【导读】国际万维网大会(The Web Conference,简称WWW会议)是由国际万维网会议委员会发起主办的国际顶级学术会议,创办于1994年,每年举办一届,是CCF-A类会议。WWW 2020将于2020年4月20日至4月24日在中国台湾台北举行。本届会议共收到了1129篇长文投稿,录用217篇长文,录用率为19.2%。近期,随着会议的临近,有很多paper放出来,几周前专知小编整理了WWW 2020图神经网络(GNN)比较有意思的论文,这期小编继续为大家奉上WWW 2020五篇GNN相关论文供参考——对抗攻击、Heterogeneous Graph Transformer、图生成、多关系GNN、知识库补全。
WWW2020GNN_Part1、AAAI2020GNN、ACMMM2019GNN、CIKM2019GNN、ICLR2020GNN、EMNLP2019GNN、ICCV2019GNN_Part2、ICCV2019GNN_Part1、NIPS2019GNN、IJCAI2019GNN_Part1、IJCAI2019GNN_Part2、KDD2019GNN、ACL2019GNN、CVPR2019GNN、ICML2019GNN
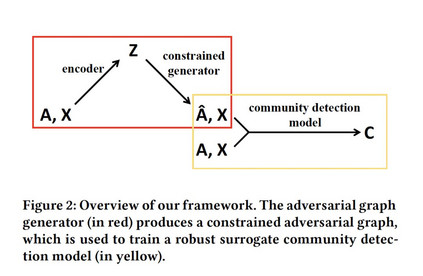
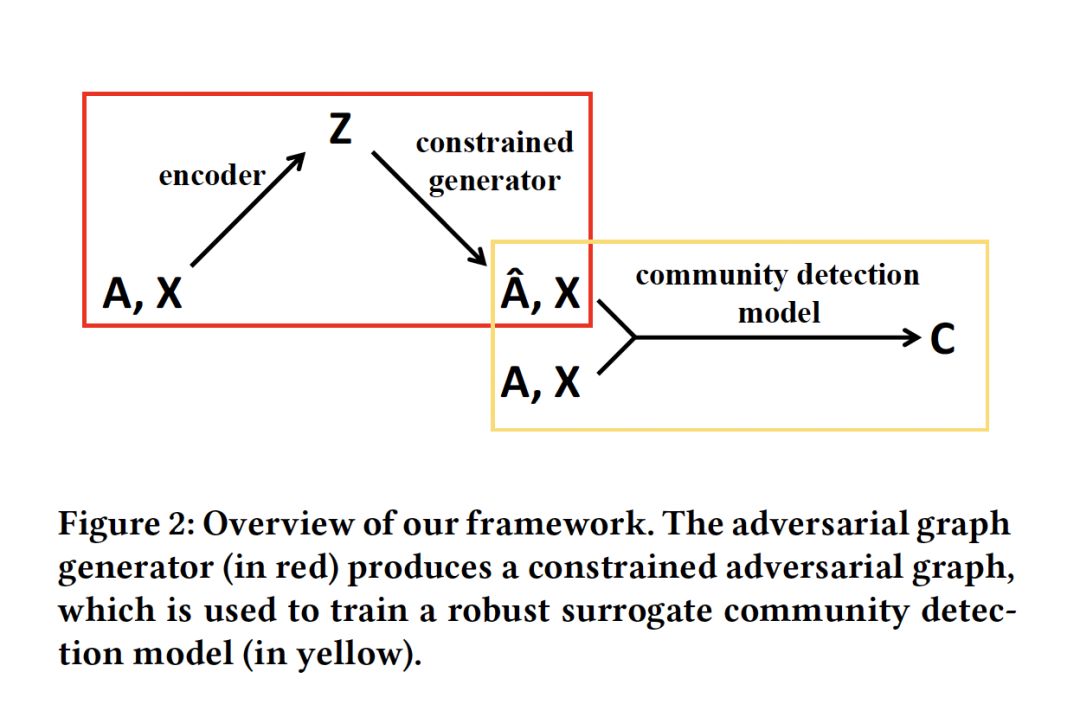
- Adversarial Attack on Community Detection by Hiding Individuals
作者:Jia Li, Honglei Zhang, Zhichao Han, Yu Rong, Hong Cheng and Junzhou Huang
摘要:已经证明,添加了不可察觉扰动的对抗图(adversarial graphs),会导致深层图模型在节点/图分类任务中失败。在本文中,我们将对抗性图扩展到困难得多的社区发现(community detection)问题上。我们关注黑盒攻击,致力于隐藏目标个体,使其不被深度图社区检测模型检测到,该模型在现实场景中有很多应用,例如,保护社交网络中的个人隐私,理解交易网络中的伪装模式。我们提出了一个迭代学习框架,轮流更新两个模块:一个作为约束图生成器,另一个作为替代社区发现模型。我们还发现,我们的方法生成的对抗图可以迁移到其他基于社区发现模型的学习中。
网址:https://arxiv.org/abs/2001.07933
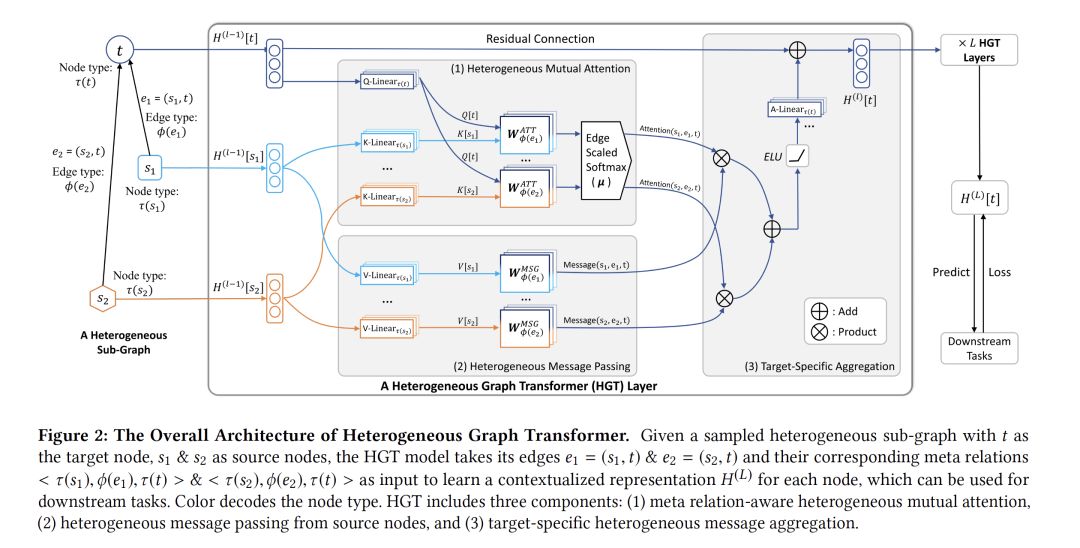
- Heterogeneous Graph Transformer
作者:Ziniu Hu, Yuxiao Dong, Kuansan Wang and Yizhou Sun
摘要:近年来,图神经网络(GNNs)在结构化数据建模方面取得了突飞猛进的成功。然而,大多数GNN都是为同质图(所有的节点和边都属于相同的类型)设计的,这使得这些GNN不能表示异构结构。在这篇文章中,我们提出了异构图转换器(HGT)结构来建模Web规模的异构图。为了建模异构性,我们设计了与节点和边类型相关的参数来表征对每条边的异构关注,使得HGT能够维护不同类型的节点和边的专有表示。为了处理动态异构图,我们将相对时间编码技术引入到HGT中,能够捕获任意持续时间的动态结构依赖关系。为了处理Web规模的图数据,我们设计了异构小批量图采样算法HGSamples,以实现高效和可扩展的训练。在具有1.79亿个节点和20亿条边的开放学术图上的广泛实验表明,本文所提出的HGT模型在各种下游任务上的性能一致地比所有最新的GNN基线高出9%-21%。
代码链接:https://github.com/acbull/pyHGT
- GraphGen: A Scalable Approach to Domain-agnostic Labeled Graph Generation
作者:Nikhil Goyal, Harsh Vardhan Jain and Sayan Ranu
摘要:图生成模型在数据挖掘领域中得到了广泛的研究。传统的技术基于预定义分布的生成结构,而最近的技术已转向直接从数据中学习此分布。虽然基于学习的方法在质量上有了显著的提高,但仍有一些缺点需要解决。首先,学习图的分布会带来额外的计算开销,这就限制了这些方法对大型图数据库的可扩展性。第二,许多方法只学图结构,并没有学习节点和边的标签(这些标签编码重要的语义信息会影响结构自身)。第三,现有技术往往包含领域的特定规则,缺乏通用性。第四,现有方法的实验部分要么使用了较弱的评估指标,要么主要集中在合成数据或小数据集上,实验不够全面上。在这项工作中,我们提出了一种称为GraphGen的域未知(domain-agnostic)技术来克服所有这些缺点,GraphGen使用最少的DFS代码将图转换为序列。最小DFS码是规范化的标签,并且可以精确地捕捉图结构和标签信息。本文通过一种新的LSTM结构学习结构标签和语义标签之间复杂的联合分布。在百万级的真实图数据集上的广泛实验表明,GraphGen的平均速度是最先进方法的4倍,同时在11个不同指标的综合集合中质量明显更好。
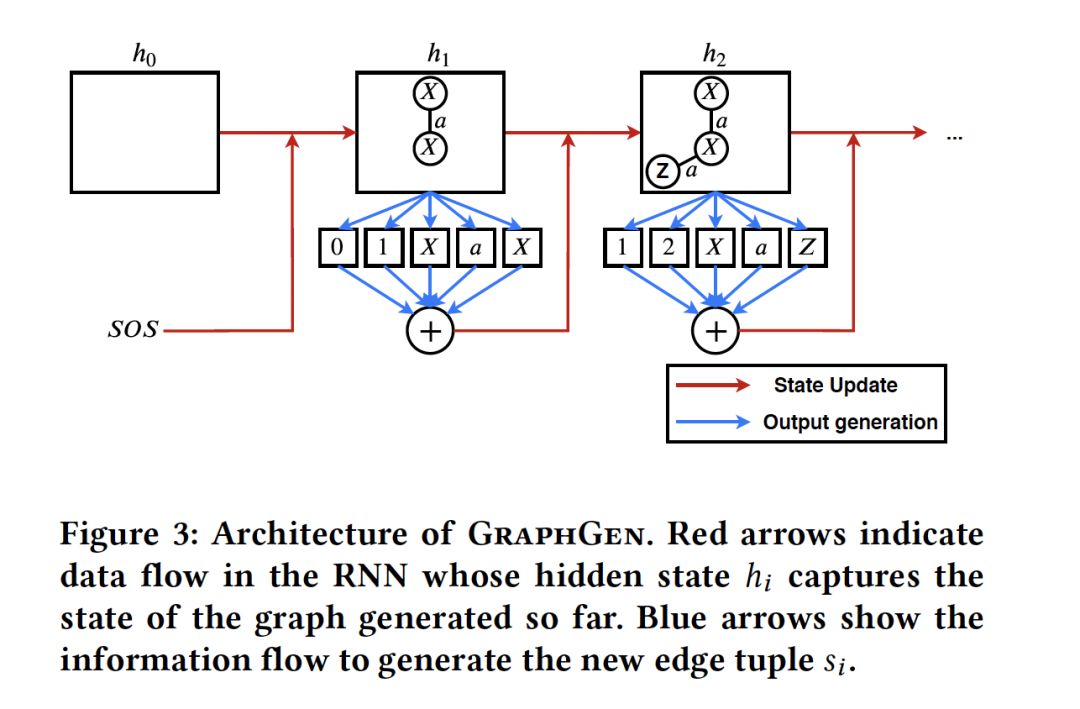
网址:https://arxiv.org/abs/2001.08184
代码链接:
https://github.com/idea-iitd/graphgen
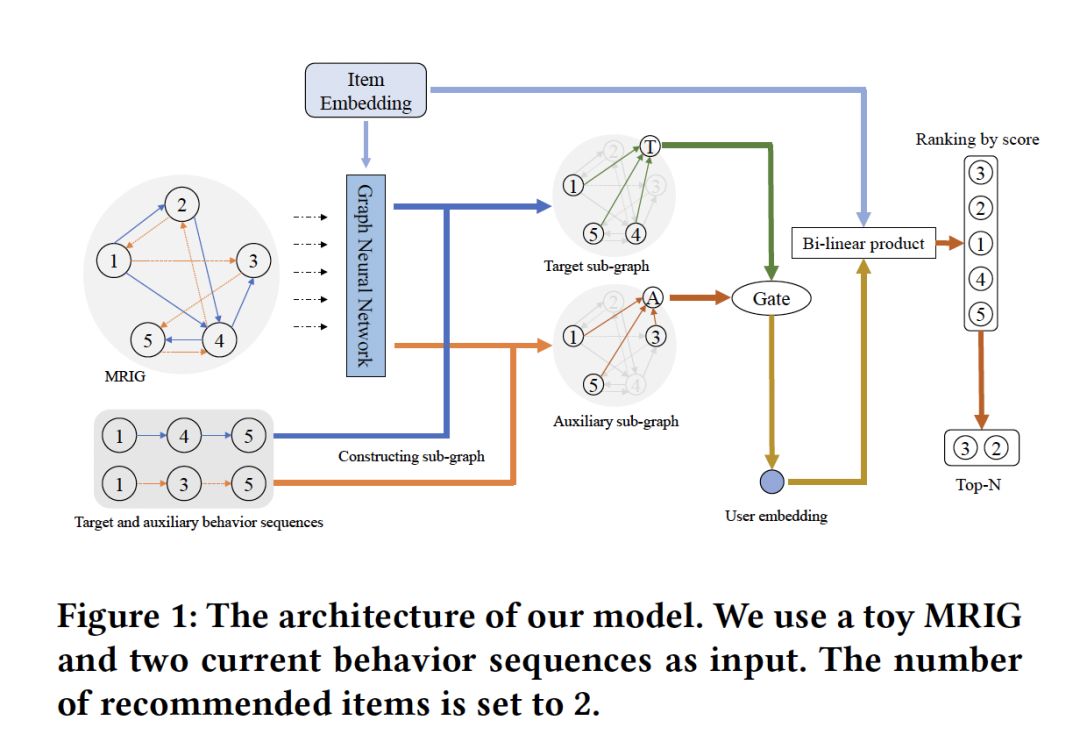
- Beyond Clicks: Modeling Multi-Relational Item Graph for Session-Based Target Behavior Prediction
作者:Wen Wang, Wei Zhang, Shukai Liu, Bo Zhang, Leyu Lin and Hongyuan Zha
摘要:基于会话的目标行为预测旨在预测要与特定行为类型(例如,点击)交互的下一项。虽然现有的基于会话的行为预测方法利用强大的表示学习方法来编码项目在低维空间中的顺序相关性,但是它们受到一些限制。首先,之前的方法侧重于只利用同一类型的用户行为进行预测,而忽略了将其他行为数据作为辅助信息的潜力。当目标行为稀疏但很重要(例如,购买或共享物品)时,辅助信息尤为重要。其次,项目到项目的关系是在一个行为序列中单独和局部建模的,缺乏一种规定的方法来更有效地全局编码这些关系。为了克服这些局限性,我们提出了一种新的基于会话的多关系图神经网络模型(MGNN-SPred)。具体地说,我们基于来自所有会话的所有行为序列(涉及目标行为类型和辅助行为类型)构建多关系项目图(Multi-Relational Item Graph,MRIG)。在MRIG的基础上,MGNN-SPred学习全局项目与项目之间的关系,进而获得用户偏好分别作为为当前目标行为序列和辅助行为序列。最后,MGNN-SPred利用门控机制自适应地融合用户表示,以预测与目标行为交互的下一项。在两个真实数据集上的广泛实验证明了MGNN-SPred与最新的基于会话的预测方法相比的优越性,验证了利用辅助行为和基于MRIG学习项目到项目关系的优点。
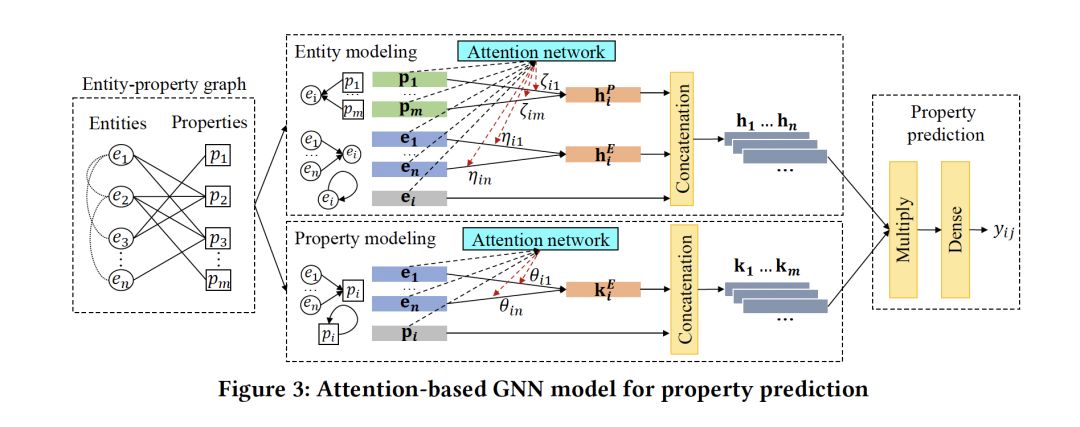
- Open Knowledge Enrichment for Long-tail Entities
作者:Ermei Cao, Difeng Wang, Jiacheng Huang and Wei Hu
摘要:知识库(KBS)已经逐渐成为许多人工智能应用的宝贵资产。虽然目前的许多知识库相当大,但它们被是不完整的,特别是缺乏长尾实体(例如:不太有名的人)。现有的方法主要通过补全缺失连接或补齐缺失值来丰富知识库。然而,它们只解决了充实知识库问题的一部分,缺乏对长尾实体的具体考虑。在这篇文章中,我们提出了一种新颖的知识补齐方法,它从开放的Web中预测缺失的属性并推断出长尾实体的真实值。利用来自流行实体的先验知识来改进每个充实步骤。我们在合成数据集和真实数据集上的实验以及与相关工作的比较表明了该方法的可行性和优越性。
 网址:
网址: