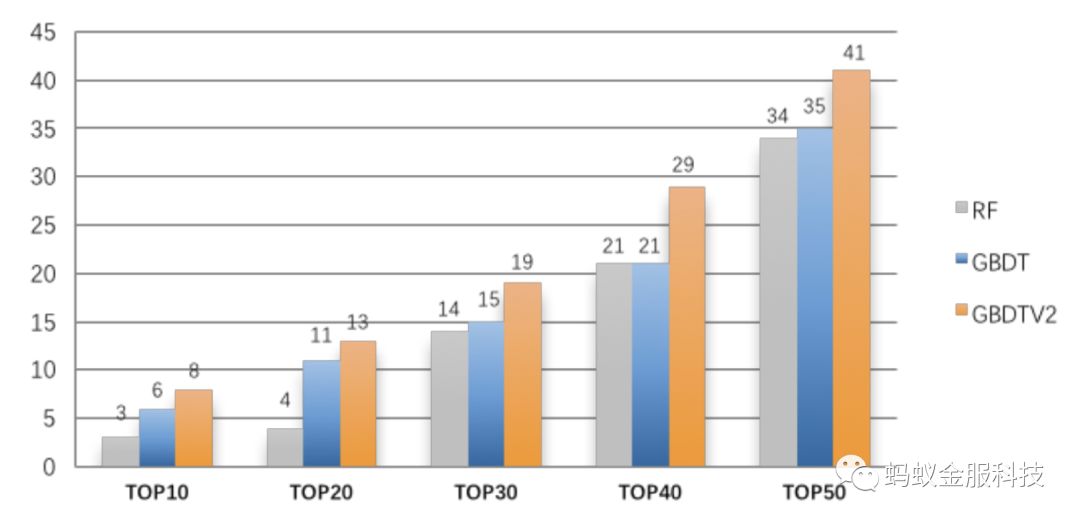
其中蓝色GBDT表示直接使用子节点平均值作为父节点分值的初始方案,橙色GBDTV2表示使用样本个数加权平均的修正方案的结果。可以看出,GBDT的局部模型解释结果优于RF,且修正后的方案表现最佳。
最后,我们还通过人工进行具体解释案例检查,分析支付宝交易测试集,发现本文模型解释输出的高风险特征与人工判断一致,并且还能抓出一些全局重要性不高,但在特定样本中属于高风险的特征,验证了结果的可靠性和实用性。
总结
将机器学习模型用作黑盒在很多应用场景中已经远远不够,我们不仅需要模型输出的最终结果,并且还要求对给出的结果进行解释。
此外,模型解释还可以用于模型检查,通过给数据分析师一个直观解释,判断与人工归因的一致性来验证模型的效果,从而使他们相信机器学习模型。另一方面,模型解释也可以用于模型的提高,通过对漏抓、误抓样本的解释,可以对特征进行补充、修改,进而实现模型的更新迭代和效果的进一步提升。
我们提出了被广泛应用的GBDT模型的一种通用的局部模型解释方法,先通过对训练的模型进行一步离线预处理,再在预测时候对特征贡献度进行累加和排序,实现对每个样本结果的解释。我们通过实验检验了这一方法,从多个维度说明其有效性,并将它应用到实际业务中,成为一个优秀的“模型翻译官”。
— END —
< 粉丝福利时间 >

恭喜以下用户您获得『蚂蚁金服科技』粉丝福利:云栖2050门票一张
xyzlab、空、Limo、覔亖甴、Joe-姜忠坷、纯、成崽儿、圣爱、魔方、Monte、山在北国、dk、Mystery、莫那·鲁道、德 立、0.0、成东青、欲 乱 人 心 、笑吧、軍軍軍军
请获奖的用户添加蚂蚁小助手微信号:Ant-Techfin01,或扫描下方二维码
回复“2050门票”然后领取您专属的兑换码
购票官网:https://www.yunqi2050.org/#/index
非常感谢大家对蚂蚁金服技术的支持和关注!
如有问题,我们将随时为您答疑解惑
后续小蚂蚁会努力给您带来更多福利哦~