【论文推荐】最新九篇机器翻译相关论文—深度多任务学习、深度RNNs、注意焦点、多源神经机器翻译
【导读】专知内容组推出近期九篇机器翻译(Machine Translation)相关论文,欢迎查看!
1.Neural Machine Translation for Bilingually Scarce Scenarios: A Deep Multi-task Learning Approach (神经机器翻译双语言稀缺场景:一种深度的多任务学习方法)
作者:Poorya Zaremoodi,Gholamreza Haffari
NAACL 2018 (long paper)
机构:Monash University
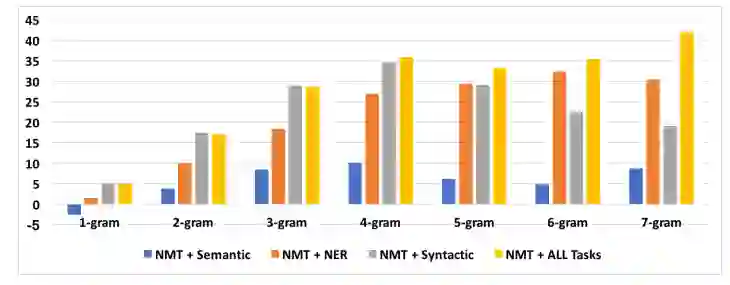
摘要:Neural machine translation requires large amounts of parallel training text to learn a reasonable-quality translation model. This is particularly inconvenient for language pairs for which enough parallel text is not available. In this paper, we use monolingual linguistic resources in the source side to address this challenging problem based on a multi-task learning approach. More specifically, we scaffold the machine translation task on auxiliary tasks including semantic parsing, syntactic parsing, and named-entity recognition. This effectively injects semantic and/or syntactic knowledge into the translation model, which would otherwise require a large amount of training bitext. We empirically evaluate and show the effectiveness of our multi-task learning approach on three translation tasks: English-to-French, English-to-Farsi, and English-to-Vietnamese.
期刊:arXiv, 2018年5月11日
网址:
http://www.zhuanzhi.ai/document/0e10687d2982561db3996316f8d72e8f
2.Deep RNNs Encode Soft Hierarchical Syntax(深度RNNs编码的软层次结构语法)
作者:Terra Blevins,Omer Levy,Luke Zettlemoyer
Accepted to ACL 2018
机构:University of Washington
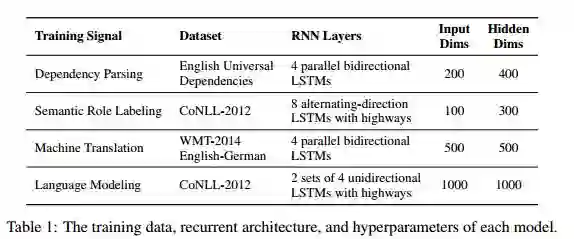
摘要:We present a set of experiments to demonstrate that deep recurrent neural networks (RNNs) learn internal representations that capture soft hierarchical notions of syntax from highly varied supervision. We consider four syntax tasks at different depths of the parse tree; for each word, we predict its part of speech as well as the first (parent), second (grandparent) and third level (great-grandparent) constituent labels that appear above it. These predictions are made from representations produced at different depths in networks that are pretrained with one of four objectives: dependency parsing, semantic role labeling, machine translation, or language modeling. In every case, we find a correspondence between network depth and syntactic depth, suggesting that a soft syntactic hierarchy emerges. This effect is robust across all conditions, indicating that the models encode significant amounts of syntax even in the absence of an explicit syntactic training supervision.
期刊:arXiv, 2018年5月11日
网址:
http://www.zhuanzhi.ai/document/56ed36a253d72ca4658d84345fb6f6d0
3.Attention Focusing for Neural Machine Translation by Bridging Source and Target Embeddings(神经机器翻译时注意的焦点:通过桥接源和目标嵌入)
作者:Shaohui Kuang,Junhui Li,António Branco,Weihua Luo,Deyi Xiong
Accepted by ACL2018
机构:Soochow University,University of Lisbon
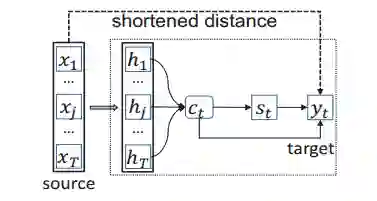
摘要:In neural machine translation, a source sequence of words is encoded into a vector from which a target sequence is generated in the decoding phase. Differently from statistical machine translation, the associations between source words and their possible target counterparts are not explicitly stored. Source and target words are at the two ends of a long information processing procedure, mediated by hidden states at both the source encoding and the target decoding phases. This makes it possible that a source word is incorrectly translated into a target word that is not any of its admissible equivalent counterparts in the target language. In this paper, we seek to somewhat shorten the distance between source and target words in that procedure, and thus strengthen their association, by means of a method we term bridging source and target word embeddings. We experiment with three strategies: (1) a source-side bridging model, where source word embeddings are moved one step closer to the output target sequence; (2) a target-side bridging model, which explores the more relevant source word embeddings for the prediction of the target sequence; and (3) a direct bridging model, which directly connects source and target word embeddings seeking to minimize errors in the translation of ones by the others. Experiments and analysis presented in this paper demonstrate that the proposed bridging models are able to significantly improve quality of both sentence translation, in general, and alignment and translation of individual source words with target words, in particular.
期刊:arXiv, 2018年5月10日
网址:
http://www.zhuanzhi.ai/document/e9f93d67c89e4aed703943a4fc59c275
4.Neural Machine Translation Decoding with Terminology Constraints (神经机器翻译进行有术语限制的译码)
作者:Eva Hasler,Adrià De Gispert,Gonzalo Iglesias,Bill Byrne
roceedings of NAACL-HLT 2018
机构:University of Cambridge
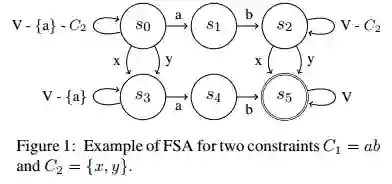
摘要:Despite the impressive quality improvements yielded by neural machine translation (NMT) systems, controlling their translation output to adhere to user-provided terminology constraints remains an open problem. We describe our approach to constrained neural decoding based on finite-state machines and multi-stack decoding which supports target-side constraints as well as constraints with corresponding aligned input text spans. We demonstrate the performance of our framework on multiple translation tasks and motivate the need for constrained decoding with attentions as a means of reducing misplacement and duplication when translating user constraints.
期刊:arXiv, 2018年5月10日
网址:
http://www.zhuanzhi.ai/document/e8d480590bfe2b7fdb856ac914f05036
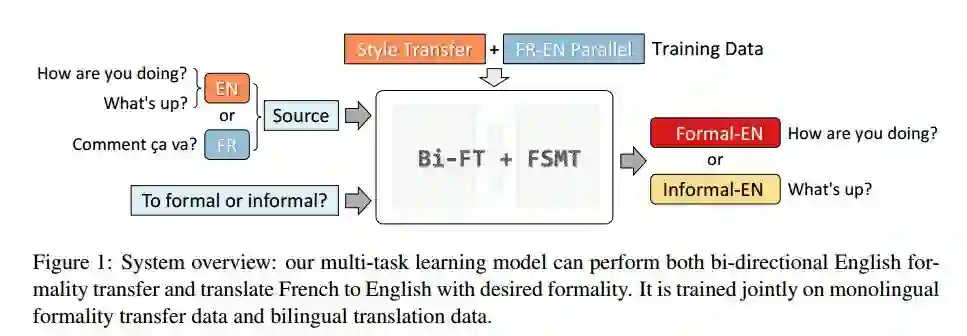
5.Multi-Task Neural Models for Translating Between Styles Within and Across Languages(用于在语言内部和跨语言之间转换样式的多任务神经模型)
作者:Xing Niu,Sudha Rao,Marine Carpuat
Accepted at the 27th International Conference on Computational Linguistics (COLING 2018)
机构:University of Maryland
摘要:Generating natural language requires conveying content in an appropriate style. We explore two related tasks on generating text of varying formality: monolingual formality transfer and formality-sensitive machine translation. We propose to solve these tasks jointly using multi-task learning, and show that our models achieve state-of-the-art performance for formality transfer and are able to perform formality-sensitive translation without being explicitly trained on style-annotated translation examples.
期刊:arXiv, 2018年6月12日
网址:
http://www.zhuanzhi.ai/document/068c4a9799857d7e722436ce60686062
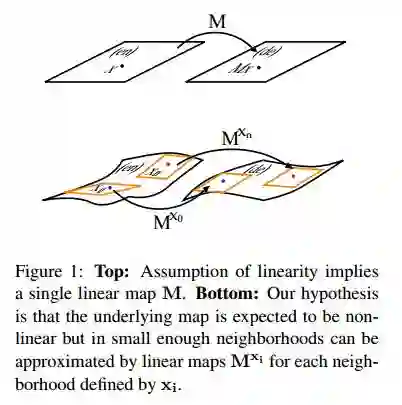
6.Characterizing Departures from Linearity in Word Translation
(描述词翻译中偏离线性的特征)
作者:Ndapa Nakashole,Raphael Flauger
ACL 2018
机构:University of California
摘要:We investigate the behavior of maps learned by machine translation methods. The maps translate words by projecting between word embedding spaces of different languages. We locally approximate these maps using linear maps, and find that they vary across the word embedding space. This demonstrates that the underlying maps are non-linear. Importantly, we show that the locally linear maps vary by an amount that is tightly correlated with the distance between the neighborhoods on which they are trained. Our results can be used to test non-linear methods, and to drive the design of more accurate maps for word translation.
期刊:arXiv, 2018年6月8日
网址:
http://www.zhuanzhi.ai/document/1102be106e8bb7a6aebf2d34311bc61f
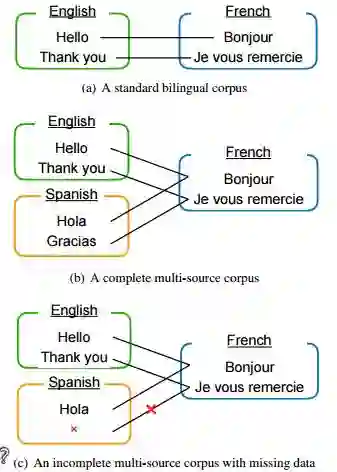
7.Multi-Source Neural Machine Translation with Missing Data(多源神经机器翻译与缺失数据)
作者:Yuta Nishimura,Katsuhito Sudoh,Graham Neubig,Satoshi Nakamura
ACL 2018 Workshop on Neural Machine Translation and Generation
机构:Carnegie Mellon University
摘要:Multi-source translation is an approach to exploit multiple inputs (e.g. in two different languages) to increase translation accuracy. In this paper, we examine approaches for multi-source neural machine translation (NMT) using an incomplete multilingual corpus in which some translations are missing. In practice, many multilingual corpora are not complete due to the difficulty to provide translations in all of the relevant languages (for example, in TED talks, most English talks only have subtitles for a small portion of the languages that TED supports). Existing studies on multi-source translation did not explicitly handle such situations. This study focuses on the use of incomplete multilingual corpora in multi-encoder NMT and mixture of NMT experts and examines a very simple implementation where missing source translations are replaced by a special symbol
期刊:arXiv, 2018年6月7日
网址:
http://www.zhuanzhi.ai/document/c577551664f87c9351d263672d121362
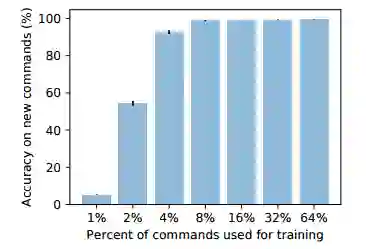
8.Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks(无系统性的泛化:论序列-序列递归网络的构成技巧)
作者:
摘要:Humans can understand and produce new utterances effortlessly, thanks to their compositional skills. Once a person learns the meaning of a new verb "dax," he or she can immediately understand the meaning of "dax twice" or "sing and dax." In this paper, we introduce the SCAN domain, consisting of a set of simple compositional navigation commands paired with the corresponding action sequences. We then test the zero-shot generalization capabilities of a variety of recurrent neural networks (RNNs) trained on SCAN with sequence-to-sequence methods. We find that RNNs can make successful zero-shot generalizations when the differences between training and test commands are small, so that they can apply "mix-and-match" strategies to solve the task. However, when generalization requires systematic compositional skills (as in the "dax" example above), RNNs fail spectacularly. We conclude with a proof-of-concept experiment in neural machine translation, suggesting that lack of systematicity might be partially responsible for neural networks' notorious training data thirst.
期刊:arXiv, 2018年6月6日
网址:
9.How Do Source-side Monolingual Word Embeddings Impact Neural Machine Translation? (源端单语词嵌入如何影响神经机器翻译?)
作者:
机构:Johns Hopkins University
摘要:
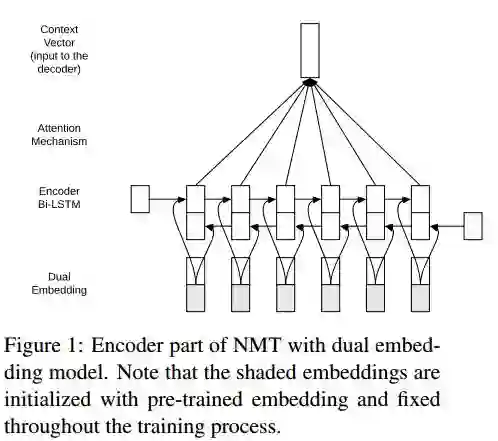
期刊:arXiv, 2018年6月5日
网址:
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知


