Transformer是如何横扫自然语言处理排行榜记录的?

更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
本文总结了最近 XLNet 在 Twitter 和线下引发的一些讨论。参与这些讨论的有 Yoav Goldberg、Sam Bowman、Jason Weston、Alexis Conneau、Ted Pedersen,Text Machine Lab 的成员以及其他许多人。对这些讨论如存在任何误解都与我(即本文作者 Anna Rogers)本人有关。
自然语言处理之所以成为一个如此活跃的开发领域,其中一个重要的原因是排行榜:它们是多个共享任务的核心,像 GLUE 这样的基准系统以及单个数据集(如 SQUAD 和 AllenAI)数据集。排行榜刺激了工程团队之间的竞争,帮助他们开发出越来越好的模型来处理人类语言。
或者他们真的这么做了吗?
通常,自然语言处理任务 X 的排行榜看上去大致如下所示:
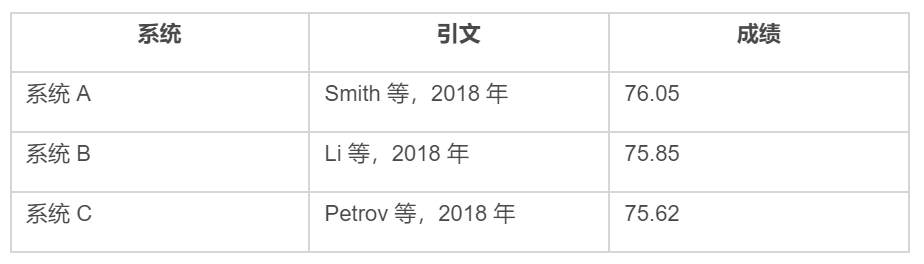
在线排行榜(如 GLUE 基准)和学习论文(将建议的模型与基线进行比较时)都遵循这种格式。
现在,模型的测试和性能远非是使它变得新颖、甚至有趣的唯一因素,但它却是排行榜上唯一的东西。由于深度学习就像是一家具有不同架构的“大型动物园”,因此并没有标准的方法来显示额外的信息,如模型参数、训练数据等。在论文中,这些细节有时出现在方法论部分,有时出现在附录中,又有时出现在 GitHub repo 的评论中,或者根本就没有出现。在在线排行榜中,每个系统的详细信息只能通过论文链接(如果有的话)中检索,或者通过查看存储库中的代码来检索。
在这个日益繁忙的世界中,除非我们正在审查或者重新实施,否则,我们当中会有多少人真正去查看这些细节呢?简单的排行榜已经为我们提供了最关心的信息:谁是 SOTA-ed(当前最优结果)。一般来说,人类的头脑是懒惰的,倾向于全盘接收这样的信息,不加批判,甚至忽略任何警告,即使它们会立即出现(Kahneman,2013 年)。如果我们必须积极地寻找警告的话,好吧,那就没有机会了。在 Twitter 上,赢家会得到扑面而来、天花乱坠的炒作,而且还有可能会 在盲态审核中得到对他人来说不公平的优势。
AI 前线注:SOTA(State Of The Art) 作为衡量标准。很多读者都很熟悉当前最优结果(SOTA),现在的新研究很多都尝试给出更好的 SOTA 结果。而大部分新的最优结果主要关注修正部分结构或给出一些技巧,我们很难判断实际上这样的修正到底重不重要。
人们对以 SOTA 为中心的方法的危害性进行了大量的讨论。如果读者的主要目标是排行榜的话,那就增加了这样一种认知,即只有击败 SOTA,才能实现出版价值。这种认知导致了大量论文的涌现,然而,这些论文大都处于边缘地位,而且往往无法重现(Crane,2018 年)。这也给共享任务带来了巨大的问题:不是获胜者的那些人觉得,花时间写关于他们研究工作的论文,根本不值得(Escartin 等人,2017 年),你也可以看看 Ted Pedersen 最近关于这一问题的讨论。
这篇文章的重点是关于排行榜的另一个问题,这个问题是最近才出现的。其原因很简单:从根本上说,模型可能会比它的竞争对手表现更好:因为模型可以从可用数据中构建更好的表示,或者它可以简单地使用更多的数据,并且(或者)为它投入更深的网络。 当我们有篇论文提出新模型,该模型也使用比它的竞争对手更多的数据 / 计算时,版权归属的问题就变得困难了。
目前最流行的自然语言处理排行榜由基于 Transformer 的模型所主导。BERT(Devlin、Chang、Lee、Toutanova,2019 年)在多个排行榜获得 SOTA 数月之后,在 NAACL 2019 斩获了最佳论文奖。现在的热门话题是 XLNet(Yang 等人,2019 年),据说它在 GLUE 和其他一切基准测试上超过了 BERT。其他 Transformer 包括 GPT-2(Radford 等人,2019 年),ERNIE(Zhang 等人,2019 年),这份名单还在增长。
我们开始面临的问题是,这些模型过于巨大。尽管代码可用,但实际上,重现这些结果或产生任何可比较的结果,都超出了普通实验室的能力。例如,XLNet 针对 320 亿个令牌进行训练,在两天内使用 500 个 TPU 的价格就超过了 25 万美元。即使是对模型进行微调,成本也是越来越昂贵了。
一方面,这种趋势看起来是可以预测的,甚至是不可避免的:拥有更多资源的人会使用更多资源来获得更好的性能。有人甚至争论道:一个巨大的模型证明了它的可扩展性,并实现了深度学习的固有承诺,即能够从更多的信息中学习到更复杂的模式。没有人知道我们实际需要多少数据来解决给定的自然语言处理任务,但数据应该是越多越好,不是吗?如果限制数据的话似乎会适得其反。
根据这个观点来看,从现在开始,只有工业界才有能力进行顶级的自然语言处理研究。学术界将不得不以某种方式来提升他们的水平:要么通过获得更多的资助,要么通过与高性能计算中心合作。人们也欢迎他们转向分析,在行业提供的大型模型或数据集上构建一些东西,或者制作数据集。
然而,就自然语言处理的整体进展而言,这可能并非最好的做法,原因如下。
大型模型的主要问题很简单,就是:
“更多数据和计算 = SOTA”,并不是研究新闻。
如果排行榜想要突出实际进展,我们就需要激励新架构,而不是团队相互超越。显然,大型的预训练模型还是有价值的,但除非作者证明他们的系统在可比数据和计算方面的表现不同于其竞争对手,否则他们展示的是一个模型还是一种资源,我们就不清楚了。
此外,这种研究大部分是不可重复的:没有人会仅仅为了重复 XLNet 训练而耗费 25 万美元。鉴于它的消融研究(ablation study)显示,在 4 个数据集中,有 3 个数据集比 BERT 仅增加了 1~2%(Yang 等人,2019 年),我们实际上并不能确定它的掩蔽策略是否比 BERT 更成功。
AI 前线注:ablation study,消融研究,就是为了研究模型中所提出的一些结构是否有效而设计的实验。比如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是 ablation study。简单地说,消融研究,是指通过移除某个模型或者算法的某些特征,来观察这些特征对模型效果的影响
与此同时,由于更精简模型的任务从根本上来更为艰巨,加上以排行榜为导向的社区只会奖励 SOTA,因此,其发展收到了阻碍。这反过来又会让学术团队失去竞争力,其结果是学生毕业后并不会成为更好的工程师。
最后但并非不重要的一点是,大型的深度学习模型经常被过度参数化(Frankle、Carbine,2019 年;Wu、Fan、Baecski、Dauphin、Auli,2019 年)。例如,较小版本的 BERT 在一些语法测试实验中,反而获得了比较大版本的 BERT 更好的分数(Goldbert,2019 年)。深度学习模型需要大量计算这一事实本身并不一定是一件坏事,但浪费计算对环境来说并不适合(Strubell、Ganesh、McCallum,2019 年)。
自然语言处理排行榜正处于真正的危险之中,我们放弃了重现性的问题,只需观察一个 Google 模型的性能每隔几个月就碾压另一个 Google 模型。为了避免这种情况,排行榜需要作出改变。
原则上,有两种可能的解决方案:
对于特定任务,应该可以 提供一个标准的训练语料库,并将计算量限制在强基线所使用的计算量之内。如果基线本身就类似于 BERT,那么这将激励更好地利用资源的模型的开发。如果系统使用预训练表示(词嵌入、BERT 等),则应将预训练数据的大小考虑进最终得分中。
对于像 GLUE 这样的一系列任务,我们可以 让参与者使用他们想要的任何数据和计算,但要把这些因素考虑进最终得分中。排行榜本身应该立即明确模型相对于其消耗的资源量在基线上的表现的定义。
这两种方法都需要一种可靠的方法来估算计算成本。至少,它可以是任务组织者估计的推理时间。Aleksandr Drozd(RIKEN CCS)建议最好的方法是报告 FLOP(失败)次数,这似乎对于 PyTorch 和 TensorFlow 来说似乎已经是可能的了。也许还可以为共享任务建立一个通用服务,这个服务将接收深度学习模型,在一批数据上训练一个轮数,并为研究人员提供估计。
然而估计训练数据也不是一件简单的事:纯文本语料库的价值应该比带注释的语料库或 Freebase 要低。但是,这应该是可以衡量的。例如,非结构化数据可以被估计为原始令牌数 N,增强 / 解析数据可以被估计为 aN,而结构化数据,如字典,可以估计为 N²。
与上述观点相反的一个观点是,有些模型可能本身就需要比其他模型更多的数据,而且只能在大规模实验中进行公平的评估。但即使在这种情况下,也需要一篇令人信服的论文来证明,新模型比其竞争对手能够“保持”更多的数据,因此仍有必要针对相同的数据对所有模型进行多轮训练。
这是到目前为止的有关排行榜的讨论,还远未结束。
我要强调的是,像 BERT 这样的大型预训练模型是一个不可否认的成就,确实帮助推动了众多任务的最新技术进展。显然,使用任何
但是,如果一篇论文引入了另一个
试想,当明天我们醒来的时候看到一篇论文,论文介绍了一个名为 Don’t-Even-Try-Net(模型名© Olga Kovaleva),这是一种新的架构,在北美的每台计算机上训练一年后,可以在每一项自然语言处理任务上实现超人的性能。即使有源代码,我们也无法验证该论文的这一说法。我们可以使用预训练的权重,但如果没有多次运行消融和稳定性评估的话,作者就不会证明他们的方法具有优越性。从某种意义上说,他们将展现的是一种资源,而不是一个模型。
如果我们要取得实际进展,我们需要确保新系统只有在经过严格的证明之后才能出名和获奖:包括在与基线相同的数据上进行多次训练、消融研究、计算和稳定性评估。这自然就会鼓励更多以假设为导向的研究。例如,XLNet 中的依赖目标看起来真的很有趣,我很想知道它实际上给不同的任务上带来了多大的优势,因为基于依赖的词嵌入被证明用途很有限(Li 等人,2017 年;Lapesa、Evert,2017 年)。
1.Zhang, Z., Han, X., Liu, Z., Jiang, X., Sun, M., & Liu, Q. (2019). ERNIE: Enhanced Language Representation with Informative Entities. ACL 2019. BibTex URL
2.Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R., & Le, Q. V. (2019). XLNet: Generalized Autoregressive Pretraining for Language Understanding. ArXiv:1906.08237 [Cs]. BibTex URL
3.Wu, F., Fan, A., Baevski, A., Dauphin, Y., & Auli, M. (2019). Pay Less Attention with Lightweight and Dynamic Convolutions. International Conference on Learning Representations. BibTexURL
4.Voita, E., Talbot, D., Moiseev, F., Sennrich, R., & Titov, I. (2019). Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. ArXiv:1905.09418 [Cs].BibTex URL
5.Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and Policy Considerations for Deep Learning in NLP. ACL 2019. BibTexURL
6.Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models Are Unsupervised Multitask Learners. OpenAI Blog, 1, 8. BibTex URL
7.Lin, Y., Tan, Y. C., & Frank, R. (2019). Open Sesame: Getting Inside BERT’s Linguistic Knowledge. ArXiv:1906.01698 [Cs]. BibTexURL
8.Li, B., Liu, T., Zhao, Z., Tang, B., Drozd, A., Rogers, A., & Du, X. (2017). Investigating Different Syntactic Context Types and Context Representations for Learning Word Embeddings. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, 2411–2421. Copenhagen, Denmark, September 7–11, 2017. BibTex URL
9.Lapesa, G., & Evert, S. (2017). Large-Scale Evaluation of Dependency-Based DSMs: Are They Worth the Effort? Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL), 394–400. Association for Computational Linguistics. BibTex URL
10.Kahneman, D. (2013). Thinking, Fast and Slow (1st pbk. ed). New York: Farrar, Straus and Giroux. BibTex
11.Jawahar, G., Sagot, B., & Seddah, D. What Does BERT Learn about the Structure of Language? ACL 2019, 8. BibTex
12.Goldberg, Y. (2019). Assessing BERT’s Syntactic Abilities. ArXiv:1901.05287 [Cs]. BibTex URL
13.Frankle, J., & Carbin, M. (2019). The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. International Conference on Learning Representations. BibTex URL
14.Escartín, C. P., Reijers, W., Lynn, T., Moorkens, J., Way, A., & Liu, C.-H. (2017). Ethical Considerations in NLP Shared Tasks. Proceedings of the First ACL Workshop on Ethics in Natural Language Processing, 66–73. https://doi.org/10.18653/v1/W17-1608 BibTex URL
15.Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186. BibTex URL
16.Crane, M. (2018). Questionable Answers in Question Answering Research: Reproducibility and Variability of Published Results. Transactions of the Association for Computational Linguistics, 6, 241–252. https://doi.org/10.1162/tacl_a_00018 BibTex URL
17.Coenen, A., Reif, E., Yuan, A., Kim, B., Pearce, A., Viégas, F., & Wattenberg, M. (2019). Visualizing and Measuring the Geometry of BERT. ArXiv:1906.02715 [Cs, Stat]. BibTex URL
18.Clark, K., Khandelwal, U., Levy, O., & Manning, C. D. (2019). What Does BERT Look At? An Analysis of BERT’s Attention. ArXiv:1906.04341 [Cs]. BibTex URL
作者介绍:
Anna Rogers,研究方向为:计算语言学、认知科学、人工智能和自然语言处理。
原文链接:
https://hackingsemantics.xyz/2019/leaderboards/

你也「在看」吗?👇



