今日面试题分享:熵、联合熵、条件熵、相对熵、互信息的定义

熵、联合熵、条件熵、相对熵、互信息的定义
参考答案:
解析:
为了更好的理解,需要了解的概率必备知识有:
大写字母X表示随机变量,小写字母x表示随机变量X的某个具体的取值;
P(X)表示随机变量X的概率分布,P(X,Y)表示随机变量X、Y的联合概率分布,P(Y|X)表示已知随机变量X的情况下随机变量Y的条件概率分布;
p(X = x)表示随机变量X取某个具体值的概率,简记为p(x);
p(X = x, Y = y) 表示联合概率,简记为p(x,y),p(Y = y|X = x)表示条件概率,简记为p(y|x),且有:p(x,y) = p(x) * p(y|x)。
熵:如果一个随机变量X的可能取值为X = {x1, x2,…, xk},其概率分布为P(X = xi) = pi(i = 1,2, ..., n),则随机变量X的熵定义为:

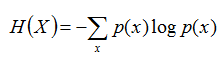
把最前面的负号放到最后,便成了:
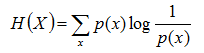
上面两个熵的公式,无论用哪个都行,而且两者等价,一个意思(这两个公式在下文中都会用到)。
联合熵:两个随机变量X,Y的联合分布,可以形成联合熵Joint Entropy,用H(X,Y)表示。
条件熵:在随机变量X发生的前提下,随机变量Y发生所新带来的熵定义为Y的条件熵,用H(Y|X)表示,用来衡量在已知随机变量X的条件下随机变量Y的不确定性。
且有此式子成立:H(Y|X) = H(X,Y) – H(X),整个式子表示(X,Y)发生所包含的熵减去X单独发生包含的熵。至于怎么得来的请看推导:
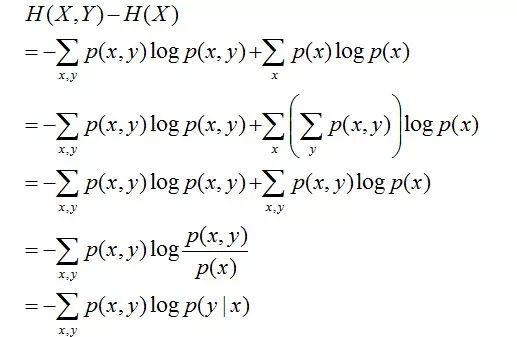
简单解释下上面的推导过程。整个式子共6行,其中
第二行推到第三行的依据是边缘分布p(x)等于联合分布p(x,y)的和;
第三行推到第四行的依据是把公因子logp(x)乘进去,然后把x,y写在一起;
第四行推到第五行的依据是:因为两个sigma都有p(x,y),故提取公因子p(x,y)放到外边,然后把里边的-(log p(x,y) - log p(x))写成- log (p(x,y)/p(x) ) ;
第五行推到第六行的依据是:p(x,y) = p(x) * p(y|x),故p(x,y) / p(x) = p(y|x)。
相对熵:又称互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度等。设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是:
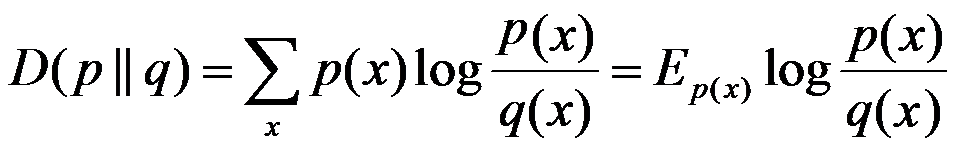
在一定程度上,相对熵可以度量两个随机变量的“距离”,且有D(p||q) ≠D(q||p)。另外,值得一提的是,D(p||q)是必然大于等于0的。 互信息:两个随机变量X,Y的互信息定义为X,Y的联合分布和各自独立分布乘积的相对熵,用I(X,Y)表示:
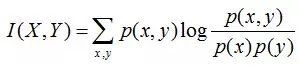
且有I(X,Y)=D(P(X,Y) || P(X)P(Y))。下面,咱们来计算下H(Y)-I(X,Y)的结果,如下:
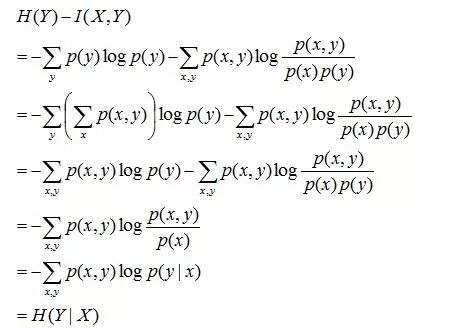
通过上面的计算过程,我们发现竟然有H(Y)-I(X,Y) = H(Y|X)。故通过条件熵的定义,有:H(Y|X) = H(X,Y) - H(X),而根据互信息定义展开得到H(Y|X) = H(Y) - I(X,Y),把前者跟后者结合起来,便有I(X,Y)= H(X) + H(Y) - H(X,Y),此结论被多数文献作为互信息的定义。
更多请查看《最大熵模型中的数学推导》(链接:http://blog.csdn.net/v_july_v/article/details/40508465)
题目来源:七月在线官网(www.julyedu.com)——面试题库——面试大题——机器学习


今日学习推荐
【CV就业班 第一期】

BAT大咖一对一个性化定制辅导
定制学习路线
简历与项目定制 面试辅导与内推
保就业 保高薪 先就业 后付费
又是新一轮金三银四之际
又到了各大企业狂招人的季节
也是跳槽涨薪的最佳时节啦
有意的亲们抓紧时间喽
挑战高薪,玩转AI~
长按识别下方二维码
查看更多课程详情
☟

长按识别二维码
▼
点
咨询,查看课程,请点击“阅读原文”
给我【好看】
你也越好看!




