年末回顾:2021年 AI 领域十大研究趋势及必读论文

编 | 小轶,Yimin_饭煲
在本文中,我们将梳理近百篇的最新深度学习论文,以总结出“2021 年十大 AI 研究趋势”。AI 领域的论文可谓层出不穷。这篇文章或许能帮助你跟踪总体趋势和重要研究。下文中提及的部分工作可能并不发表于 2021 年,但对于形成 2021 年的 AI 趋势也起到了重要作用,因而也在本文中列出。
![]() 1. OpenAI CLIP
1. OpenAI CLIP![]()
 1. OpenAI CLIP
1. OpenAI CLIP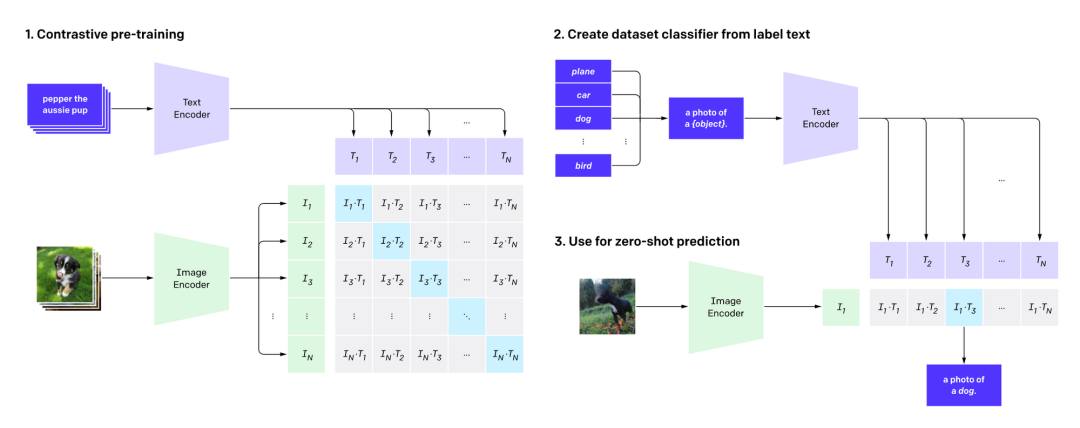
CLIP的机制非常简单。使用可以从网络上大量获取的大量图像以及与之相关的文本来预训练CLIP模型中相应的图像和文本编码器。如果文本和图像内容匹配,模型将给出高相似度,否则将给出低相似度。
为什么CLIP模型这么有用? 首先,考虑从图片到文字的方向,可以通过输入图片从多个选项中选择最匹配图片的文字对图片进行分类。传统的图像分类一般是在多分类框架中解决,从一个固定的类中选择一个正确的答案,但是使用CLIP,图像使用未定义范围的自然语言文本进行分类。通过将标签转化为自然语言文本,可以无需使用特定下游任务的数据对CLIP进行微调就进行分类,因此可以实现“零样本学习”。
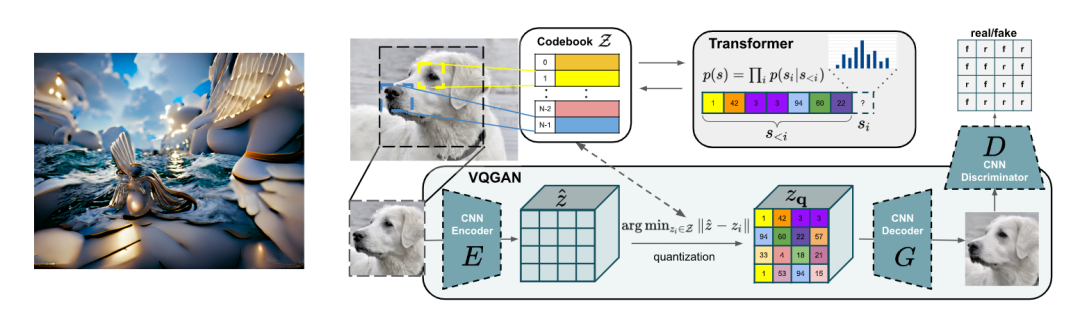
相反,考虑到从文本到图像的方向,如果输入某个文本,对图像进行优化,使其与文本的相似度变大,就可以用自然语言生成图像。准确地说,它通过优化其潜在表示并结合使用大量图像预训练的图像生成模型来生成图像,例如 VQGAN。VQGAN + CLIP的这种组合在今年年中成为网络上的一大话题,因为它可以轻松生成高质量的图像。近来,一种结合扩散模型(详细信息将在后面描述)和CLIP的“CLIP引导扩散模型(CLIP Guided Diffusion Models)”也成为了热门话题。
除了图像分类和图像生成任务之外,CLIP模型作为“通用图像理解引擎”的各种用途正在扩展。在前面提到的Kevin Zakka博文中,在视觉领域,通过实际例子介绍了利用CLIP模型解决reCAPTCHA、目标检测、显著图可视化等各种任务中的应用。此外,在一篇题为“How Much Can CLIP Benefit Vision-and-Language Tasks?”的论文中,CLIP可以用于VQA、Image Captioning和视觉语言导航(Vision-Language Navigation)之类的任务,并且已达到与强大Baseline相当或超过的性能。CLIPScore实现了无参考文本的Image Captioning生成性能评估。CLIP模型也可以被用于基于NeRF的场景生成、物理AI、机器人技术。
最近,AudioCLIP和Wav2CLIP扩展了 CLIP 以学习音频、图像和文本三种模态之间的关系。许多工作提出了CLIP模型的扩展和改进,例如 Lite和SLIP。
![]() 2. 自监督学习/对比学习
2. 自监督学习/对比学习![]()
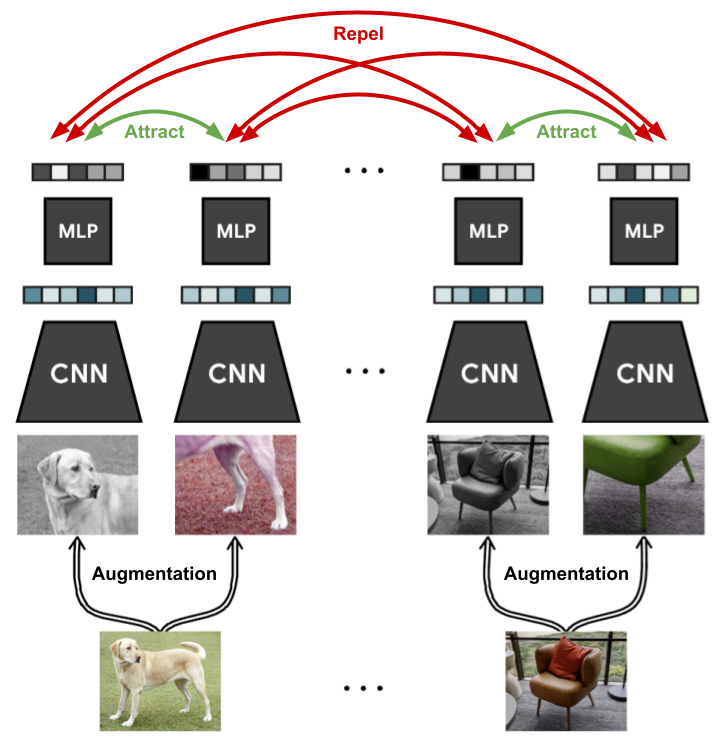
对比学习并不是什么新鲜的概念。多年之前,在自然语言处理领域流行的Word2Vec和Quick Thoughts中已经使用了类似的技术。
近年来在NLP领域中,ELECTRA通过检测自然语言文本中的替换词进行自监督学习,CLEAR通过数据扩展和对比学习获得高质量的句子表示,DeCLUTR使用从文档中采样的文本片段训练高质量的句子表示,SimCSE则是一种只需要两个输入到编码器的简单有效的句子表示方法。
在计算机视觉领域,从大量标记图像(例如ImageNet)中进行有监督的预训练已经很普遍。然而,在过去几年中,自监督学习和对比学习技术变得非常流行。最典型的是 SimCLR 和 SimCLRv2,它们通过将不同的数据扩展应用于单个图像来进行表示学习。此外,MoCo使用动量编码器进行对比学习,BYOL通过一种从头开始创建隐表示的自监督学习方法及无标签的知识蒸馏提升性能。还有许多其他方法被提出,例如DINO和SimSiam。上面介绍的CLIP也是基于对比学习训练的。
最近,MAE和SimMIM这两种使用与掩码语言模型类似的思想进行计算机视觉的自监督学习方法也成为热门话题。
![]() 3. 多层感知器 (MLP) 的复兴
3. 多层感知器 (MLP) 的复兴![]()
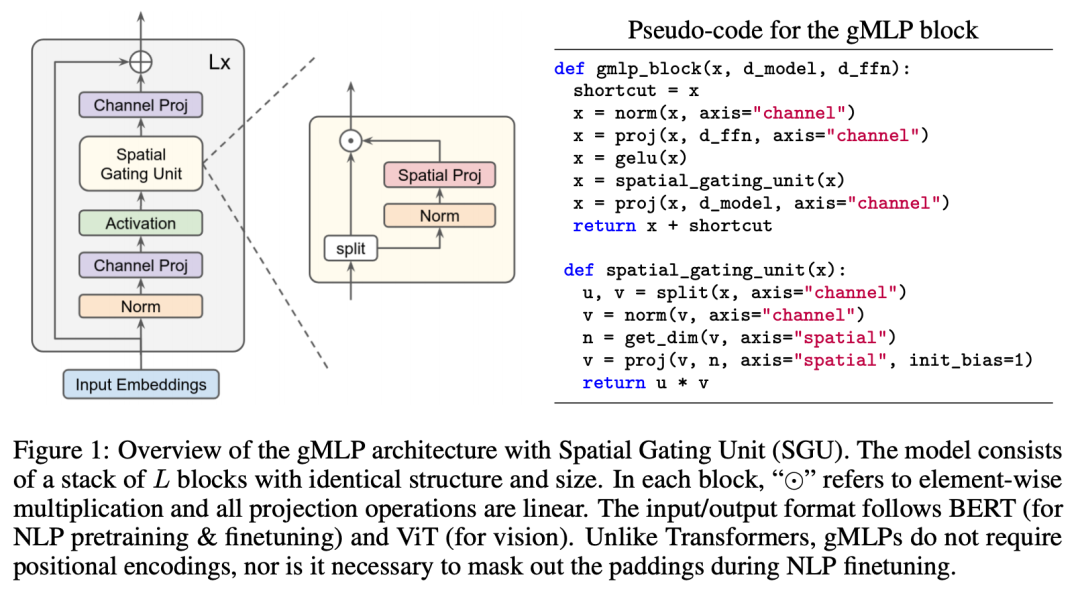
在图像分类中,无需使用卷积神经网络 (CNN) 和 Transformer 中广泛使用的注意力机制,只需将图像Patch和MLP相结合即可实现高性能和高速度的图像分类器。 2021年有大量基于MLP的模型出现,包括Mixer, gMLP还有Meta AI提出的ResMLP和RepMLP。
截止到2021年12月,尽管研究者们因为"MLP或许将成为超越Transformer的模型"而激动不已,但MLP还没有通过替换Transformer而普及。在最近发表的MLP综述论文"Are you ready for a new paradigm shift?"中指出,在目前的训练规模上,归纳偏置(Inductive bias)仍然有存在的必要,也即根据任务和数据设计模型结构仍然能在绝大多数情况下取得更好的效果。 此外,MLP还有一个未解决的问题,就是其性能严重依赖于输入分辨率。
![]() 4. 第三个深度学习库 JAX
4. 第三个深度学习库 JAX![]()
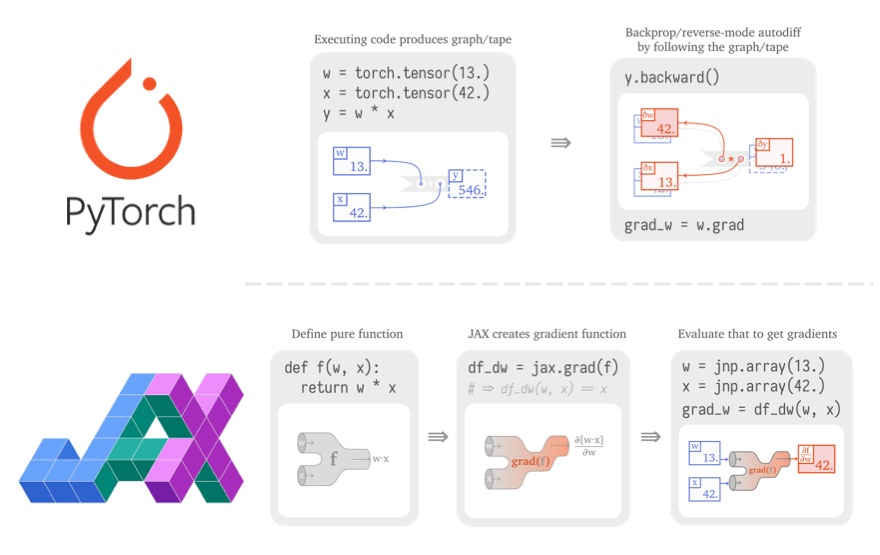
如果你在“PyTorch vs TensorFlow in 2022”这篇博客文章[2]中阅读了Hacker News的评论部分,以及标题为“2022 Are you a PyTorch sect? TensorFlow sect?”的 Reddit 帖子[3]中的许多评论,诸如“人们开始转向JAX”、“使用 JAX”和“JAX 正在取代 TensorFlow”这样的评论表明它甚至在社区基础上也逐渐流行起来。
2021 年,DeepMind 发表的许多优秀研究在其实现中使用 JAX 和基于 JAX 的神经网络库Haiku。视觉Transformer和MLP-Mixer的实现中也使用了基于JAX的深度学习库Flax。最近,谷歌发布了一个基于JAX的计算机视觉库SCENIC,它利用视觉Transformer以统一的方式解决图像、视频和音频任务。
在自然语言处理(NLP)领域,Flax 已经正式被用于NLP的流行框架 HuggingFace Transformers 和目前开源最强的语言模型GPT-J。我经常使用Haiku(一个基于JAX的神经网络库),并使用JAX的并行化机制xmap进行模型并行化。今年6月发布的Cloud TPU VM也有助于使 TPU 更易于使用。总之,我们期待着“2022年是JAX年”的未来发展。
![]() 5. 扩散模型
5. 扩散模型![]()
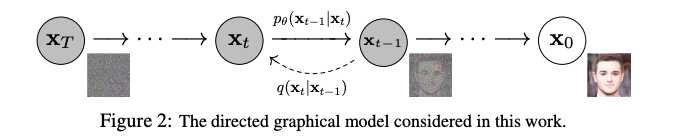
2019-2020年,扩散模型的基础研究开始活跃起来。首先是基于使用分数的“分数匹配”的生成模型以及使用扩散概率模型的高质量图像生成方法. 从Denoising Diffusion Probabilistic Models开始,对扩散模型的在图像生成领域的研究开始变得活跃。
另一方面,与其他基于似然性的方法(如自回归模型)相比,扩散模型存在无法获得更好似然性的问题。2021年,研究者们改进了OpenAI的扩散模型Improved Denoising Diffusion Probabilistic Models和The diffusion model exceeded GAN in image generation来解决这个问题。他们的论文Diffusion Models Beat GANs on Image Synthesis发表并成为一个热门话题。此外,扩散模型也被应用于其他模态,包括D3PM应用于文本生成,DiffWave和WaveGrad应用于语音生成等。
最后,最近出现了“CLIP引导的扩散模型(CLIP guided diffusion model)”,它将扩散模型应用于从文本生成图像,类似于上述使用 VQGAN+CLIP的图像生成。
![]() 6. 以数据为中心的人工智能
6. 以数据为中心的人工智能![]()
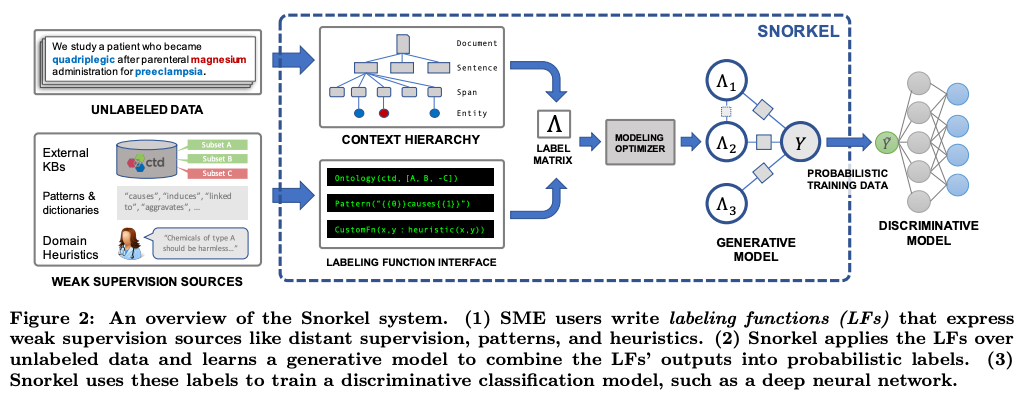
早些年,有一种以数据为中心的“数据编程”技术。当年基于该技术起家的创业公司 Snorkel.ai,目前已市场估值超过百亿,加入独角兽行列。
而今年,“以数据为中心的人工智能”再度成为 AI 新趋势,又大火了一把。其背后的推动力是 DeepLearning.ai / Landing.ai 的领导者 Andrew Ng 在今年 3 月发布的名为 A Chat with Andrew on MLOps: From Model-centric to Data-centric AI 的演讲。在研讨会上,他倡导“以数据为中心的 AI”作为一个清晰的概念,引发学术界的广泛认同和讨论。Andrew 介绍了他当时负责的一个项目。该项目旨在开发一个用 CV 技术检测产品缺陷的系统。经过两周的开发期,他们发现通过改进模型并没有带来明显准确率的提升,而改进数据却带来了 16.9% 的性能提升。
之后,Andrew 又领导 Landing.ai / DeepLearning.ai 举办了一场以数据为中心的人工智能竞赛。与 Kaggle 等传统 AI 竞赛截然,这场比赛并不是下载标准数据集,然后改进模型端,而是通过改进数据端以提高结果。今年晚些时候,还与 NeurIPS 2021 国际会议一起举办了以数据为中心的 AI 研讨会。一篇论文[4]也谈到了“那些自称基准数据集的 benchmark 也充斥着各种数据错误”。
“数据对人工智能很重要”,这一点或许不用多说。很多人在将 AI 应用于现实世界的问题时,通过权衡“数据改进”和“模型改进”,或多或少都意识到数据改进具有很大的效益。但是,能在今年推出“以数据为中心的人工智能”的这一明确概念进行传播,并得到学术界广泛认可,依然是一个巨大的进步。
![]() 7. 语音无监督表示学习
7. 语音无监督表示学习![]()
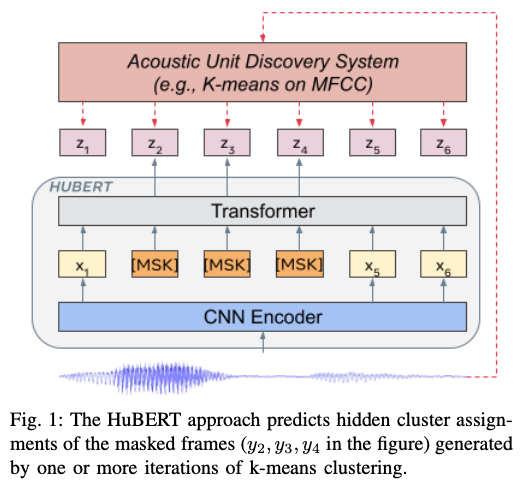
自 2020 年以来,语音的自监督学习得到了积极的研究,并应用于各种任务,例如 wav2vec 2.0。与文本和图像一样,通过收集大量未注释的数据并进行预训练学习,显著提高了在语音识别等各类语音任务上的性能。即使在 2021 年,自监督的研究势头也依然持续。SSAST 通过 mask 语音块来预训练学习高质量的语音表示。近日,[5] 则提出了一种用于学习语音、环境声音和音乐的通用语音表达的方法。
随着语音的表示学习方法变得越来越强大,今年各个语音任务上都有不小的突破。今年年中,Facebook 的 wav2vec-U 实现了无标签语音识别,备受关注。
此外,在处理语音时完全不依赖文本的“无文本NLP”方法在今年也得到了快速发展。典型的例子是 GSLM,它仅根据语音输入生成语言。[6] 则提出了一种使用离散潜在代码直接将语音转换为语音的方法。这是一种非常具有前景的突破性技术,因为世界上有很多语言并没有书面形式。
这些用于语音的无监督表达学习方法大部分已经被 Facebook / Meta AI 开源了。这两家公司也是当前语言技术实力最强的机构之一。
![]() 8. 语言模型继续做大做深
8. 语言模型继续做大做深![]()
震惊业界的 GPT-3 在 2020 年公布已经有一段时间了,但巨型语言模型的研发在那之后依然在持续推进。在 2021 年,GPT-3 已然不是“最新大规模语言模型”,而是各种更新模型的改进“基线”。
比如今年早些时候,EleutherAI 发布了号称“目前开源可用的最强语言模型” GPT-J-6B(60 亿个参数)。GPT-J-6B 采用 JAX / Haiku 实的。AI21 Labs(以色列的自然语言处理初创公司)也发布了巨型语言模型 Jurassic-1。虽然它与 GPT-3 规模几乎相同(参数数量 178B),但它已加入了各种 trick 以提高性能。此外,12 月 DeepMind 发布了最新的 280B 参数的大规模语言模型 Gopher,证明其在各种自然语言理解任务中的表现优于 GPT-3。
在当今的语言模型研究中,不仅要加大规模,更注重加入巧思,研究如何用好大规模语言模型去解决目标任务。比如,FLAN 模型用 prompt 调优大规模语言模型,以提高模型在 zero-shot 场景下的泛化能力。其他旨在提高零样本泛化能力的代表工作包括 T0 和 ExT5。这两篇工作都结合了预训练学习和大规模多任务学习。
需要注意的是,其中语言模型是基于 seq2seq 结构(如 T5),而不是仅仅有解码器(如 GPT-3)。2021 年,T5、mT5 和可以直接处理字节序列的 ByT5 还发布了多语言的版本。这些模型的使用范围也正在不断扩大。
![]() 9. 非参数方法
9. 非参数方法![]()
很长时间依赖,大规模语言模型将知识以模型参数的形式进行存储。虽然这些“参数化”模型可以拥有惊人的大量知识作为参数。它们在 QA 等需要大量知识的任务中表现良好。缺点则是模型的大小必须成倍增加才能改进。
从2020年左右开始,越来越多的研究开始将知识作为某种外部知识,而不是作为模型参数来表达,称为“非参数”方法。这些模型也被称为“基于搜索”的技术,因为它们需要通过搜索得到外部知识。
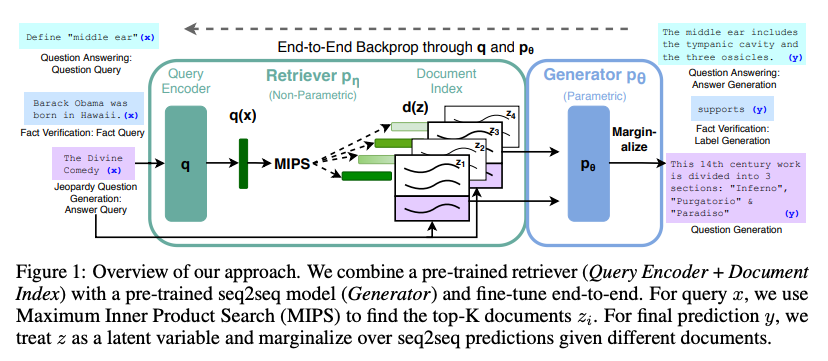
典型的方法包括基于邻域搜索的语言模型(kNN-LM),基于邻域搜索的机器翻译(kNN-MT),以及使用搜索的语言生成。如 RAG ([7],见上图)和 MARGE([8],2020 年)使用搜索 + 释义进行预训练学习。
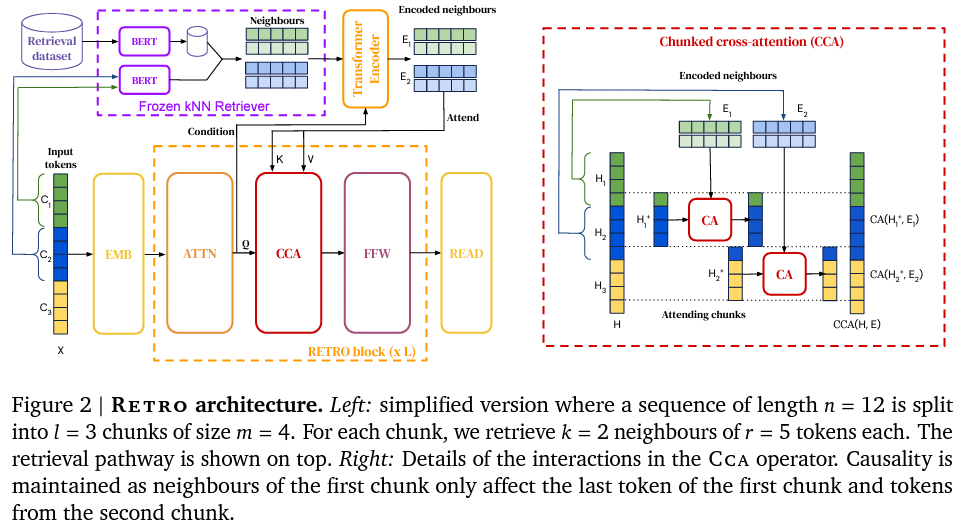
近日,大型语言模型 RETRO [9]发布。该模型通过搜索技术改进语言模型,基于一个 2 万亿 token 组成的数据库进行搜索,达到了近乎 GPT-3 的性能。这些模型的优点是在不增加参数数量的情况下提高了语言模型的性能,并且可以在之后不断添加或替换搜索数据库。
![]() 10. “AI 大一统理论”
10. “AI 大一统理论”![]()
最后,让我们谈谈近年来人工智能最重要的趋势——“AI 大统一理论”。2021年,人工智能领域在各种“大整合”。近日,特斯拉 AI 负责人 Andrew Karpathy 发布了一条推文称“AI 空间的持续整合令人惊叹”, 很好地代表了 AI 行业的当前状态:

Andrew Karpathy 的 Twitter 全文:
当我进入 AI 行业时,计算机视觉、语音、自然语言、强化学习等各个领域是完全分开的。那时候很难跨领域地阅读论文。因为方法完全不同,有的方法通常甚至不是基于机器学习的。
在 2010 年代,所有这些领域都开始转变,特别是机器学习和神经网络方面。模型架构或许多种多样,但论文都开始变得越来越相似,所有领域都在用大型数据集,并关注如何优化神经网络。
而从大约两年前开始,各个领域连神经网络架构都开始变得雷同起来——一个 Transformer 足矣(用 pytorch 版本的话,大约 200 行)。Transformer 作为一个强大的 baseline,你可以给它输入单词序列,或者或图像 patch 序列,或演讲语音序列。或者强化学习中的(state, action, reward)序列。任意其他标记统统都可以放入这个简单又灵活的模型框架。
在领域内部,比如 CV 领域,过去在分类、分割、检测、生成方面也存在一些差异,但所有这些也正在转换为相同的框架。现在方法上的区别都主要集中在:
数据 如何将你要解决的任务更好地映射到向量序列,以及如何从向量序列抽取输入/输出规范 位置编码器的类型和任务定制化的注意力机制 因此,即使我是做 CV 的,也不得不开始关注其他领域,因为所有领域 AI 的论文和想法都已变得息息相关。每个人都在使用基本相同的模型,因此大多数改进和想法都可以快速在所有 AI 中快速“复制粘贴”。
正如已经有不少人指出的那样,大脑的新皮质在其所有输入模式中也具有高度统一的架构。也许大自然偶然发现了一个非常相似的强大架构,并以类似的方式复制了它,只是改变了一些细节。AI 架构上的这种整合,使我们将更多注意力放在了提升软件、硬件和其他基础设施上,从而进一步加速了人工智能的进步。Anyway,这是个激动人心的时代。
即使基于 CNN 的各种强大模型已经广泛应用于 CV 领域多年。近年来,图像也开始被分割成 patch 喂进了 Transformer。从 Vision Transformers 和 DeiT 开始,Transformer 的浪潮愈加汹涌。类似的想法开始通过 SST 传播到语音领域。SST 将频谱图也拆分为 patch 来分析语音。
在自然语言处理领域,我们如何像 GPT 一样使用 Transformer 来生成和转换新的图像和声音?答案很简单:“将图像和声音等输入转换为离散标记,并使用语言等转换器对标记序列进行建模。”这个框架没有具体的名称,但个人认为会是近两年左右深度学习行业最重要的趋势。
对于这种到离散标记序列的转换,通常使用 VQ-VAE,一种将潜在表达式绑定到离散标记的自解码器 (autoencoder),或者 dVAE (也被称为离散变分自编码器)。这种机制广泛应用于图像生成模型,如 VQGAN、DALL·E 、CogView 、NÜWA,以及视频生成模型 VideoGPT。在音乐领域,Jukebox 它结合了离散化和 transformer 直接从音频生成音乐。
对输入进行离散标记化,通过屏蔽一部分并从上下文中恢复它可以更容易地学习高质量的表达式。例如自然语言处理领域流行的 BERT 掩码语言模型。使用这种机制,已经提出了用于视觉变换器的类 BERT 预训练模型 BEIT,以及用于视频的类 BERT 模型 VIMPAC。
最后,Transformer 的浪潮不仅仅涉及语言、图像和音频等领域。TabTransformer和 NPT 使用了表格数据的自注意力机制。另外还有推荐系统领域的 Transformer4Rec,以及强化学习领域的 Decision Transformer。
目前,如果是一个可以序列化的任务,并且可以获得足够的(初步的)学习数据,Transformers for Everything 的趋势很可能会继续很长一段时间。Transformer 的霸权还要持续多久,我们拭目以待。
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] https://blog.kzakka.com/posts/clip/
[2] https://www.assemblyai.com/blog/pytorch-vs-tensorflow-in-2022/
[3] https://www.reddit.com/r/MachineLearning/comments/rga91a/d_are_you_using_pytorch_or_tensorflow_going_into/
[4] https://arxiv.org/abs/2103.14749
[5] https://arxiv.org/abs/2111.12124
[6] https://arxiv.org/abs/2107.05604
[7] https://arxiv.org/abs/2005.11401
[8] https://arxiv.org/abs/2006.15020
[9] https://arxiv.org/abs/2112.04426
 后台回复关键词【
后台回复关键词【




