
【导读】国际万维网大会(The Web Conference,简称WWW会议)是由国际万维网会议委员会发起主办的国际顶级学术会议,创办于1994年,每年举办一届,是CCF-A类会议。WWW 2020将于2020年4月20日至4月24日在中国台湾台北举行。由于疫情影响,会议在线上举行。本届会议共收到了1129篇长文投稿,录用217篇长文,录用率为19.2%。上周专知小编整理了WWW 2020 推荐系统相关论文-part2,这期小编继续为大家奉上WWW 2020六篇推荐系统相关论文-part3 供参考——上下文感知推荐、双边公平推荐、MetaSelector、视觉主题推荐、社交影响力。 WWW2020RS_Part2、WWW2020RS_Part1
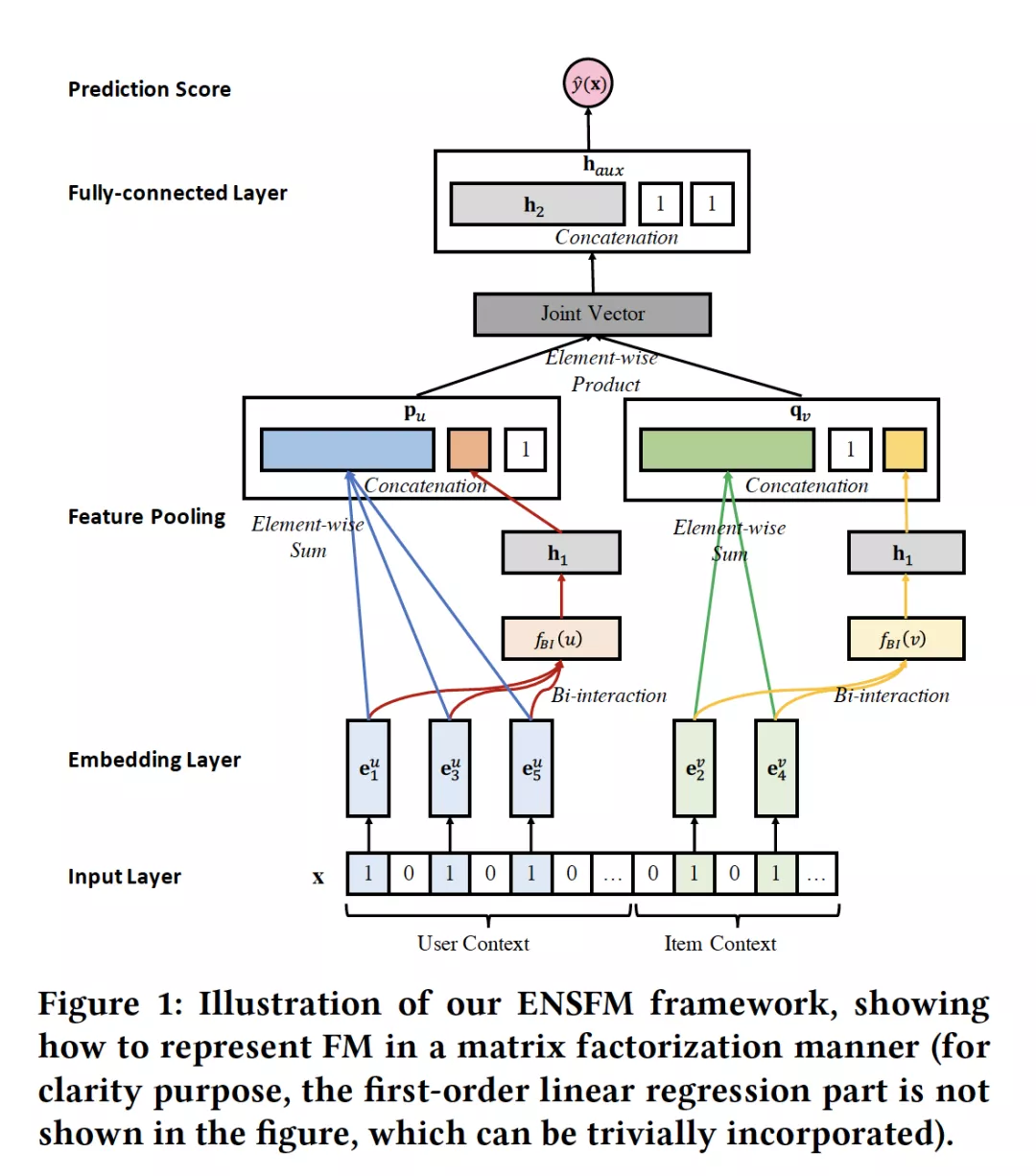
1. Eficient Non-Sampling Factorization Machines for Optimal Context-Aware Recommendation
作者:Chong Chen, Min Zhang, Weizhi Ma, Yiqun Liu, and Shaoping Ma
摘要:为了提供更准确的推荐,在对用户项目交互进行建模之外考虑上下文特征已成为一个热门话题。具有负采样的因子分解机(FM)是一种流行的上下文感知推荐解决方案。然而,由于采样可能丢失重要信息,并且在实际应用中通常会导致非最优性能,因此该算法的鲁棒性不强。最近的一些努力通过使用深度学习框架建模高阶特征交互增强了FM的性能。而他们要么只关注评分预测任务,要么通常采用负采样策略来优化排名效果。由于采样的巨大的波动,我们有理由认为这些基于采样的FM方法对于上下文感知推荐仍然不是最佳的。在本文中,我们提出在不进行采样的情况下学习FM,以有助于上下文感知推荐¬¬的排名任务。尽管这种方法效率很高,但这种非采样策略对模型的学习效率提出了很大的挑战。因此,我们进一步设计了一种新的理想框架--有效非采样样因子分解机(ENSFM)。ENSFM不仅无缝连接了FM和矩阵分解(MF)之间的关系,而且通过新颖的记忆策略解决了具有挑战性的效率问题。通过在三个真实的公共数据集上的大量实验表明:1)我们提出的ENSFM的性能一致且显著优于现有的上下文感知Top-K推荐方法,2)ENSFM在训练效率上具有显著的优势,使其更适用于实际的大系统。此外,实验结果表明,对于Top-K推荐任务,合适的学习方法比先进的神经网络结构更为重要。
网址:
http://www.thuir.cn/group/~mzhang/publications/TheWebConf2020-Chenchong.pdf
代码链接:
https://github.com/chenchongthu/ENSFM
2. FairRec: Two-Sided Fairness for Personalized Recommendations in Two-Sided Platforms
作者:Gourab K Patro, Arpita Biswas, Niloy Ganguly, Krishna P. Gummadi and Abhijnan Chakraborty
摘要:我们在双边在线平台的背景下调查公平推荐(fair recommendation )问题,该平台由一边的客户和另一边的生产商组成。这些平台推荐服务的传统方法侧重于根据个人客户的个性化偏好定制结果,以实现客户满意度的最大化。然而,我们的调查显示,这种以客户为中心的设计可能会导致生产商之间曝光量的不公平分配,这可能会对他们的利益造成不利影响。另一方面,以生产商为中心的设计可能会对客户不公平。因此,我们考虑了客户和生产商之间的公平问题。我们的方法将公平推荐问题映射为一个公平分配不可分割商品问题的新颖映射。我们提出的FairRec算法可确保至少为大多数生产商提供Maximin Share(MMS)的曝光量,并为每个客户提供多达Envy-Free(EF1)的公平性。对多个真实世界数据集的广泛评估显示,FairRec在确保双面公平性的同时,在总体推荐质量方面造成了边际损失的有效性。

网址:
https://arxiv.org/pdf/2002.10764.pdf
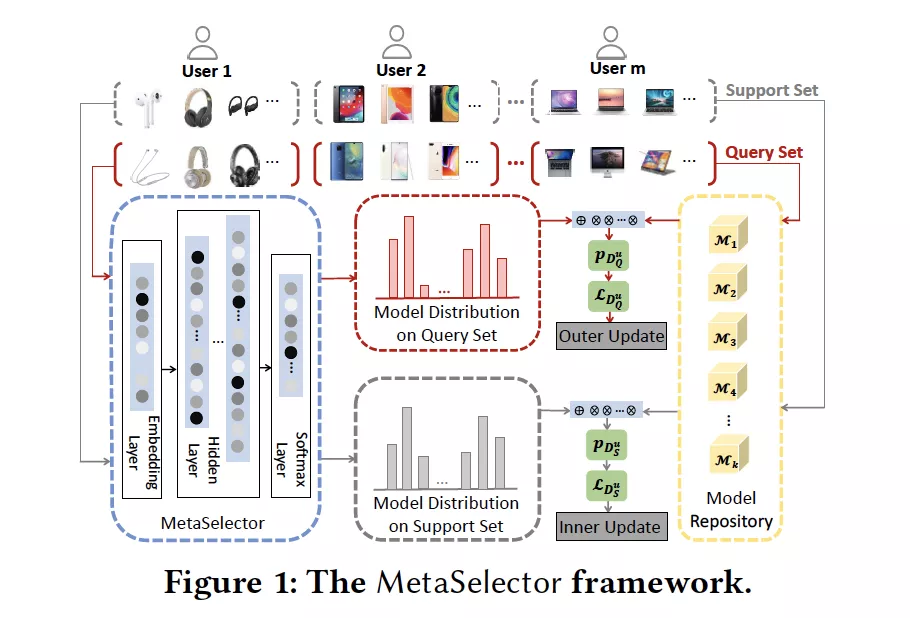
3. MetaSelector: Meta-Learning for Recommendation with User-Level Adaptive Model Selection
作者:Mi Luo, Fei Chen, Pengxiang Cheng, Zhenhua Dong, Xiuqiang He, Jiashi Feng and Zhenguo Li
摘要:推荐系统通常面对包含高度个性化用户历史数据的异构数据集,在这些数据集中,没有哪个模型可以为每个用户提供最佳建议。我们在公共和私有数据集上都观察到了这种普遍存在的现象,并解决了模型选择问题,以追求对每个用户的推荐质量的优化。我们提出了一个元学习框架来促进推荐系统中用户级的自适应模型选择。在此框架中,我们将使用来自所有用户的数据来训练推荐者集合,然后通过元学习对模型选择器进行训练,以使用用户特定的历史数据为每个用户选择最佳的单个模型。我们在两个公共数据集和一个真实的生产数据集上进行了广泛的实验,证明了我们的框架在AUC和LogLoss方面比单一的模型基线和样本级模型选择器都有改进。特别是,当这些改进部署在在线推荐系统中时,可能会带来巨大的利润收益。
网址:
https://arxiv.org/pdf/2001.10378.pdf
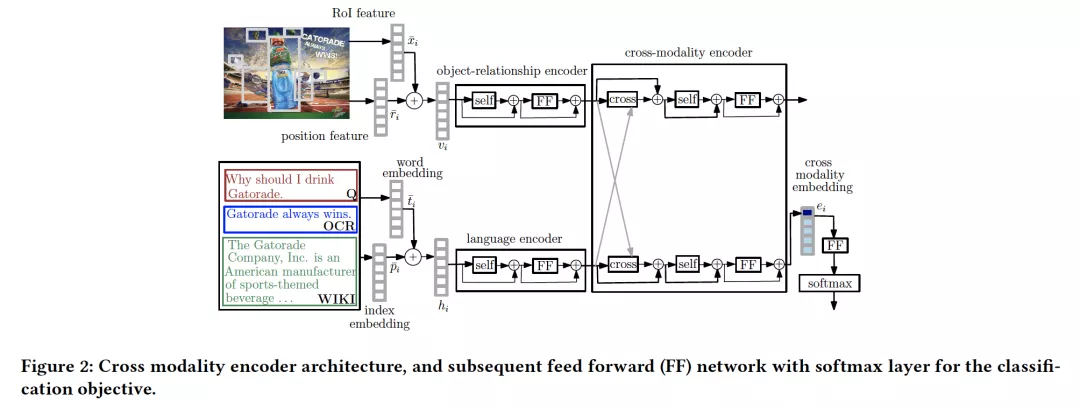
4. Recommending Themes for Ad Creative Design via Visual-Linguistic Representations
作者:Yichao Zhou, Shaunak Mishra, Manisha Verma, Narayan Bhamidipati and Wei Wang
摘要:在线广告行业中经常需要更新广告创意,即用于吸引在线用户进入品牌的图像和文字。进行此类更新,是为了减少在线用户中广告疲劳的可能性,并将其他成功的广告加入到相关产品类别中。对于创意策略师来说,给定一个品牌,为一个新的广告想出主题是一个费时费力的过程。创意策略师来通常从过去广告活动中使用的图像和文字以及有关品牌的知识中汲取灵感。为了在过去的广告活动中通过此类多模态信息自动推断广告主题,我们为广告创意策略师提出了主题(关键词)推荐系统。主题推荐器基于视觉问答(VQA)任务的聚合结果,该任务提取以下内容:(i)广告图像,(ii)与广告关联的文字以及广告中品牌的Wikipedia页面,(iii)有关广告的问题。我们利用基于transformer的跨模态编码器来为VQA任务训练视觉语言表示。我们沿着分类和排序的思路研究了VQA任务的两个公式;通过在公共数据集上的实验,表明跨模态表示显著地提高了分类准确率和排序精准-召回指标。与单独的图像和文本表示相比,跨模式表示显示出更好的性能。此外,与仅使用文本或视觉信息相比,多模态信息的使用表现出显著提升。
网址:https://arxiv.org/pdf/2001.07194.pdf
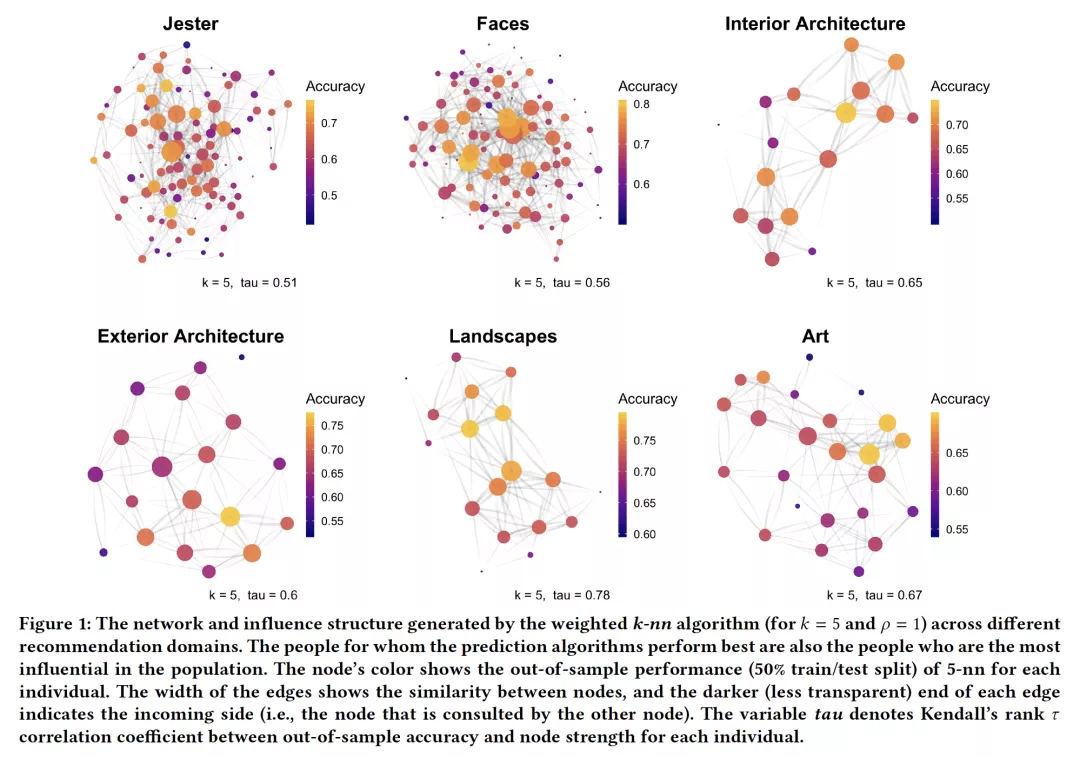
5. The Structure of Social Influence in Recommender Networks
作者:Pantelis P. Analytis, Daniel Barkoczi, Philipp Lorenz-Spreen and Stefan M. Herzog
摘要:人们在品味(taste)上影响他人意见的能力各不相同-既包括离线与在线推荐系统。这些惊人差异背后的机制是什么?使用加权k最近邻算法(k-nn)表示一系列社会学习策略,我们利用网络科学的方法展示了k-nn算法如何在六个现实世界的品味领域中引发社会影响力网络。我们给出了三个新的结果,分别适用于离线建议获取和在线推荐器设置。首先,有影响力的个人具有主流品味,与其他人的品味相似性分散度很高。其次,个人或算法咨询的人越少(即k越低),或者对其他更相似的人的意见给予的权重越大,具有实质性影响的人的群体就越小。第三,对部署k-nn算法后产生的影响网络是分层组织的。我们的结果为通信和网络科学中的经典实证发现提供了新的线索,有助于提高对线下和在线上的社会影响的理解。
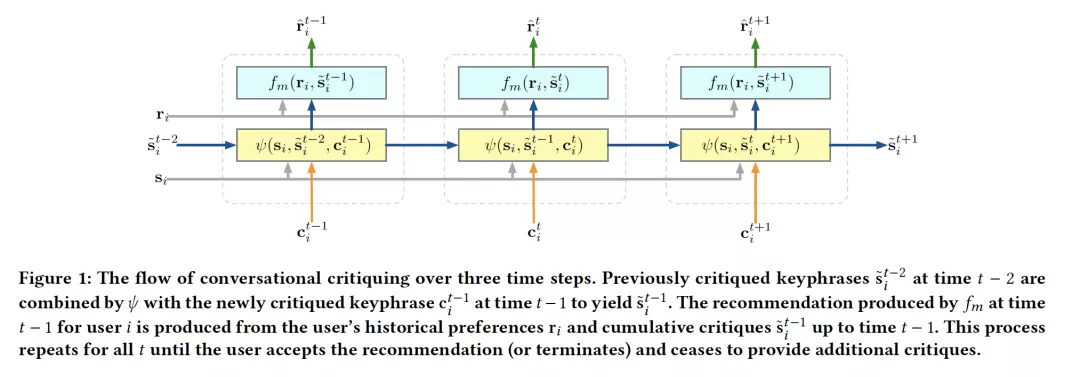
6. Latent Linear Critiquing for Conversational Recommender Systems
作者:PKai Luo, Scott Sanner, Ga Wu, Hanze Li and Hojin Yang
摘要:批判(Critiquing)是一种用于会话推荐的方法,可根据用户的偏好反馈迭代地调整建议。在该设置中,迭代地向用户提供该项目的项目推荐和属性描述;用户可以接受该推荐,或者批判项目描述中的属性以生成新的推荐。之前的批判方法主要基于显式约束和基于实用程序的方法来修改推荐(评判的项目属性)。在这篇文章中,我们回顾了基于潜在嵌入和主观项目描述(即来自用户评论的关键词)的推荐方法时代的批判方法。主要两个关键的研究问题:(1)如何将关键词批判与用户偏好嵌入一起嵌入以更新推荐,(2)如何调节多步骤批判性反馈的强度,其中批判性反馈不一定是独立的,也不一定是同等重要的。为了解决(1),我们构建了一个现有的最先进的线性嵌入推荐算法,以使基于评论的关键词属性与用户偏好嵌入保持一致。为了解决(2),我们利用嵌入和推荐预测的线性结构来建立一个基于线性规划(LP)的优化问题,以确定纳入批评反馈的最优权重。我们在两个包含模拟用户评论的推荐数据集上评估提出的框架。与对批判反馈进行平均的标准方法相比,实验结果表明,我们的方法减少了找到满意项目所需的交互次数,并提高了总体成功率。
网址:
