Facebook 自然语言处理新突破:新模型能力赶超人类 & 超难 NLP 新基准

更接近人类自然语言理解水平的新基准。
编辑 | 唐里
自然语言理解(NLU)和语言翻译是一系列重要应用的关键,包括大规模识别和删除有害内容,以及连接世界各地不同语言的人们。尽管近年来基于深度学习的方法加速了语言处理的进展,但在处理大量标记训练数据不易获得的任务时,现有系统的处理水平仍然是有限的。
因此,Facebook 联合 Deepmind Technologies、纽约大学(NYU)及华盛顿大学(UW)合作构建新基准 SuperGLUE,并发布了相关内容介绍该高难度测试基准。
SuperGLUE 推出背景
最近,Facebook 人工智能在 NLP 方面取得了重大突破。Facebook 通过使用半监督和自监督学习技术,利用未标记的数据来提高纯监督系统的性能。
在第四届机器翻译大会(WMT19)比赛中,Facebook 采用了一种新型的半监督训练方法,并在多种语言翻译任务中获得了第一名。Facebook 还引入了一种新的自我监督的预训练方法——RoBERTa。它在一些语言理解任务上超过了所有现有的 NLU 系统。在某些情况下,这些系统甚至优于人类基线,包括英德翻译和五个 NLU 基准。
在整个自然语言处理领域,NLU 系统的发展速度如此之快,以至于它在许多现有的基准上已经达到了一个极限。为了继续提高技术水平,Facebook 与 Deepmind Technologies、纽约大学及华盛顿大学合作开发了一套全新的基准、排行榜和 PyTorch 工具包(https://jiant.info/),Facebook 希望这些成果将进一步推动自然语言处理领域的研究进展。
简而言之,这些新工具将帮助人类创建更强大的内容理解系统,而且能够翻译数百种语言,理解诸如含糊不清、共同引用和常识性推理等复杂的问题,从而减少现有的这些系统对大量标记训练数据的依赖性。
翻译准确性的突破
对于神经机器翻译(NMT)模型,有监督式训练通常需要大量附有参考翻译的句子。然而,大量高质量的双语数据并不是普遍可用的,这就要求研究人员使用没有参考翻译的单语数据。反向翻译(Back translation,一种半监督学习技术)允许 Facebook 在一定程度上克服这个问题。
Facebook 最近提交给 WMT 的报告是基于 Facebook 之前在大规模反向翻译方面的工作,这也帮助 Facebook 在去年的同一比赛中赢得了第一名。
而今年,Facebook 引入了一种新的方法,通过生成多个候选译文,并选择最能平衡正向、反向、流畅性三种不同模型分数的译文,来进一步改进 Facebook 的反向翻译系统。
正向模型的分数主要由候选翻译在多大程度上捕捉了原句的意思来衡量;相反,反向模型的分数是通过查看模型能从候选译文中重建出的句子准确性来评判;流畅性模型的分数根据候选翻译流畅性来衡量,最后系统通过观察大量的单语数据以自我监督的方式进行训练;经过对这三个分数的平衡,系统就能够产生显著优化后的翻译结果。
经过几年的努力,Facebook 将英-德语翻译任务的性能提高了 4.5 BLEU(衡量生成的翻译和专业参考之间重叠程度的指标),这是一个很大的改进。根据人工评估,Facebook 的模型在英-德、德-英、英-俄,和俄-英四个翻译任务中排名第一。根据 WMT 赛制的评判,Facebook 的英-德语翻译甚至比人工翻译更佳。
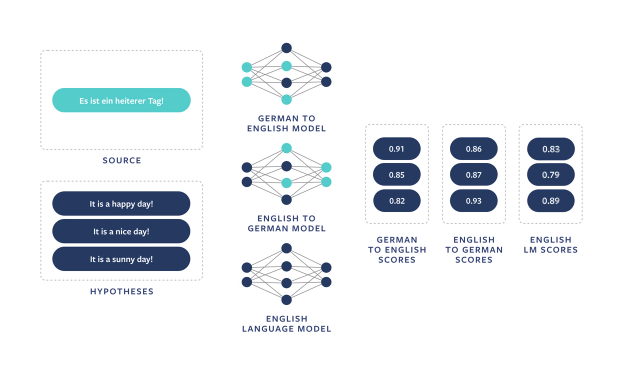
图 1 Facebook 引入的一种新方法
上面的图片展示了这种技术是如何工作的:首先,一个正向模型将一个句子翻译成英语,例如从德语翻译成英语,就会生成一组英语翻译或假设。然后,一个反向模型将这些英语假设翻译回德语,使系统能够评估每个英语翻译与原始德语句子的匹配程度。最后,一个语言模型来判断英语翻译的流畅程度。
Facebook 还将训练扩展到了更大的数据集,包括大约 100 亿个单词用于英语到德语翻译的词汇。与去年相比,Facebook 使用了两倍多的单语数据进行半监督训练,进一步提高了翻译的准确性。更多详情,可以参考 Facebook 人工智能在 2019 年 WMT 国际机器翻译大赛中的表现(https://ai.facebook.com/blog/facebook-leads-wmt-translation-competition/)。
自监督预训练方法的改进
Facebook 最近对自然语言处理(NLP)的最大突破——BERT, 也进行了优化和改进。Google 在 2018 年发布了 BERT。它是革命性的,因为它展示了自监督训练技术的潜力,它具有与传统的标签密集型监督方法的性能相媲美甚至超越它的能力。例如,Facebook 利用 BERT 和相关方法推动对话型人工智能领域的前沿研究,改进内容理解系统,提高低资源和无监督的翻译质量。
因为 Google 开源了 BERT,Facebook 才能够进行一项复制研究,并确定进一步提高其有效性的设计变更。Facebook 引入了稳健优化的 BERT 预训练方法,即 RoBERTa,并取得了新的最先进进展。
RoBERTa 修改了 BERT 中的关键超参数,包括删除 BERT 的下一个句子的预训练目标,并使用更大的批量和学习率进行训练。与 BERT 相比,RoBERTa 的数据总量要多 10 倍以上,因此训练时间也要长得多。这种方法在广泛使用的 NLP 基准测试、通用语言理解评估(GLUE)和阅读理解考试(RACE)上产生了最先进的结果。
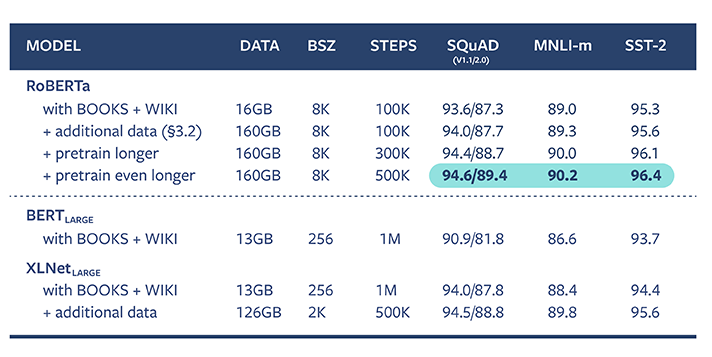
图 2 图表展示了 RoBERTa 在不同任务中的结果
凭借平均得分 88.5 分,RoBERTa 赢得了 GLUE 排行榜的榜首位置,与之前第一名——平均得分为 88.4 分的 XLNet-Large 表现不相上下。RoBERTa 还在一些语言理解基准测试水平上实现了提高,包括 MNLI、QNLI、RTE、STS-B 和 RACE 任务。
这一部分就是 Facebook 不断致力于提高不太依赖于数据标记的自监督系统的性能和潜力的内容。有关 RoBERTa 的更多详细信息,请参考「RoBERTa:预训练自监督 NLP 系统的优化方法(https://ai.facebook.com/blog/roberta-an-optimized-method-for-pretraining-self-supervised-nlp-systems/)」。
NLP 研究的下一个前沿
作为衡量研究进展的行业标准,GLUE 旨在覆盖大量的 NLP 任务,因此只有构建足够通用的工具来帮助解决大多数新的语言理解问题,才能得到良好的表现。
在发布后的一年内,几个 NLP 模型(包括 RoBERTa)已经在 GLUE 基准测试中超过了人类。目前的模型已经提出了一个令人惊讶的有效方法,它将大型文本数据集上的语言模型预训练与简单的多任务和转移学习技术进行了结合。
这种快速的进步是大型人工智能社区内协作的一个功能。上面描述的 NLP 竞赛、基准测试和代码发布使模型复制,改进和最先进结果的更快进步成为可能。随着 GPT 和 BERT 的引入,GLUE 的模型性能急剧提升,现在最先进的模型已经超越了人类的能力,如图 3 所示:
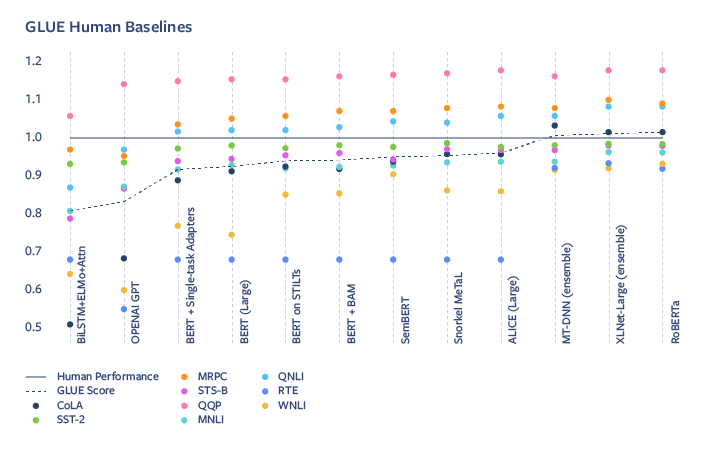
图 3 最先进的自然语言处理模型能力已经超越人类
尽管目前的模型可以在特定的 GLUE 任务上超越人类水平的性能,但它们还不能完美地解决人类解决的一些任务。为了给 NLP 研究设定一个新的更高的标准,facebook 人工智能团队与纽约大学、deepmind 以及华盛顿大学合作构建了 SuperGLUE,这是一个具有全面人类基线的更高难度基准。Facebook 正在推出 SuperGlue,让自然语言理解领域的研究人员能够继续推进最先进的技术。
SuperGLUE 基准测试
最初的基准和新的基准都是由纽约大学发起,与相同的合作伙伴合作创建。SuperGLUE 紧跟 GLUE 的脚步,GLUE 提供了单一的数字度量,用于总结不同 NLP 任务集的进度。除了新的基准之外,Facebook 还发布了一个用于引导研究的排行榜和 pytorch 工具包。
SuperGlue 包含了新的方法来测试一系列困难的 NLP 任务的创造性方法,这些任务主要关注机器学习一些核心领域的创新,包括样本有效性、转移、多任务和自监督学习。为了向研究人员提出挑战,Facebook 选择了格式多样、问题更为微妙、尚未用最先进方法解决但容易被人们解决的任务。为了检查这些任务,Facebook 为许多候选任务运行基于 BERT 的基线,并为人工基线收集数据。
新的基准测试包括八个不同且具有挑战性的任务,其中包括选择合理的替代方案(COPA),一个因果推理任务。在这个任务中,系统被赋予一个前提语句,并且必须从两个可能的选择中确定这个前提语句的因果。值得注意的是,人类在 COPA 上获得了 100% 的准确率,而 BERT 只获得了 74%,这表明 BERT 还有很大的进步空间。
其他独特的前沿组件还包括用于测量这些模型中偏差的诊断工具。例如:winogender,它是为了测试在自动指代消解系统(automated co-reference resolution systems)中是否存在性别偏见而设计的。SuperGlue 还包括一个名为「BoolQ」的问答(QA)任务,其中每个示例都由一个段落和一个关于该段落的是」或「否」问题组成;它是自然问题基准测试中的一个很好的工具。

图 4 该示例表示 SuperGlue 中八个任务中的 1 个。粗体文本表示每个任务示例格式的一部分;斜体文本是模型输入的一部分;带下划线的文本在输入中特别标记;等宽字体中的文本表示预期的模型输出(更多示例请阅读原文)
与 GLUE 类似,新的基准测试还包括一个围绕自然语言理解任务构建的公共排行榜,它利用现有数据,并附带一个单数字性能指标和一个分析工具包。
Facebook 最近针对新的基准测试了 RoBERTa,RoBERTa 在多语言阅读理解(Multientence Reading Comprehension,MultiRC)任务中的表现超过了所有现有的 NLU 系统,甚至超过了人类在该任务上的基线。尽管如此,在许多 SuperGLUE 任务中,RoBERTa 与人类基线之间仍然存在很大差距,这说明了当今最先进的 NLU 系统的一些局限性。
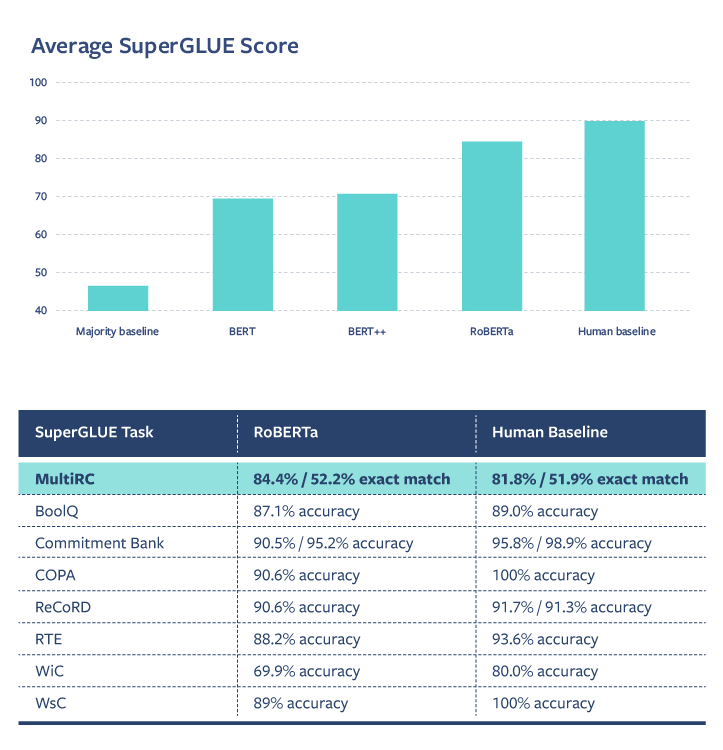
图 5 RoBERTa 在多语言阅读理解任务中表现与其它方法的对比
下一步计划
为了进一步挑战人工智能系统能为人类提供的帮助,Facebook 还引入了第一个长格式的问答数据集和基准测试,它要求机器提供长而复杂的答案——这是现有算法以前从未遇到过的挑战。
目前的问答系统主要集中在一些琐碎的问题上,比如水母是否有大脑。这项新的挑战更进一步,要求机器对开放性问题进行深入的解答,例如「没有大脑,水母如何工作?」现有的算法与人类的表现相去甚远,这一新的挑战将促使人工智能合成来自不同来源的信息,为开放式问题提供复杂的答案。
近期,Facebook 还公布了来自 35 个国家的 115 份获奖提案中的 11 份,并宣布成立人工智能语言研究联盟 (AI Language Research Consortium),这是一个由合作伙伴组成的社区,Facebook 表示将「共同努力,推进 NLP」。
除了与 Facebook 的研究人员就多年项目和出版物进行合作外,人工智能语言研究联盟的成员还有机会获得研究经费,参加年度研究讲习班,参加重要的 NLP 会议。Facebook 表示:「这些 NLP 和机器翻译的研究奖项是我们长期目标的延续,我们希望这个联盟,以及这些 NLP 和机器翻译的研究奖项,会有助于加速 NLP 社区的研究。」
原文链接:
https://ai.facebook.com/blog/new-advances-in-natural-language-processing-to-better-connect-people/
关于人工智能语言研究联盟:
https://venturebeat.com/2019/08/28/facebook-founds-ai-language-research-consortium-to-solve-challenges-in-natural-language-processing/
SuperGLUE 基准地址:
https://super.gluebenchmark.com/





