学界 | 对抗式协作:一个框架解决多个无监督学习视觉问题
选自arXiv
作者:Anurag Ranjan等
机器之心编译
参与:李诗萌、张倩
本文引入了一个促进神经网络竞争与协作的框架——对抗式协作,并将几个低级视觉中相关联的无监督学习问题(单目深度预测、摄像机运动估计、光流和在静态场景和动态场景中对视频进行分割)集成在该框架中进行解决。该方法在没有任何监督的情况下训练而成,在无监督学习的方法中达到了当前最优水平。
深度学习方法已经在使用大量数据进行监督的计算机视觉问题上取得了优秀成果 [10,17,19]。然而,对许多需要密集连续值输出的视觉问题而言,全面收集真实数据繁琐或不切实际 [6]。本文主要针对以下四个问题:单目深度预测、摄像机运动估计、光流和运动分割。之前的研究已经试着用真实数据 [5] 和合成数据 [4] 通过监督学习解决这些问题。然而在真实数据和合成数据间还是存在现实差距,真实数据不仅有限,而且不准确。例如,一般用 LIDAR 获取的深度真实数据 [6] 是稀疏的。此外,也没有可以提供真实光流数据的传感器,所以所有现有的存有真实图像的数据集都有其局限性或类似 [2,6,12]。运动分割真实数据需要手动标记一张图中所有的像素 [23]。

图 1:网络 R=(D,C) 通过估计静态区域光流解释场景。光流网络 F 估计整张图上的流量。运动分割 M 屏蔽掉来自 F 的静态场景的像素,以在完整图像上产生复合光流。相邻帧应用复合流的损失 E,联合训练这些网络。
近期的研究都试图解决无监督学习方法中训练数据有限的问题 [13,22]。在缺少真实数据的情况下学到从像素到光流、深度和摄像机运动的映射是巨大的挑战,因为这些问题中的每一个都非常模糊。为了解决这一问题,就需要额外的限制,以及利用静态场景、摄像机运动和光流的相关几何内容。例如,将深度无监督学习和摄像机运动耦合起来 [20,33]。他们使用可解释的掩码屏蔽那些不能通过静态空间假设解释的环境。Yin 等人 [32] 对这种方法进行扩展,以评估光流并使用前后一致的方法解释未解释的像素。这些方法在深度基准集和光流基准集中的表现都不太好。一个关键原因是这里应用的约束无法分辨或分割像人类和车辆这样独立移动的目标。另一个原因是,一般而言不是所有未标记的训练集中的数据都符合模型假设,而这些数据中的一些可能会使网络的训练毁于一旦。例如,深度的训练数据和摄像机运动不应该包含独立移动的目标。相似的,对光流而言,数据也不应该包含遮挡,这会破坏光度损失。
想法。一个典型的真实世界场景包括在物理世界中不移动的静态区域以及移动的目标。根据深度和摄像机运动,我们可以解释视频序列中的静态场景。相比之下,光流可以解释场景中所有部分。运动分割将一个场景分类为静态区域和动态区域。我们的主要观点是,通过场景的几何学和运动将这些问题结合起来,从而协同联合解决这些问题。我们发现在从未标记的数据中联合学习后,我们的耦合网络可以只使用有效的数据集并对数据集进行分区,与分别解决这些问题相比,我们的网络可以得到更准确的结果。
方法。为了解决联合无监督学习的问题,我们引入了对抗式协作(Adversarial Collaboration,AC),这是一个通用框架,在这个框架中网络通过学习协作和对抗从而完成特定的目标。对抗式协作是一种有两方对立争取一种资源的三方游戏,这种资源由调解方(moderator)监管。如图 1 所示,我们在框架中引入两方对抗方,静态场景重建器 R=(D,C)使用深度和摄像机运动解释了静态场景像素;动态区域重建器 F 解释了独立移动区域的像素。对抗方通过解释一段图像序列中静态场景和动态区域的像素争取训练数据。对抗由运动分割网络 M 调解,该网络分割静态场景和运动区域,并将训练数据分配给对手。不过,调解方也需要接受训练,以确保公平竞争。因此,对抗方 R、F 联合起来训练调解方 M,使 M 在训练周期的交替阶段可以对静态区域和动态目标进行正确的分类。从思想上讲,这个通用框架与期望最大化(Expectation-maximization, EM)类似,但这是专门为神经网络训练制定的。
贡献。我们的贡献总结如下:1)引入无监督学习框架——对抗式协作,在这个框架中网络可以为达到不同目标而扮演对抗者和协作者;2)这个框架中的联合训练网络对它们的表现有协同效应;3)据我们所知,本文所述方法是第一个在没有任何监督的情况下使用诸如深度、摄像机运动和光流这样的低等级信息解决分割任务的方法;4)在单目深度预测、摄像机运动评估以及光流评估问题中,该方法在无监督学习方法中表现最佳。我们甚至比许多使用更大的网络的竞争方法 [32] 和像网络级联这样采用多个细化步骤的方法 [22] 的表现更好。模型和代码可以在 GitHub(https://github.com/anuragranj/ac)中获取。

图 2:对抗式协作的训练周期:调解方 M 驱动对抗者 {R, F} 之间的竞争(第一阶段,左图)。之后,两个对抗者协同,训练调解方从而确保可以在下一个迭代中公平竞争(第二阶段,右图)。

图 3:第一行从左到右分别表示图像、估计的深度映射、表示运动分割的软掩码。第二行从左到右分别表示静态场景的光流、在运动区域中分割的光流以及全光流。

算法 1:网络训练算法

表 1:深度评估的结果。第一块表示有监督方法。数据参考训练数据 cityscapes(cs) 和 KITTI(k)。Zhou el al.*在他们的 GitHub 中更新了结果。
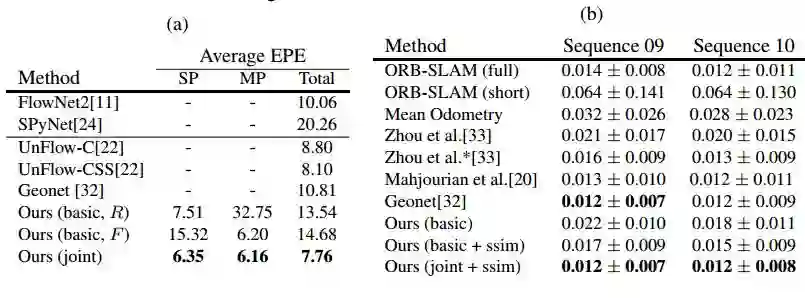
表 2:光流(a)和摄像机运动估计(b)的结果。(a):SP 指静态场景的像素,MP 指动态区域的像素。我们也与有监督方法进行了比较,FlowNet2 和 SpyNet 没有对 KITTI 真实数据流进行微调。

表 3:运动分割结果。在 KITTI2015 训练数据集图像中所有的汽车像素计算出的交并比(IoU)得分。
论文:Adversarial Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation

论文链接:https://arxiv.org/pdf/1805.09806.pdf
我们解决了几个低级视觉中相关联的无监督学习问题:单目深度预测、摄像机运动估计、光流和在静态场景和动态场景中对视频进行分割。我们的关键性看法是这四个基本的视觉问题都是相关的,因此,一起解决它们可以简化问题,因为通过利用已知的几何约束可以使这些问题的解决方法相互补充。为了对几何约束建模,我们引入对抗式协作,这是一个促进神经网络竞争与协作的框架。通过几何学的利用,我们在静态场景和动态区域的辨别和分割方面超越了之前的研究。对抗式协作的原理与期望最大化很像,但是包含充当竞争方的神经网络,竞争方争相解释与静态和动态区域对应的像素,同时也作为训练决定像素是静态还是动态的调解方的协作方。我们的新方法将所有这些问题都集成在一个共同的框架中,同时解释了场景的分割(移动的目标还是静态的背景)、摄像机运动、静态场景结构的深度以及移动目标的光流。我们的方法是在没有任何监督的情况下训练的,与此同时该方法在无监督学习的方法中达到了当前最优水平。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


