【泡泡图灵智库】MegaDepth:从海量互联网图片中生成的用于单目深度估计数据集
泡泡图灵智库,带你精读机器人顶级会议文章
标题:MegaDepth: Learning Single-View Depth Prediction from Internet Photos
作者:Zhengqi Li,Noah Snavely
来源:CVPR2018
编译:皮燕燕
审核:杨小育
y欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是—MegaDepth:从海量互联网图片中生成的用于单目深度估计数据集,该文章发表于CVPR2018。
单目深度估计是计算机视觉中的一个基本问题。近年来,深度学习已经取得了重大进展,但是这种方法受到现有训练数据的限制。目前基于3D传感器的数据集有一些局限性,包括仅有室内图像的NYU,具有少量训练实例的Make3D和稀疏采样的KITTI。该论文建议使用多视图互联网照片集,一个几乎无限的数据源,通过现代运动结构和多视图立体(MVS)方法生成训练数据,并基于这个想法构建了一个名为MegaDepth的大型深度数据集。由MVS方法生成的数据带来了自身的挑战,包括噪声和不可构建的对象。我们用新的数据清洗方法解决了这些挑战,并通过使用语义分割生成的序数深度关系自动扩充数据。论文发现基于MegaDepth训练得到的模型具有泛化性,即使不采用其他数据集中的图像,该模型也能用于新的场景,也包括常用的数据集Make3D,KITTI,和DIW。论文通过大量的互联网数据验证了上述结论。
介绍
1、论文基于网络上的图像建立了一个用于单目深度估计的数据集MegaDepth,并介绍了数据集的生成方法。
2、给出了单目深度估计的端对端深度学习算法。
算法流程
1、形成MegaDepth数据集的流程
1.1 论文使用COLMAP对每个从网上收集的图片建立3D模型。采用COLMAP是因为它是一种先进的sfm系统(用于重建相机姿态和稀疏点云)和MVS系统(用于生成稠密的深度图);
1.2 采用两种新的深度细化方法,解决COLMAP形成深度图像中包含很多异常值的问题,旨在生成高质量的训练数据;
1.3 论文提出了三种语义分割的方法用于数据集的创建;
1.4 建立MegaDepth(MD)数据集,链接:http://www.cs.cornell.edu/projects/megadepth/。
2、深度估计网络
2.1 网络结构,评估了VGG,“hourglass”网络以及ResNet,确定“hourglass”网络最佳;
2.2 论文采用尺度不变的损失函数来求解对数域中的深度图并训练。
主要结果
1、 MD数据集的评价以及消融研究
1.1 如图1和图2所示,HG体系结构在三种体系结构中性能最佳,并且与其他损失变量相比,论文提出的联合损失函数的训练的性能显著提升。图3显示,论文提出的联合损失有助于保持深度图的结构,并捕获附近的物体,如人和公共汽车。
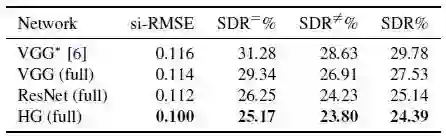
图1 基于MD数据集对不同网络体系结构测试的结果,
数值越低越好
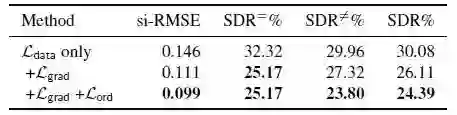
图2 基于MD数据集对不同损失函数测试的结果,
数值越低越好
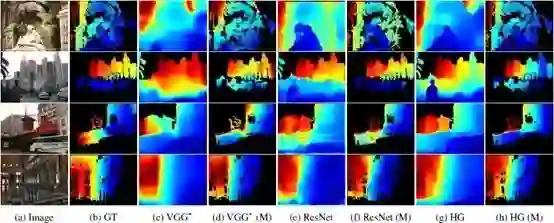
图3 基于MD数据集的深度估计结果
(蓝色:代表近,红色:代表远)
1.2论文基于现有的三个数据集:KITTI、Make3D和DIW对论文提出得基于包含和不包含深度细化的MD数据集训练出来的网络进行了评估。图4的结果表示,在原始MVS深度上训练的网络不能很好地推广,但论文提出的改进显著提高了预测性能。
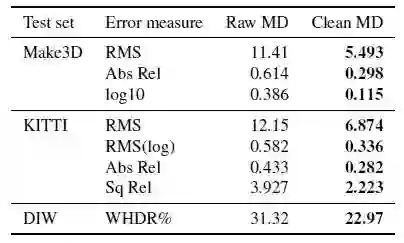
图4在数据集上测试包含和不包含论文深度细化方法的结果。数值越低越好
2、推广到其他数据集
论文提出的三维重建衍生训练数据的强大应用是推广到超越标志性照片的户外图像。为了评估这种能力,论文基于MD训练了模型,并基于三个标准数据集Make3D、KITTI和DIW对模型进行了测试。其中模型训练时采用的数据在标准数据集中没有。
2.1 Make3D
从图5最后一行可以看出,基于论文的模型对Make3D进行微调后的结果,达到了比现有技术更好的性能。图6显示了论文的模型和其他几个非Make3D训练模型的深度估计。结果显示论文的估计可以更好的保留深度图的结构。
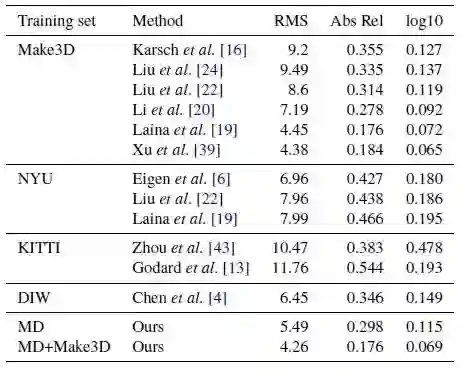
图5 各种训练数据集和模型在Make3D上的测试结果
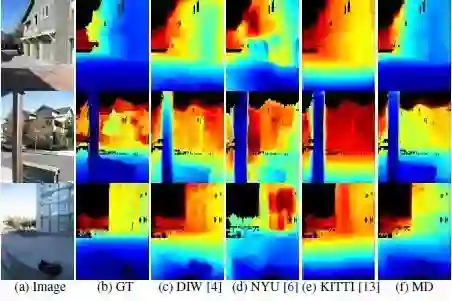
图6 Make3D数据集上深度估计结果
2.2 KITTI
图7的最后一行显示论文可以通过在KITTI培训数据上微调网络来实现最先进的性能。 图8显示了该论文的结果和在其他非KITTI数据集上训练的模型之间的视觉比较。 可以看到,与其他非KITTI数据集相比,该论文的方法获得了更好的视觉质量,而且该论文提出的序列深度损失,论文的估计可以合理捕捉附近的物体,如交通标志,汽车和树木。
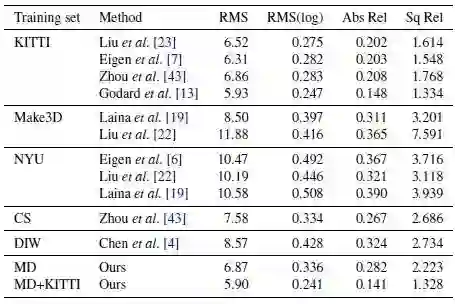
图7 各种训练数据集和方法在KITTI数据集上的试验结果

图8 在KITTI数据集上深度估计结果
2.3 DIW
图9所示的数值结果表示,论文基于MD数据集训练得到的网络在所有非DIW训练模型中具有最好的性能,并达到与陈等人直接在DIW上训练得到的性能相当。图10可视化了该论文的估计和其他非DIW培训网络上的DIW测试图像,结果表明基于该论文的实现了视觉上更好的深度关系。该论文提出的方法甚至对诸如办公室和特写镜头等富有挑战性的场景也能很好地发挥作用。
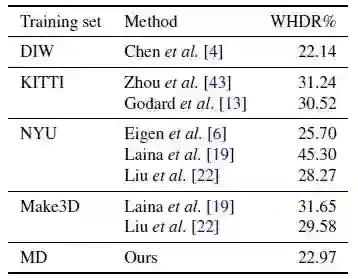
图9 各种训练数据集和方法在DIW数据集上的试验结果
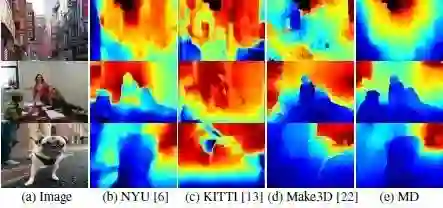
图10 在DIW数据集上深度估计结果

Abstract
Single-view depth prediction is a fundamental problem in computer vision. Recently, deep learning methods have led to significant progress, but such methods are limited by
the available training data. Current datasets based on 3D sensors have key limitations, including indoor-only images (NYU), small numbers of training examples (Make3D), and
sparse sampling (KITTI). We propose to use multi-view Internet photo collections, a virtually unlimited data source, to generate training data via modern structure-from-motion and multi-view stereo (MVS) methods, and present a large depth dataset called MegaDepth based on this idea. Data derived from MVS comes with its own challenges, including noise and unreconstructable objects. We address these
challenges with new data cleaning methods, as well as automatically augmenting our data with ordinal depth relations generated using semantic segmentation. We validate the use
of large amounts of Internet data by showing that models trained on MegaDepth exhibit strong generalization—not only to novel scenes, but also to other diverse datasets including
Make3D, KITTI, and DIW, even when no images
from those datasets are seen during training.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



