扩散模型又杀疯了!这一次被攻占的领域是...

文 | Yimin_饭煲
从2020年的初出茅庐,到2021年的日趋火热,再到2022年的大放异彩,扩散模型(Diffusion Models) 正在人工智能学术界和工业界获取越来越多的关注。
如果还不是特别了解扩散模型的朋友,可以阅读卖萌屋的几篇历史推文《扩散模型在图像生成领域大火,风头超过GAN?》,《年末回顾:2021年 AI 领域十大研究趋势及必读论文》。
扩散模型最早在图像生成领域大火,随后扩展到了其他连续域,例如语音、视频、点云数据,最近Google发布的用于文本到图像生成的GLIDE模型,更是让扩散模型从AI圈内火到了圈外。
不过,虽然扩散模型的热度极高,但是面向离散变量的扩散模型的性能一直欠佳,特别是在语言,图等结构当中。
最近,斯坦福大学自然语言处理研究组在利用扩散模型解决自然语言处理问题中取得了新的进展。
具体说来,在可控自然语言生成任务上,研究者们利用连续扩散模型,对预训练的语言生成模型进行可插拔的操控,就能够在许多任务上达到甚至超过Fine-Tuning的效果,大幅度超越了之前的工作。
这篇工作从方法和实验上都非常的新颖和扎实,短短一周就已经在Twitter上收获了千赞,在Github上收获了140个stars。
下面,就让我们一起来了解这篇扩散模型在语言领域的应用工作吧,说不定也能给你的领域带来启发呢~
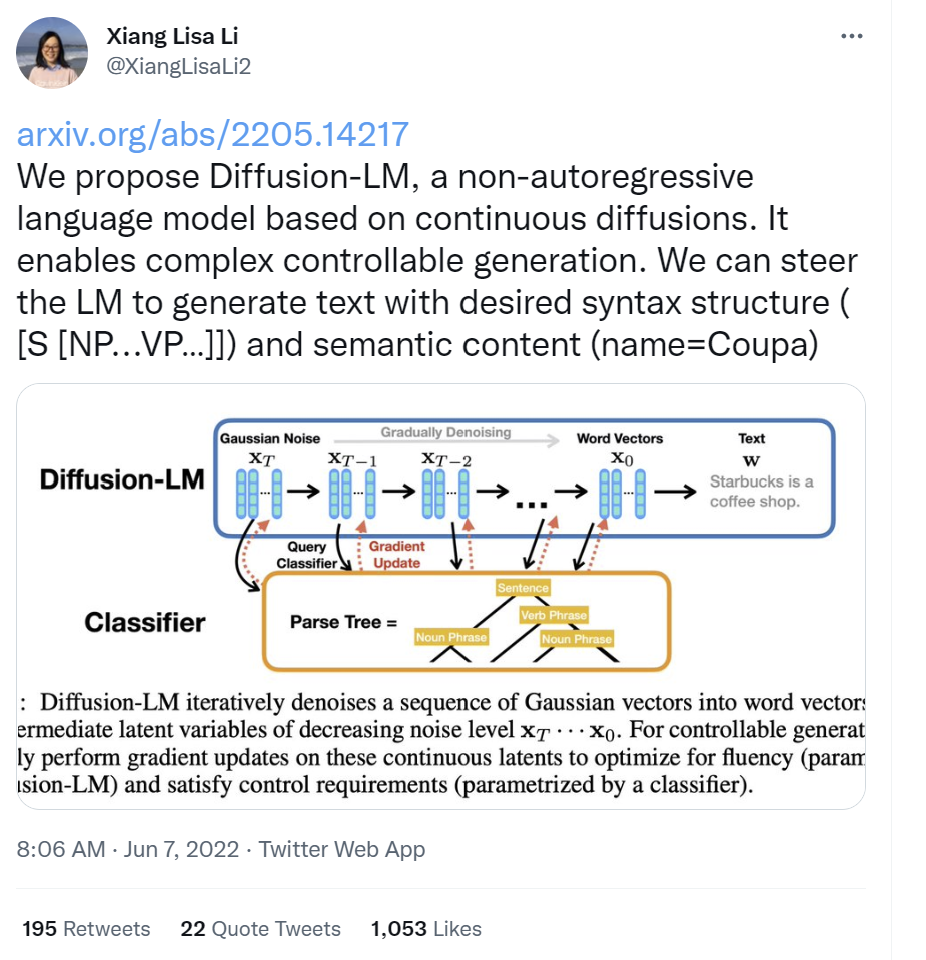
论文标题:
Diffusion-LM Improves Controllable Text Generation
论文链接:
https://arxiv.org/pdf/2205.14217.pdf
问题背景
首先,我们先来了解一下可控语言生成任务。语言生成任务指的是,给定语言模型 , 其中 是词汇的序列,自回归语言模型可以表示为:
可控语言生成指的是,给定控制变量 ,例如语法结构,情感,生成词汇序列 。
一般来说,估计 的方式是,训练一个从词汇序列 到控制变量 的分类器 ,然后利用贝叶斯公式 。
优化 的作用是使得输出流利,优化 的作用是使得 满足控制变量的约束。
主要方法
扩散模型的基本设置
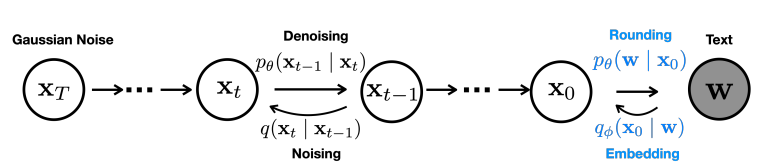
将数据定义为 ,定义 为一个满足高斯分布的随机变量 。
定义一个马尔可夫过程 ,状态转移方程为:
其中 和 由U-Net或者Transformer估计。
为了训练扩散模型,我们需要定义前向和后向两个过程,前向过程为加噪声过程, 其中 表示在第 步扩散时添加的噪声,前向过程 不包含可训练的参数,只提供一个将原始数据扩散为噪声的过程。
扩散模型的优化目标是最大化边缘概率分布 , 可以转化为变分下界损失函数:
不过这一变分下届在实际中优化比较不稳定,因此一般使用如下的简化方式进行优化:
其中 是后验分布 的平均值,而 是利用神经网络预测的 的均值。
已有的工作已经说明了这一优化目标的有效性。
Diffusion LM的端到端训练
为了将连续的扩散模型应用到离散文本上,首先定义离散文本的Embedding函数 将每个词语映射到一个连续向量。
因此在扩散模型训练,在前向过程中需要多加入一步从离散词汇映射到连续向量, 在反向过程中,加入一步从连续向量映射到离散词汇 , 这一步通过Softmax分类实现。
最后可以将Diffusion LM的训练目标转换为如下的形式:
Diffusion LM的解码和生成
Diffusion LM的可控生成等价于从后验分布 中解码, 在每一步扩散中,优化目标为:
由于马尔科夫链的一阶相关性,在第 步可以使用如下的梯度优化方式,为了保证生成文本的流利性,作者们还使用了一些正则化的技巧:
为了提升生成的输出的质量,作者们还使用了在机器翻译中常用的最小贝叶斯风险(MBR)解码方式。
实验结果
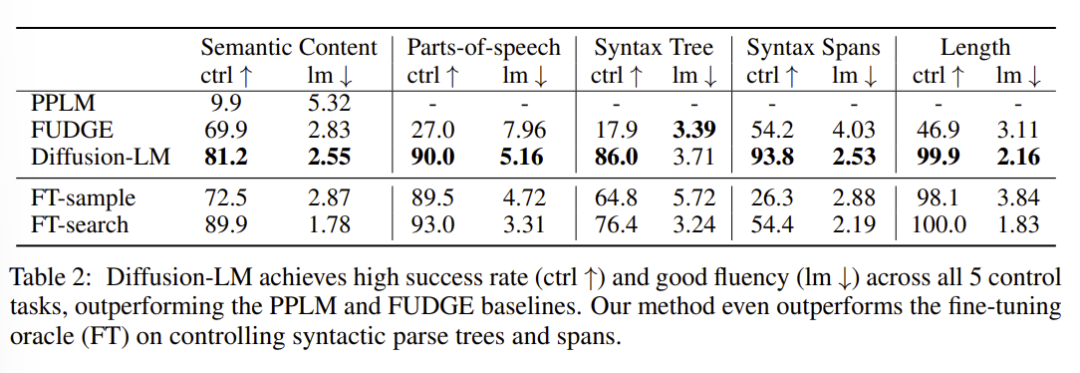
作者们在情感控制,可控语法生成等任务上开展了实验,和PPLM,FUDGE等可插拔式方法进行对比,可以发现Diffusion-LM相比之前的同类方法有极为显著的提升,特别是在部分任务上,甚至可以达到和微调相似的结果。
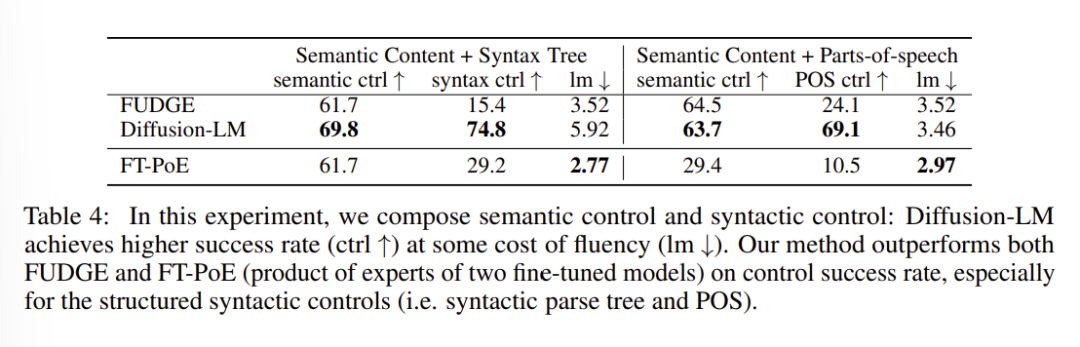
组合控制是可控文本生成的另一个常见场景。给定关于多个独立任务的控制条件,要求模型生成满足多个控制条件的文本。
Diffusion LM在这一场景下也表现出了更好的控制成功率。
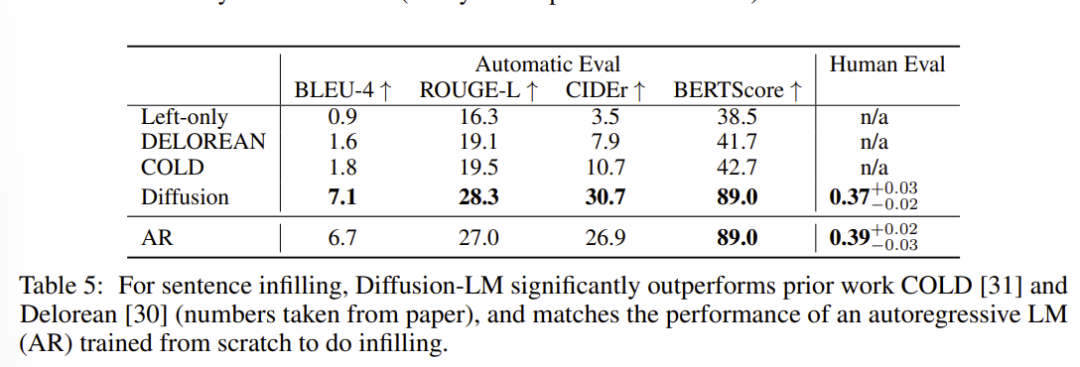
在句子填充任务(给定左边文本 和右边文本 ,输出中间的内容连接两段文本)上,Diffusion LM显著超越了之前的工作COLD和Delorean, 并且达到了和从头训练的自回归语言模型相近的效果。
结语
扩散模型受到了非平衡热力学的启发,具有良好的数学表达形式。在图像生成任务上优秀的性能证实了其不是徒有虚表的“花瓶”,而是深度学习时代的一大杀器。
尽管扩散模型仍然具有计算时间长等问题,我们仍可以期待其在更多模态的数据和任务上取得惊人的表现!
萌屋作者:Yimin_饭煲
在微软NLC组搬砖的联培博士生,爱好摄影和运动,希望卖萌屋早日开通视频业务,我来当摄影师!
作品推荐
 萌屋作者:Yimin_饭煲
萌屋作者:Yimin_饭煲
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【入群】
后台回复关键词【入群】
