成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
线性模型
关注
503
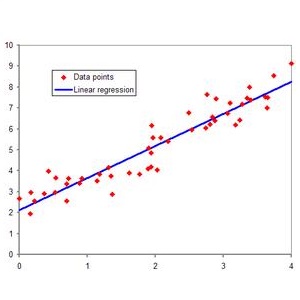
对于给定d个属性描述的示例x=(x1,x2,......,xd),通过属性的线性组合来进行预测。一般的写法如下: f(x)=w'x+b,因此,线性模型具有很好的解释性(understandability,comprehensibility),参数w代表每个属性在回归过程中的重要程度。
综合
百科
VIP
热门
动态
论文
精华
精品内容
【干货书】面向数据科学的高级线性模型
专知会员服务
54+阅读 · 2021年10月1日
【清华大学王东老师】现代机器学习技术导论,588页pdf,2021 年 11 月 25 日版
专知会员服务
147+阅读 · 2022年2月23日
《可解释的机器学习-interpretable-ml》238页pdf
专知会员服务
208+阅读 · 2020年2月24日
【金融机器学习课程资料】Financial Machine Learning
专知会员服务
119+阅读 · 2019年12月24日
【IJCAI 2019】从可满足性到优化模理论(From Satisfiability to Optimization Modulo Theories),意大利特伦托大学副教授Roberto Sebastiani
专知会员服务
4+阅读 · 2019年8月10日
参考链接
父主题
有监督学习
数据分析
回归分析
子主题
线性回归
Softmax回归
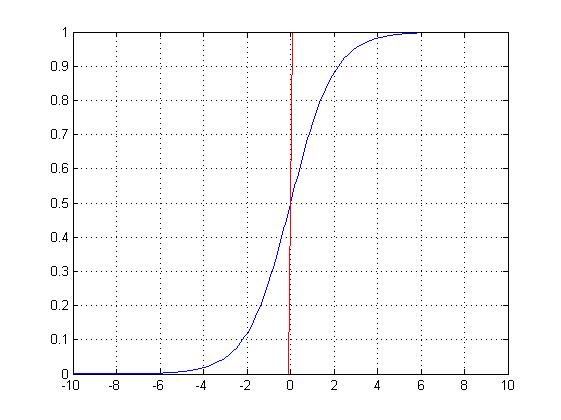
对数几率回归(LR)
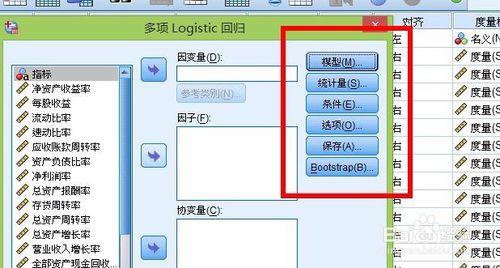
多项逻辑回归
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top