CVPR 2022 线下会议将于 2022 年 6 月 21 日-24 日在美国新奥尔良举行。而今年投稿量创新高超过了一万,其中 2067 篇论文被接收。相关一系列教程从19号就开始了。来自英伟达和Google的三名研究学者讲述了《基于扩散的去噪生成建模:基础与应用》教程,182页ppt带你更好地了解高保真图像视频生成方法。

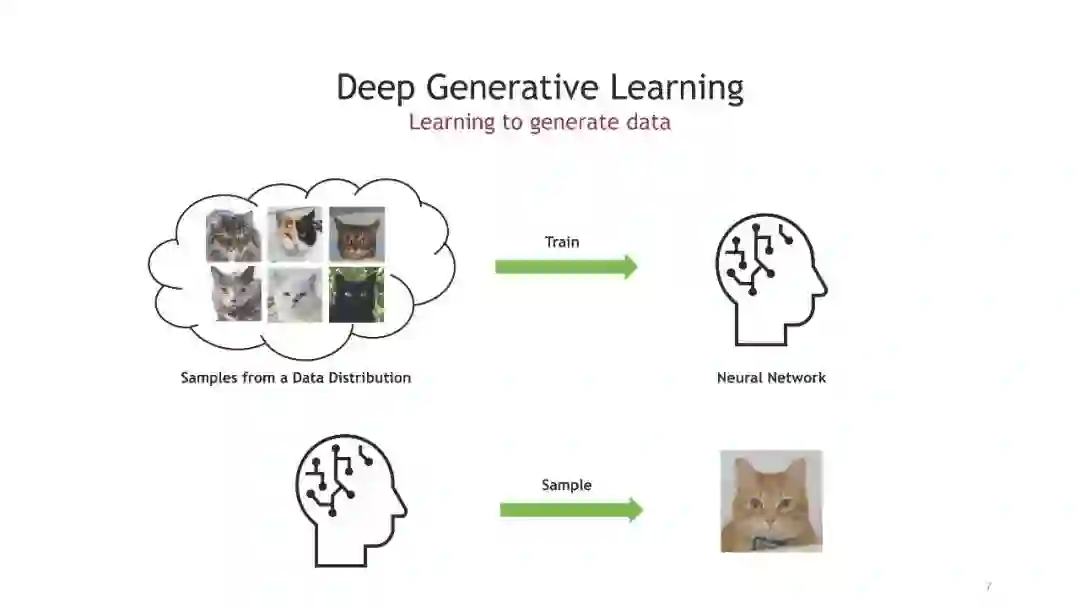
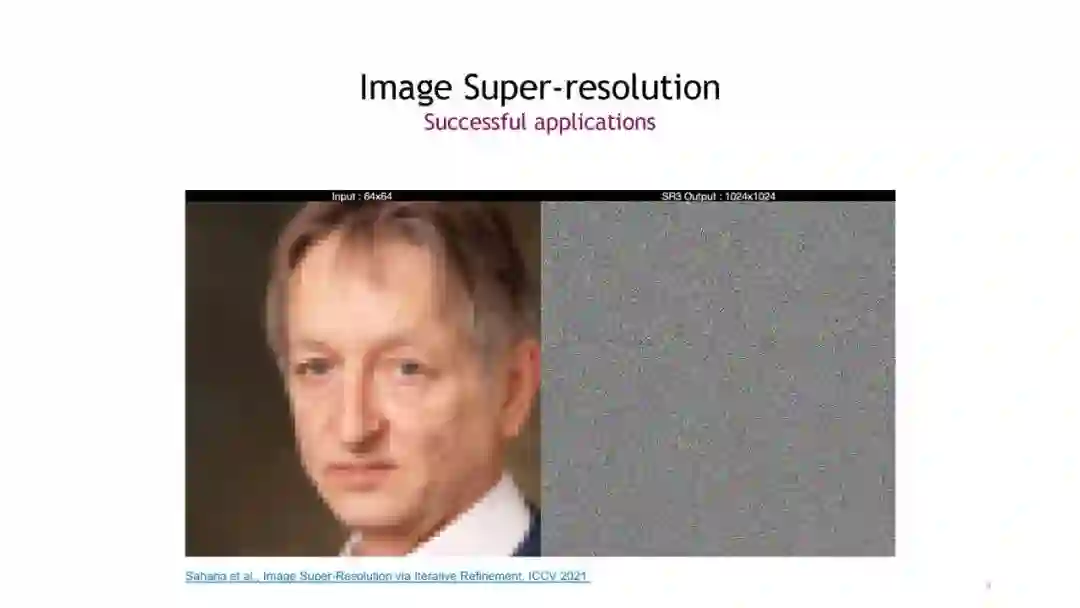
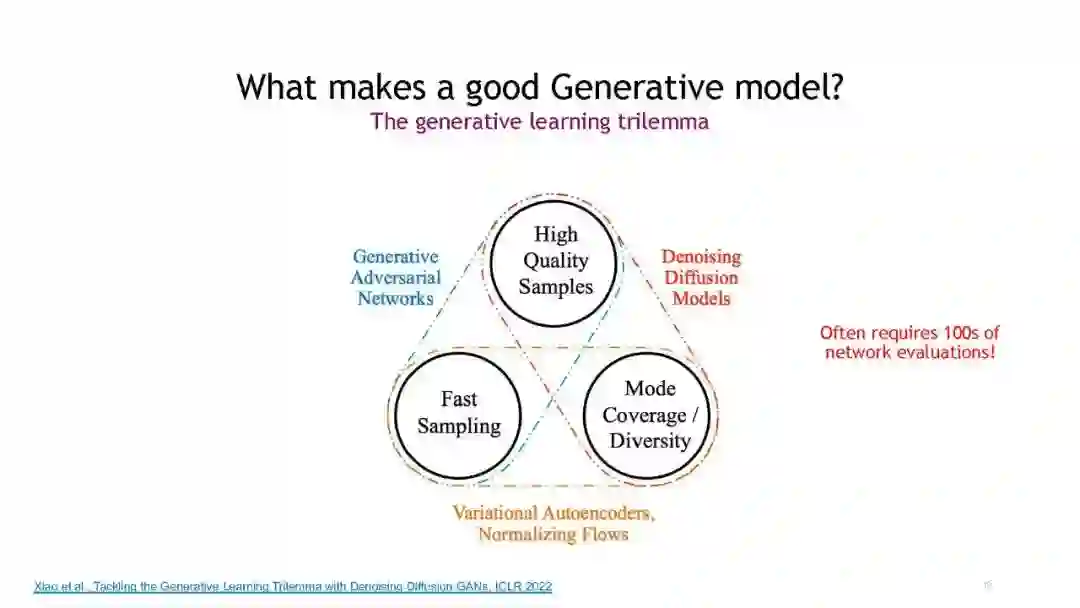
去噪扩散模型,也被称为基于分数的生成模型,是最近出现的一个强大的生成模型类别。它们在高保真图像生成方面表现出惊人的结果,甚至常常超过生成对抗网络。重要的是,它们还提供了较强的样本多样性和对已学习数据分布的保真模式覆盖。这意味着去噪扩散模型非常适合学习复杂多样的数据模型。去噪扩散模型定义了一个正向扩散过程,通过逐渐扰动输入数据将数据映射到噪声。数据生成是通过一个学习的、参数化的反向过程实现的,该过程执行迭代去噪,从纯随机噪声开始(见上图)。虽然扩散模型相对较新,但它们已经发现了许多成功的应用。例如,它们已经在计算机视觉中用于图像编辑、可控、语义和文本驱动的图像合成、图像到图像的翻译、超分辨率、图像分割以及三维形状生成和完成。
在本教程中,我们介绍了去噪扩散模型的基础,包括他们的离散步骤的公式以及他们的基于微分方程的描述。我们还讨论了与实践者相关的实际实施细节,并强调了与其他现有生成模型的联系,从而将去噪扩散模型置于更广泛的背景中。此外,我们回顾了近年来加速采样、条件生成等方面的技术扩展和先进方法。采样速度慢一直是扩散模型去噪的主要缺点。然而,已经出现了许多有希望克服这一挑战的技术。最近去噪扩散模型在高分辨率条件生成任务中也取得了惊人的进展,例如文本到图像的生成,我们讨论了实现这一目标的几个关键的先进技术。为了展示去噪扩散模型如何适合视觉用例,我们也回顾了在计算机视觉中的成功应用。
考虑到扩散模型具有生成质量高、模式覆盖率和多样性的独特优势,以及近年来关于快速采样和条件生成的研究成果,我们认为扩散模型将在计算机视觉和图形学领域得到广泛应用。不幸的是,扩散模型依赖于相当技术性的概念,因此在许多应用领域,这些模型的真正潜力还没有被释放出来,因为研究它们的社区仍然相对较小。本教程的主要目标是使扩散模型可通过提供一个介绍性的短期课程广泛的计算机视觉观众。本教程将建立在生成学习的简单概念上,并将为感兴趣的研究人员和从业者提供基础知识,以开始在这一令人兴奋的领域工作。
https://cvpr2022-tutorial-diffusion-models.github.io/

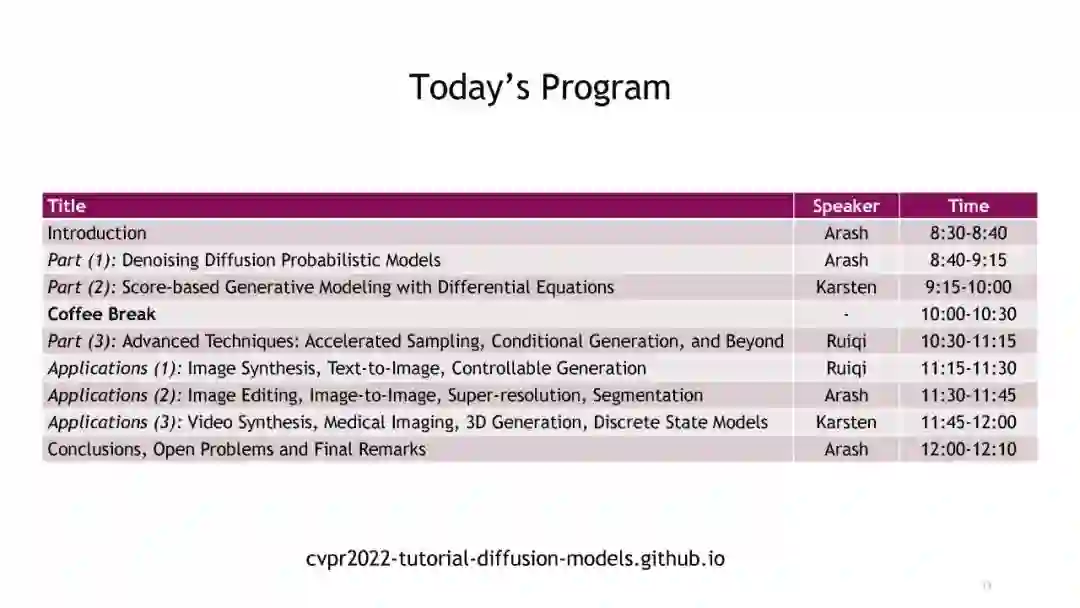
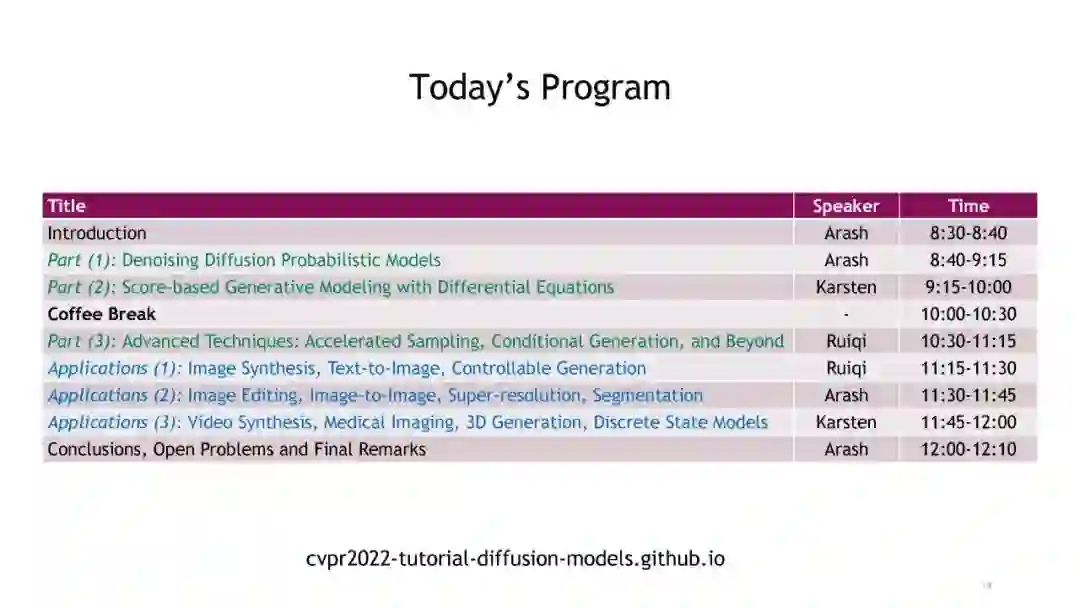
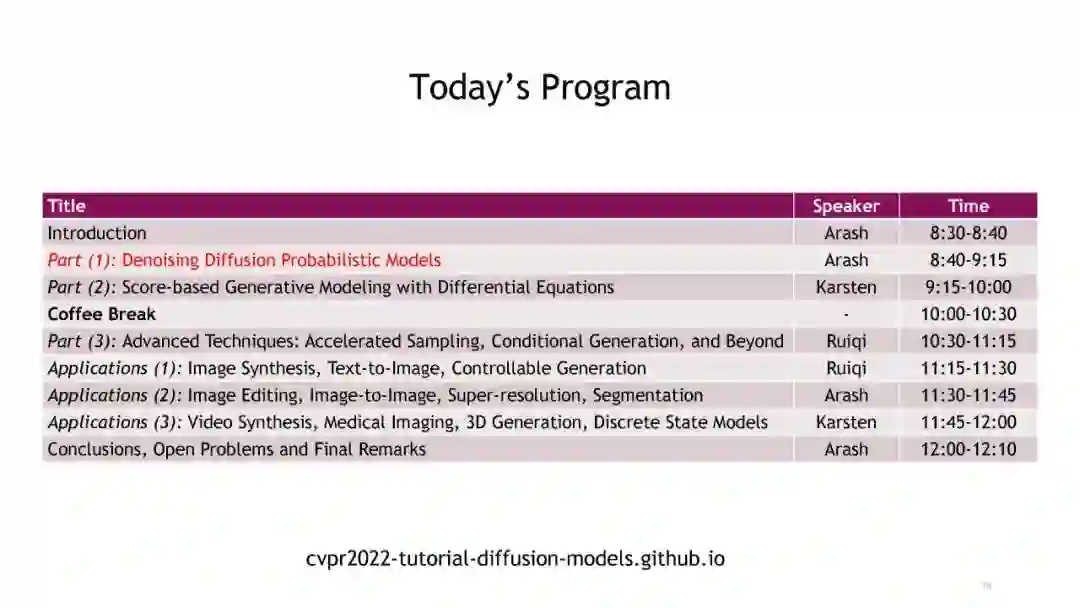
日程目录:
引言 Introduction
Part (1): Denoising Diffusion Probabilistic Models Part (2): Score-based Generative Modeling with Differential Equations Part (3): Advanced Techniques: Accelerated Sampling, Conditional Generation, and Beyond 应用:
Applications (1): Image Synthesis, Text-to-Image, Controllable and Semantic Generation Applications (2): Image Editing, Image-to-Image, Superresolution, Segmentation Applications (3): Discrete State Models, 3D Generation, Medical Imaging, Video Synthesis Conclusions, Open Problems and Final Remarks
讲者介绍:

Karsten Kreis是英伟达多伦多人工智能实验室的高级研究科学家。在加入NVIDIA之前,他曾在D-Wave Systems从事深度生成建模工作,并参与创立了一家利用生成模型进行药物发现的初创公司Variational AI。在转向深度学习之前,Karsten在马克斯普朗克光科学研究所完成了量子信息论硕士学位,在马克斯普朗克聚合物研究所完成了计算与统计物理学博士学位。目前,Karsten的研究重点是开发新的生成学习方法,以及将深度生成模型应用于计算机视觉、图形和数字艺术等领域的问题。
https://karstenkreis.github.io/

Ruiqi Gao是谷歌research, Brain team的研究科学家。她的研究方向是统计建模和学习,主要关注生成模型和表示学习。她于2021年获得加州大学洛杉矶分校(UCLA)统计学博士学位,在视觉、认知、学习和自主研究中心(VCLA)工作,导师是Song-Chun Zhu 和 Ying Nian Wu。她最近的研究主题包括深度生成模型的可扩展训练算法,以及在计算机视觉、自然语言处理和神经科学中的应用。 https://ruiqigao.github.io/

Arash Vahdat是NVIDIA的首席研究科学家,专攻计算机视觉和机器学习。在加入NVIDIA之前,他是D-Wave Systems的一名研究科学家,在那里他致力于深度生成学习和弱监督学习。在D-Wave之前,Arash是西蒙弗雷泽大学(SFU)的一名研究教师,他领导了深度视频分析的研究,并教授大数据机器学习研究生水平的课程。在Greg Mori的指导下,Arash在SFU获得了视觉分析潜在变量框架的博士和硕士学位。他目前的研究领域包括深度生成学习、弱监督学习、高效神经网络和概率深度学习。