从模型到应用,一文读懂因子分解机

作者丨gongyouliu
编辑丨Zandy
来源 | 大数据与人工智能(ID: ai-big-data)
作者在上篇文章中讲解了《矩阵分解推荐算法》,我们知道了矩阵分解是一类高效的嵌入算法,通过将用户和标的物嵌入低维空间,再利用用户和标的物嵌入向量的内积来预测用户对标的物的偏好得分。本篇文章我们会讲解一类新的算法:因子分解机(Factorization Machine,简称FM,为了后面书写简单起见,中文简称为分解机),该算法的核心思路来源于矩阵分解算法,矩阵分解算法可以看成是分解机的特例(我们在第三节1中会详细说明)。分解机自从2010年被提出后,由于易于整合交叉特征、可以处理高度稀疏数据,并且效果不错,在推荐系统及广告CTR预估等领域得到了大规模使用,国内很多大厂(如美团、头条等)都用它来做推荐及CTR预估。
本篇文章我们会从分解机简单介绍、分解机的参数估计与模型价值、分解机与其他模型的关系、分解机的工程实现、分解机的拓展、近实时分解机、分解机在推荐上的应用、分解机的优势等8个方面来讲解分解机相关的知识点。期望本文的梳理可以让读者更好地了解分解机的原理和应用价值,并且尝试将分解机算法应用到自己的业务中。
一、分解机简单介绍
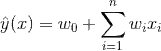
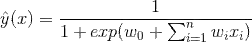
LR模型是CTR预估领域早期最成功的模型,也大量用于推荐算法排序阶段,大多工业推荐排序系统通过整合人工非线性特征,最终采用这种“线性模型+人工特征组合引入非线性”的模式来训练LR模型。因为LR模型具有简单、方便易用、解释强、易于分布式实现等诸多好处,所以目前工业上仍然有不少算法系统采取这种模式。但是,LR模型最大的缺陷就是人工特征工程,耗时费力,浪费大量人力资源来筛选组合非线性特征,那么能否将特征组合的能力体现在模型层面呢?也即,是否有一种模型可以自动化地组合筛选交叉特征呢?答案是肯定的。
其实想达到这一点并不难,如上图在线性模型的计算公式里加入二阶特征组合即可,任意两个特征进行两两组合,可以将这些组合出的特征看作一个新特征,加入线性模型中。而组合特征的权重和一阶特征权重一样,在训练阶段学习获得。其实这种二阶特征组合的使用方式,和多项式核SVM是等价的(我们在第三节2中会介绍)。借助SVM中核函数的思路,我们可以在线性模型中整合二阶交叉特征,得到如下的模型。
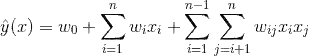
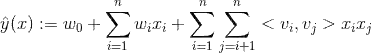
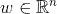 、
、 。
。
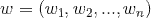 ,是n维向量。
,是n维向量。
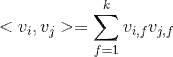
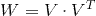 (
Cholesky decomposition)。
(
Cholesky decomposition)。
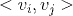 和
和
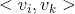 共用一个相同的向量
共用一个相同的向量
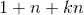 ,而整合两两二阶交叉的线性模型的系数个数为
,而整合两两二阶交叉的线性模型的系数个数为
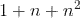 。分解机的系数个数是n的线性函数,而整合交叉项的线性模型系数个数是n的指数函数,当n非常大时,训练分解机模型在存储空间及迭代速度上是非常有优势的。
。分解机的系数个数是n的线性函数,而整合交叉项的线性模型系数个数是n的指数函数,当n非常大时,训练分解机模型在存储空间及迭代速度上是非常有优势的。
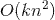 。但是我们可以通过适当的公式变换与数学计算,将模型复杂度降低到
。但是我们可以通过适当的公式变换与数学计算,将模型复杂度降低到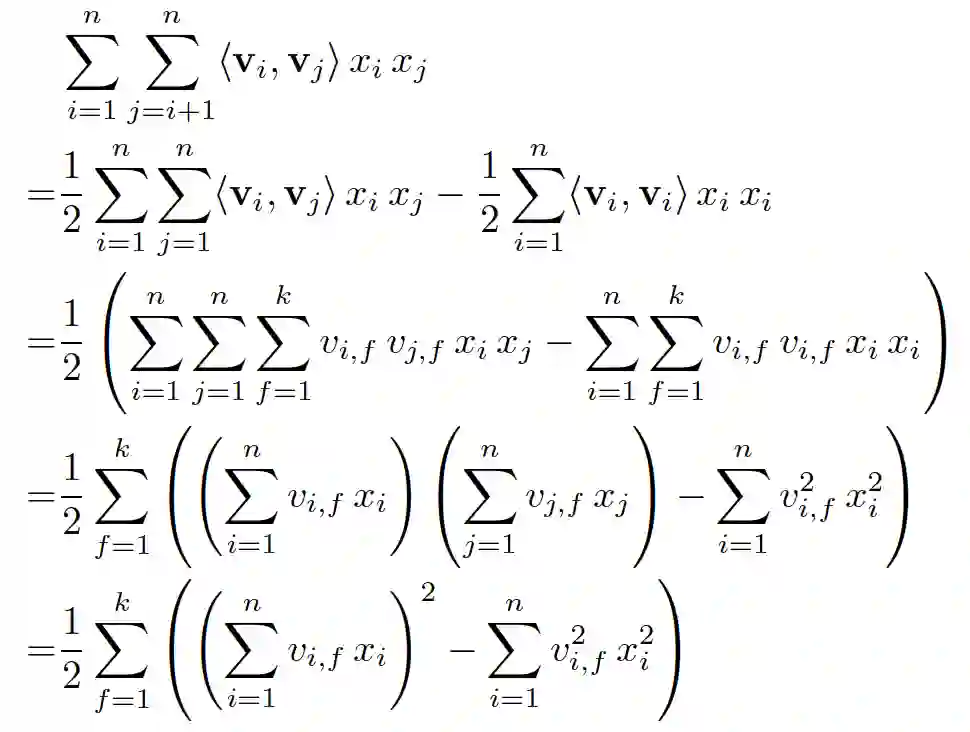
 ,最终的时间复杂度是
,最终的时间复杂度是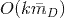 ,
,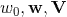 )可以在工程实现上高效地利用梯度下降算法(SGD、ALS等)来训练(即我们可以线性时间复杂度求出下面的
)可以在工程实现上高效地利用梯度下降算法(SGD、ALS等)来训练(即我们可以线性时间复杂度求出下面的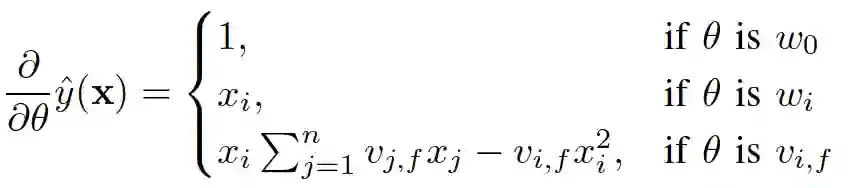
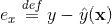 ,针对平方损失函数,具体的参数更新公式如下(未增加正则项,其他损失函数的迭代更新公式类似,也可以很容易推导出):
,针对平方损失函数,具体的参数更新公式如下(未增加正则项,其他损失函数的迭代更新公式类似,也可以很容易推导出):
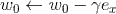
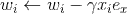
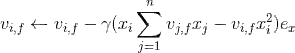
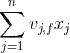 与i无关,因此可以事先计算出来(在做预测求
与i无关,因此可以事先计算出来(在做预测求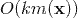 ,
,
(1) 回归问题(Regression)
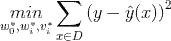
(2) 二元分类问题 (Binary Classification)
![]() 最为最终的分类,我们可以通过hinge loss或者logit loss来训练二元分类问题。
最为最终的分类,我们可以通过hinge loss或者logit loss来训练二元分类问题。
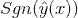 最为最终的分类,我们可以通过hinge loss或者logit loss来训练二元分类问题。
最为最终的分类,我们可以通过hinge loss或者logit loss来训练二元分类问题。
(3) 排序问题(Ranking)
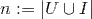 (用户数+标的物数),其中
(用户数+标的物数),其中
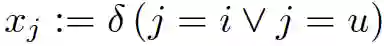
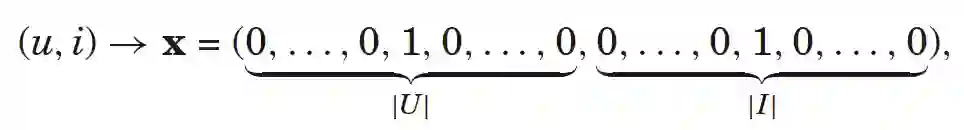
这时,FM模型可以表示为
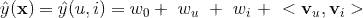
3.2 FM与SVM的联系
 ,这里
,这里
 将输入向量映射到一个复杂的空间,
将输入向量映射到一个复杂的空间,
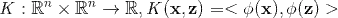
下面我们分线性核函数和多项式核函数两种情况来说明SVM与FM之间的关系。
(1) 线性核
最简单的线性核函数是: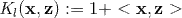
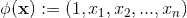
线性核的SVM模型方程可以写为
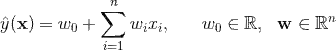
这对应无二阶交叉项的FM,也即是第五节1高阶分解机中的一阶分解机。
(2) 多项式核
多项式核的SVM可以建模自变量的高阶交叉特征,它的核函数是
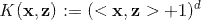
当d=2(二阶交叉特征),对应的映射(其中可行的一个)为
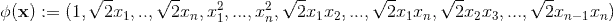
这时二阶多项式核的SVM模型方程为
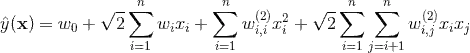
其中,
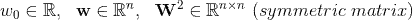
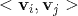 与
与
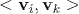 之间相关,都依赖
之间相关,都依赖
(3) 线性核和多项式核下SVM存在的问题
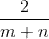 的数据非零,一般m、n是非常大的,所以非常稀疏)。
的数据非零,一般m、n是非常大的,所以非常稀疏)。
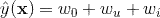 。从作者的上篇文章《协同过滤推荐系统》,可以知道,该模型非常简单,仅仅整合了用户和标的物的bias,没有用户和标的物嵌入向量的内积项,因此非常容易训练,但是效果不会很好。
。从作者的上篇文章《协同过滤推荐系统》,可以知道,该模型非常简单,仅仅整合了用户和标的物的bias,没有用户和标的物嵌入向量的内积项,因此非常容易训练,但是效果不会很好。
同样地,针对上面的协同过滤案例,二阶多项式核的SVM的模型方程现在变为
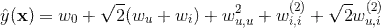
从上式可以看到,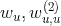

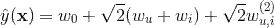
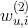 。因此在隐式协同过滤场景下,二阶多项式核的SVM无法很好利用二阶交叉特征,只能训练出用户和标的物的bias(
。因此在隐式协同过滤场景下,二阶多项式核的SVM无法很好利用二阶交叉特征,只能训练出用户和标的物的bias(
通过上面的讲解及案例介绍,下面总结一下FM与SVM的主要差异点:
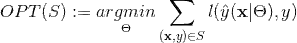
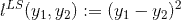 ,对于二分类问题,损失函数可以定义为:
,对于二分类问题,损失函数可以定义为: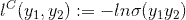 ,其中
,其中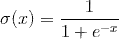 是logistic函数。
是logistic函数。
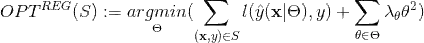
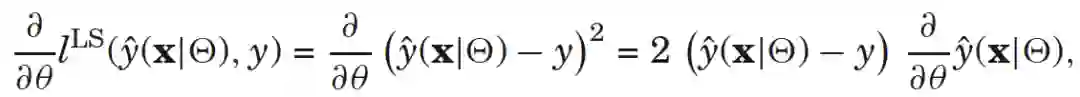
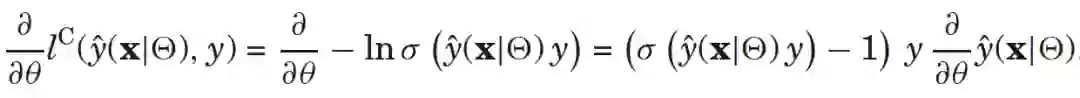
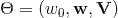
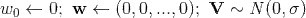
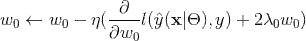
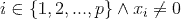 do
do
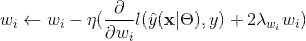
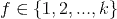 do
do
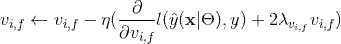
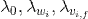 。对于一个训练样本,SGD算法的时间复杂度是
。对于一个训练样本,SGD算法的时间复杂度是
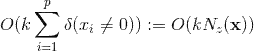
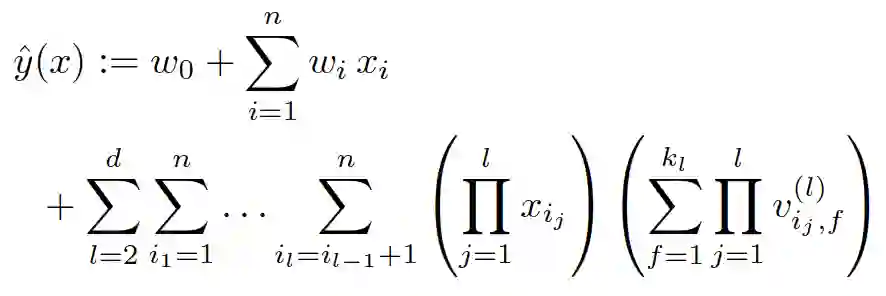
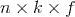 个参数,而FM只有
个参数,而FM只有
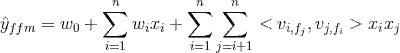
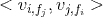 表示让特征i与 特征 j 的 field 关联,同时让特征 j 与 i 的 field 关联,由此可见,FM的交叉是针对特征之间的,而FFM是针对特征与 field 之间的交叉。
表示让特征i与 特征 j 的 field 关联,同时让特征 j 与 i 的 field 关联,由此可见,FM的交叉是针对特征之间的,而FFM是针对特征与 field 之间的交叉。
5.3 DeepFM
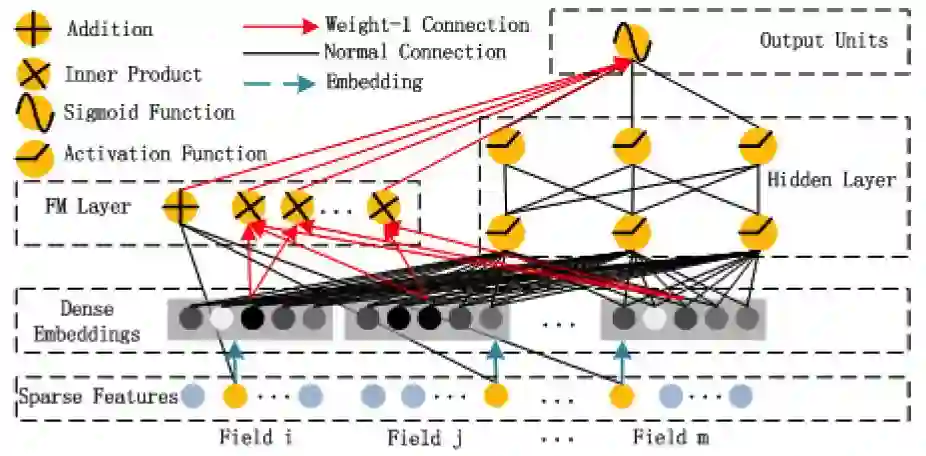
图1:DeepFM的网络结构(图片来源于参考文献4)
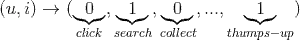
7.2 用户相关信息
7.4 上下文信息
用户在操作标的物时,是包含上下文信息的,这类上下文主要有时间、地点、上一步操作、所在路径、甚至是天气、心情等。时间可以是操作时间、是否是节日、是否是工作日、特殊事件(如双十一)、操作系统、版本等。地域对于LBS类应用是非常重要的。对于像购物等具备漏斗行为转化的产品或业务,用户的上一步操作及所在路径对训练模型非常关键。

图2:基于4类信息构建分解机的训练数据集
(1) 可以整合交叉特征,效果不错
在真实业务场景中,往往特征之间的交叉对模型预测是非常有帮助的,而分解机可以自动整合二阶(高阶)交叉特征,免去了人工特征工程(如logistic回归需要大量的人工特征工程)的工作,从而(相比矩阵分解及logistic回归等模型)可以达到更好的训练效果。
(2) 线性时间复杂度
FM通过将预测函数做数学变换,将二阶交叉特征的计算从二阶多项式的复杂度降低到线性复杂度,方便模型预测和通过SGD等迭代方法估计参数, 从而让FM在工业界的大规模数据场景下的应用(推荐系统、CTR预估等)变得可行。
(3) 可以应对稀疏数据情况
FM通过分解二阶交叉特征的系数到低维空间,避免了交叉特征的系数独立的情况,减少了参数空间,并且由于不同交叉项之间的系数是有关联的,在高度稀疏的情况下,也可以容易估计模型系数,模型泛化能力强。
(4) 模型相对简单,易于工程实现
FM模型原理非常简单,思想也很朴素,并且预测过程可以降低到线性时间复杂度,可以采用SGD等常用算法来进行训练,在工程实现上是相对容易的,有很多开源的工具都有FM的实现,我们可以直接拿来用。正因为工程实现简单,才在工业界得到大规模的推广和应用。
总结
本文对分解机的算法原理、参数估计、跟其他模型之间的关系、工程实现、分解机的拓展、近实时分解机、分解机在推荐上的应用、分解机优点等各个方面进行了综合介绍。分解机类似SVM,是一个通用的预测器,适用于任何实值特征向量的预测问题,不仅仅应用于推荐算法,在广告点击率预估等其他方面都有很大的商业应用价值。鉴于FM模型的巨大优势和商业价值,自从FM被提出后,基于FM模型在学术界的研究和工业的实践从未止步过,FM模型值得每一位做算法的从业者研究、学习、实践。
参考文献:
Factorization Machines with libFM
factorization machines
Factorization Machines with Follow-The-Regularized-Leader for CTR prediction in Display Advertising
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
DeepFM: An End-to-End Wide & Deep Learning Framework for CTR Prediction
https://github.com/srendle/libfm
http://www.libfm.org/
Scaling Factorization Machines to Relational Data
Bayesian Factorization Machines
Learning Recommender Systems with Adaptive Regularization
Fast Context-aware Recommendations with Factorization Machines
fastFM: A Library for Factorization Machines
Optimizing Factorization Machines for Top-N Context-Aware Recommendations
DiFacto — Distributed Factorization Machines
Attentional Factorization Machines- Learning the Weight of Feature Interactions via Attention Networks
Higher-Order Factorization Machines
F2M- Scalable Field-Aware Factorization Machines
Discrete Factorization Machines for Fast Feature-based Recommendation
Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising
Neural Factorization Machines for Sparse Predictive Analytics
Sketched Follow-The-Regularized-Leader for Online Factorization Machine
Field-aware Factorization Machines for CTR Prediction
Advanced Factorization Models for Recommender Systems
https://github.com/Angel-ML/angel
Ad Click Prediction- a View from the Trenches
Compact convexified factorization machine: formulation and online algorithms
Online Compact Convexified Factorization Machine
xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
推荐阅读