斯坦福新模型刷新纪录:自然语言理解 GLUE 排行榜最高分!

新智元AI技术峰会倒计时4天
新智元将于3月27日在北京泰富酒店举办“2019新智元AI技术峰会——智能云•芯世界”,聚焦智能云和AI芯片发展,重塑未来AI世界格局。
同时,新智元将现场权威发布若干AI白皮书,聚焦产业链的创新活跃,助力中国在世界级的AI竞争中实现超越。
参会二维码:

新智元报道
来源:stanford
编辑:肖琴、大明
【新智元导读】通用语言理解评估基准GLUE排行榜再次刷新,斯坦福大学的Snorkel MeTaL综合得分最高,排名第一,并在其中4项任务刷新了最高性能。该研究整合多个监督信号,将调优发挥到极致!
NLP 领域的进展日新月异,这话并非夸张。
新智元前不久报道了微软提出一个新的多任务深度神经网络模型 MT-DNN,结合了 BERT 的优点,并在 10 大自然语言理解任务上超越了 BERT,在多个流行的基准测试中创造了新的最先进的结果。
今天,通用语言理解评估基准 GLUE 的排行榜再次被刷新,斯坦福 Hazy Research 的模型 Snorkel MeTaL 的 GLUE 基准得分达到 83.2,排名第一位。
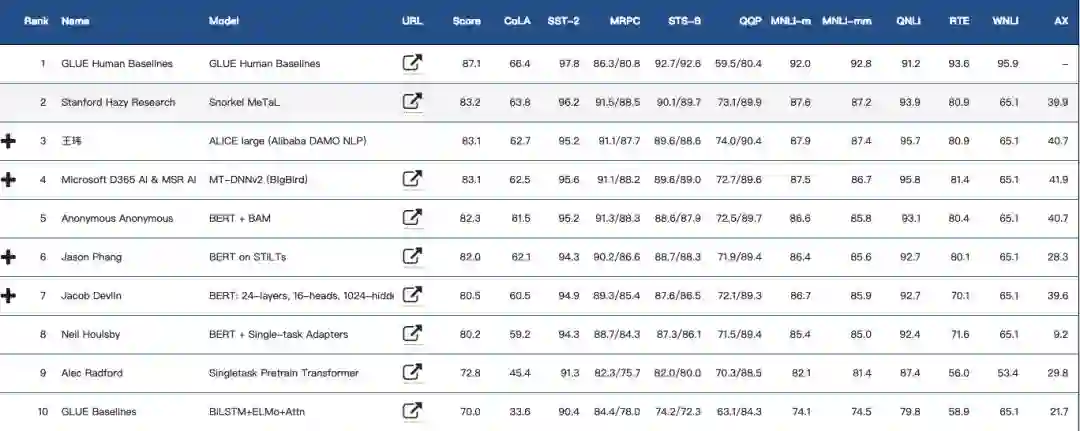
GLUE排行榜前10
模型基于预训练的 BERT-Large,创新之处在于它在一个 Massive Multi-Task Learning (MMTL) 设置中整合了多种监督信号,包括传统监督,迁移学习,多任务学习,弱监督和 ensembling,一点点地将性能推向了最高。
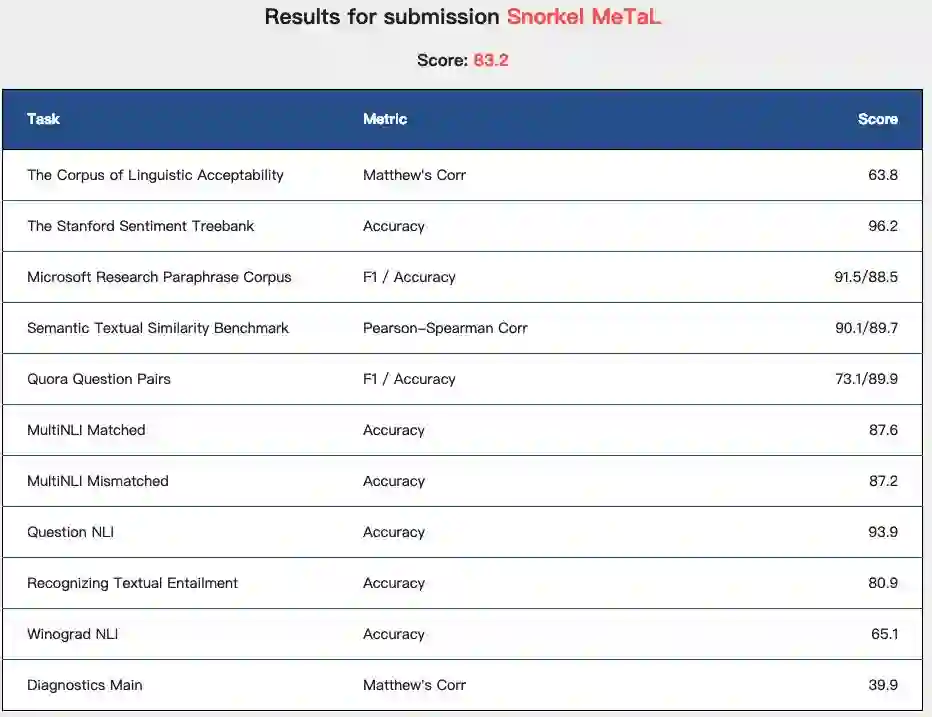
Snorkel MeTaL在GLUE Benchmark上的得分
Snorkel MeTaL 在 GLUE 基准测试中达到了新的 state-of-the-art 分数,并且在 9 个任务中的 4 个 (CoLA, SST-2, MRPC, STS-B) 实现了新的最高性能。
该研究正在进行中,作者表示 MMTL 包的代码版本将于 2019 年 4 月在 Snorkel MeTaL v0.5 中发布。
作者在今天发表的博客文章中详述了他们是如何做到的。
解决监督学习问题需要三个组件:模型、硬件和训练数据。
多亏了研究和开源社区的蓬勃发展,最先进的模型通常只需要一次 pip install (Google,Hugging Face,OpenAI)!多亏了云计算,最先进的硬件也变得越来越容易访问了:一台有 8 个最新最强大的 GPU 的虚拟机,就可以在几分钟内按需启动 (感谢 AWS 和谷歌云)!
然而,要收集足够多的标记数据,在这些硬件上训练这些开源模型,并不像看上去的这么简单。事实上,这个障碍已经成为大多数机器学习应用的主要瓶颈。由于这个原因,越来越多的从业者开始转向更为间接的方式,即将监督信号注入他们的模型中。

最先进的模型架构和硬件正变得越来越商品化,只需几行代码即可访问。然而,获得最先进的训练数据仍然需要相当大的灵活性和创造性。
看到这一趋势,我们开始着手打造一个以监督为主的框架。
我们的目标是尽可能容易地支持目前常用的许多潜在的监督信号来源,包括传统监督、转移学习、多任务学习和弱监督。
我们将这种设置称为大规模多任务学习 (Massive Multi-Task Learning, MMTL),其中有大量不同类型、粒度和标签精度的任务和标签。为了指导我们的开发过程,我们使用了 GLUE Benchmark 作为评估。
GLUE Benchmark 包含 9 个自然语言理解任务 (例如,自然语言推理、句子相似性等)。每个示例都有自己独特的一组示例和标签,大小从 635 个训练示例 (WNLI) 到 393k (MNLI) 不等。
为了保持我们对 ML 监督方面的关注,我们使用了普通硬件 (AWS p3.8xlarge 实例) 和一个非常简单的模型架构 (一个共享的 BERT 模块加上单层线性 task heads)。
因此,我们看到的每一项改进都来自于利用一个新的信号来源,或者更聪明地混合了已有的监督。
本文接下来的部分,我们将通过添加越来越多的监督信号 (supervision signal),逐步了解我们在其中一项任务 RTE (Recognizing Textual Entailment, 文本蕴含识别) 中的得分是如何提高的。
当然,这项工作才刚刚开始;我们希望在 4 月份发布我们的开源框架时,其他人将找到新的和创造性的方法,将更多的信号引入到这个框架中,并进一步推动最新技术的发展!
RTE 数据集附带一个有标签的训练集,包含 2.5k 个示例。该任务的目标是指出第二句是否由第一句所暗示;这被称为文本蕴含任务或自然语言推理 (NLI)。
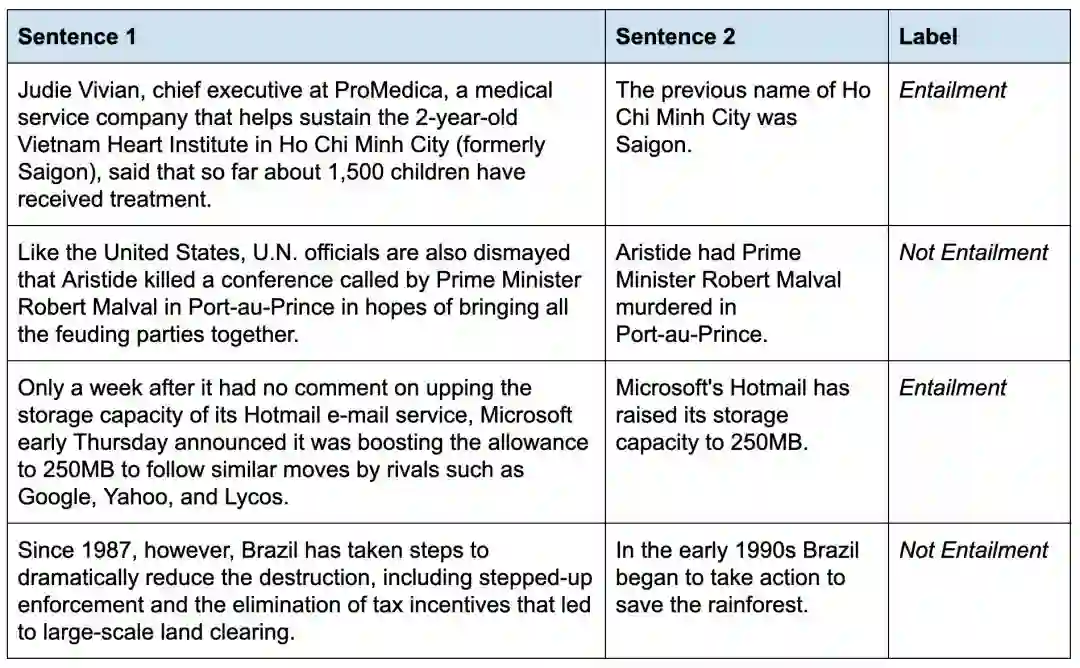
来自 RTE 数据集的示例句子对。标签指示如果句子 1 为真,句子 2 是否必须为真。
我们首先考虑了使用众所周知的 NLP 架构的 baseline。在这个数据集上训练一个标准的 biLSTM 可以得到 57.4 的精度。在顶部添加 ELMo embeddings 一个注意力层,可以将精度提升到 58.9。不幸的是,不管模型架构多漂亮,我们的模型只能从 2.5k 的示例中学到这么多。
我们需要更多信号。💪
2018 年被一些人称为 “自然语言处理的 ImageNet 时刻”。换句话说,正是在这一年,迁移学习真正起飞了,为各种各样的 NLP 任务带来了令人印象深刻的提升。
在这一领域最著名的胜利来自 ULMFit, GPT 的提出,以及 BERT—— 一个庞大的 24 层 transformer 网络,拥有超过 3.4 亿参数,在 4 天内用 256 个 TPU 在 33 亿词汇的语料库上训练!
这些模型都针对某种类型的语言建模任务 (简单地说,就是根据上下文预测下一个单词) 而训练,这已被证明是预训练 NLP 模型的相当可靠的任务选择。
结果表明,为了根据上下文来预测一个单词或句子,理解句法、语法、情感、指代等都是有帮助的;因此,得到的表示通常很丰富,且可用于各种各样的任务。
通过在一个预训练好的 BERT 模块上微调一个线性层,我们看到验证得分从 17.6 分飙升到 76.5 分。RTE 数据集仍然很小,但是通过先在更大的语料库上进行预训练,网络开始微调过程,已经开发了许多有用的中间表示,RTE task head 可以利用这些中间表示。直观地说,这将表示学习的大部分负担转移到了预训练阶段,并允许 task head 更专注于如何将这些中间表示组合到特定任务中。
不过,我们还是想做得更好。
我们需要更多的信号。💪
语言建模可以教模型学会很多事情,但对于在更复杂的任务上获得最佳性能所需的全部事情,语言建模可能无法完全满足要求,比如自然语言推理(NLI)任务可能就需要更深层次的自然语言理解。因此,为了进一步提高 RTE 的性能,需要使用与 RTE 关系更密切的其他任务来完成多任务学习。例如,GLUE 基准测试中的其他三个任务也是 NLI 任务。
我们使用的多任务学习架构非常简单:共享部分(包括全部网络参数的 99.99%)是单个 PyTorch 模块(BERT-Large),每个任务都有一个对应特定任务头的任务线性层。
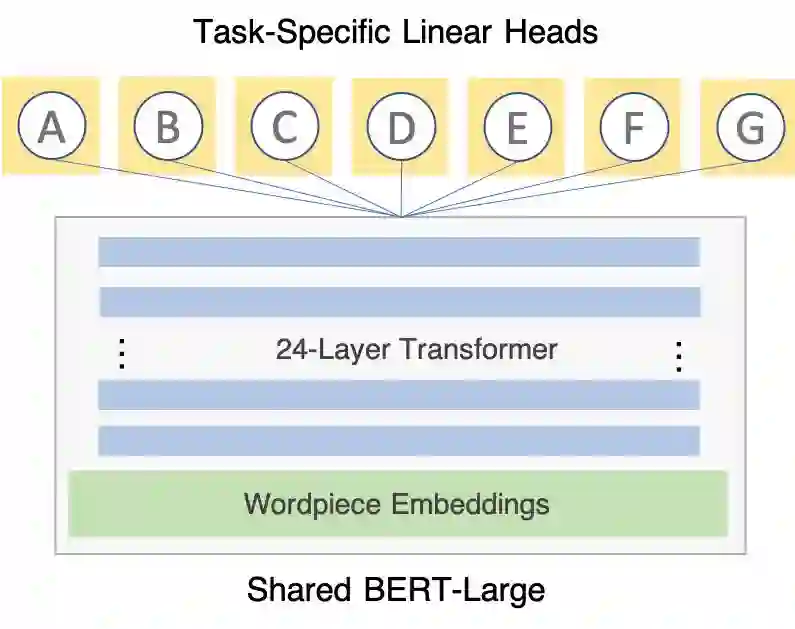
多任务学习架构非常简单:共享部分(包括全部网络参数的 99.99%)是单个 PyTorch 模块(BERT-Large),每个任务都有一个对应特定任务头的任务线性层
多任务学习(MTL)是训练单个模型利用共享表示来预测多个任务的技术。我们认为它是一种监督,而不是架构,真正推动机器学习应用程序的发展,我们保持架构非常简单:我们添加到网络的每个任务只是在 BERT 模块基础上添加一个线性头。这些线性头从预训练的 BERT 模型(1024-dim)的输出维度映射到分类任务的基数(RTE 的 2-dim)。
训练方式也很简单:将所有任务分成几组,随机呈现,然后一次一个地输入网络,这样能够精确观测每个 epoch 内每个任务的每个训练实例。在 10 个 epoch 之后,再利用 5 个 epoc 用最佳检查点对各个任务进行微调,使其能够利用前一阶段的共享信息,并减少后期任务之间的破坏性干扰。仅通过多任务训练,RTE 获得了又一次显著提升(5.8 分),总体验证准确率为 82.3。经特定任务的微调后准确率峰值高达 83.4。
下一步:向大规模多任务学习的扩展
多任务学习的应用范围不应该仅限于其他完整的数据集。Snorkel MeTaL MMTL 软件包专门用于拓展不同监督粒度的多任务学习。因此,它支持任意网络模块、数据类型和标签类型。比如可以将句子标签上的标签与令牌级别的标签混合在一起。
作为一个思想实验,假设错误分析表明,该模型所犯的许多错误源于对语法结构缺乏理解,因此,我们可能会决定增加一些辅助任务,预测现有数据集中由现成分析器产生的那部分词性标签。如果与公共参考精度相关的错误很普遍,我们可能会使用现成的共参考分辨率系统为 MTL 模型生成标签来学习预测。
这些令牌级的标签肯定是不完美的,因为这些标签是另一个存在自偏差、错误模式和盲点的模型的输出。然而,生成这些辅助任务标签的其他模型,通常会在规模非常大的标记数据集上进行训练,这些数据集中有大量可利用的有用信号。虽然排行榜上的结果中仅包括传统多任务学习任务,但我们计划在未来的工作中探索更多的大规模多任务学习任务的空间。
我们需要更多的信号。💪
当我们检查模型的错误时,注意到模型在特定的数据切片上一直表现不佳(“切片” 即与原数据集拥有一些共同属性的部分)。虽然我们的模型在验证集上达到了 83.4 的总体准确度,但在包含不常见的标点符号(如破折号或分号)的实例中的得分仅为 76.7,在具有多代词的示例中仅得到 58.3。这些实例可能确实比一般任务更加困难,但如果对这个特定方向略加关注,应该也能够实现性能的显著提升。
我们使用启发式方法,以编程方式识别属于每个感兴趣数据集部分的训练集中的实例。 (这可以被视为弱监督的另一种形式)。然后,我们在模型的顶部为每个切片添加另一个线性任务头,并仅在属于其各自切片的那些示例上进行训练。这样,网络的一小部分专注于学习表示,有助于提高模型在表现不佳的这部分实例上的性能。
由于我们的大多数网络参数都是在任务之间共享的,因此这些 “启发式调节” 也可以由主任务头用于子任务(通过硬参数共享),从而提升整体的任务准确度。通过这种方式的调整,上文提到的两个任务得分分别从 76.7 和 58.3 分别提高到 79.3 和 75.0,使得整体 RTE 验证得分提高到了 84.1。
我们需要更多的信号。💪
我们发现一些 uncased BERT 模型(对输入所有小写文本进行操作)在我们的一些任务上表现更好,而 cased BERT 模型在其他任务上表现更好。传统观点认为,无框架模型可以减少过拟合,因为更多的原始令牌将映射到相同的嵌入(例如,“Cat” 和 “cat”),导致与其他令牌更频繁地共现,因此训练信号更稀疏。
另一方面,cased 模型可能获得更多的信息,大写字母通常分为首字母缩略词或专有名词。例如,'zip'(紧固)与 ZIP(邮政编码),或 Google(谷歌公司)与 google(动词)。此外,由于预训练 BERT 标记的方式(包含 30k 字组的固定词汇表),每个模型不仅使用不同的权重,而且还可能使用相同句子的不同标记方式。结果是,两个模型具有相当类似的整体性能,但误差桶(error buckets)略有不同。
我们还观察到验证集的过拟合现象,这可能是由于规模过小(只有 276 个实例),因此我们使用不同的训练 / 验证集拆分训练的集合模型。通过六个这样的模型的预测概率,将 RTE 测试分数进一步提高。
我们需要更多的信号。💪
Snorkel 是一个用于快速创建、建模和管理训练数据的系统。 Snorkel MeTaL 是 Snorkel 的多任务版本,用于探索多任务监督和多任务学习。
下个月,我们计划发布 Snorkel MeTaL v0.5,更新内容包括用来实现最先进结果的 MMTL 包。 我们希望这个更新能够成为其他人从事相关工作的基础,采用创造性的新方法将更多的监督信号引入进来,并以智能方式对可用信号进行混合。在接下来的几个月里,我们还将撰写一篇文章,进行更深入的分析和研究。
了解更多内容,可以访问 snorkel.stanford.edu,欢迎在评论、Twitter 和 Github 上提出更多的想法和反馈建议。
参考链接:
https://dawn.cs.stanford.edu/2019/03/22/glue/
【2019新智元 AI 技术峰会倒计时4天】
2019年的3月27日,新智元再汇AI之力,在北京泰富酒店举办AI开年盛典——2019新智元AI技术峰会。峰会以“智能云•芯世界“为主题,聚焦智能云和AI芯片的发展,重塑未来AI世界格局。
同时,新智元将在峰会现场权威发布若干AI白皮书,聚焦产业链的创新活跃,评述AI独角兽影响力,助力中国在世界级的AI竞争中实现超越。
参会二维码
活动行链接:http://hdxu.cn/9Lb5U
点击文末“阅读原文”,马上参会






