IJCAI 2022 | 腾讯AI Lab Oral论文:条件扩散模型FastDiff
感谢阅读腾讯 AI Lab 微信号第145篇文章。本文介绍腾讯 AI Lab 近日公开的 IJCAI 2022 Oral 论文,提出了一种新的条件扩散模型 FastDiff 作为声码器,及基于此设计了全新的端到端语音合成模型。
声码器(Vocoder)是一项把低维度声学特征转成波形的生成任务,该技术广泛应用于语音合成和语音信号编解码领域。伴随着近几年深度学习的飞速发展,声码器在合成质量上有了极大的进步。
为了提升声码器的生成效果,腾讯 AI Lab 正在理论、算法和网络结构层面探索如何让深度学习里最先进(State-of-the-art)的非自回归生成模型:降噪扩散概率模型(Denoising Diffusion Probabilistic Model, DDPM),在解决其原来的速度瓶颈的同时,仍能生成出与人声难以分辨的高质量语音, 并挖掘其应用在语音合成上的潜力。
在今年的 IJCAI 2022,腾讯AI Lab的一篇 Oral 论文提出了全新的条件扩散模型 FastDiff,能大幅减少 DDPM 每步降噪所需时间。该项工作效果已在声码器和语音合成上验证。

论文链接:https://arxiv.org/abs/2204.09934
基于团队此前于 ICLR 2022 发布的双边降噪扩散模型(Bilateral Denoising Diffusion Model, BDDM)[1],FastDiff 在声码器任务上展示了顶尖的合成质量,在主观听感评测中获 MOS 4.28,同时生成速度在 V100 GPU 上能比实时快 58 倍,首次让DDPM能在语音合成中有落地的可能。
在声码器测试中,FastDiff 也表现出优异的泛化性能,即使输入训练中未见的说话人的语音表征,FastDiff 声码器也能保持高质量的合成效果。基于 FastDiff 声码器所设计的端到端语音合成模型 FastDiff-TTS 跟其他端到端语音合成模型相比之下也拿到了领先的合成效果。
此项目将有助于提升语音产品用户体验,可应用于虚拟人、电竞解说、智能音箱等场景。未来,腾讯 AI Lab 将进一步研究如何利用此项目的工作成果合成具丰富表现力的语音及构建通用的基底声码器。
以下为论文详细解读。
研究背景
降噪扩散概率模型(Denoising Diffusion Probabilistic Model,DDPM)是近两年开始火热起来的一种非自回归生成模型,特点是能以较为简单的训练方式在许多基准图像生成任务中达到跟GAN差不多甚至是更佳的生成质量。
在听感测试中,业内一些基于DDPM的声码器的合成质量已能赶上自回归模型,但生成速度仍要远低于同为非自回归模型的Flow和GAN模型。这是由于DDPM在建模上需要通过迭代几百上千个采样步数来得到有效的降噪,如何快速得到高质量的合成样本仍然是难以解决的瓶颈。
腾讯AI Lab此前提出的BDDM,从理论和算法层面对DDPM进行双边建模,除了负责降噪的神经网络Score network以外,还设计了负责预测噪声编制(Noise Schedule)的Schedule network。BDDM的建模方法能让训练和采样的扩散过程通过两个不同的噪声编制来区分开,例如DiffWave在训练中是使用T=200步的扩散过程, 但采样时却能用7步的扩散过程来估计;而且能从理论层面推导出全新的训练损失来学习对于已训练好的Score Network来说最佳的噪声编制。
BDDM论文链接(ICLR 2022):https://arxiv.org/abs/2203.13508
Github:https://github.com/tencent-ailab/bddm
在声码器的实验中,经听感测试,BDDM能使得DiffWave最少只利用3步降噪就能合成出高保真音频,而7步降噪更能合成出与人声难以分辨的高质量语音。但它在合成速度上仍然会受限于降噪网络的计算量。当前基于WaveGrad和DiffWave的降噪网络结构即使结合BDDM技术仍无法满足落地的需求。
为了解决这些难题,本文提出了一种新的条件扩散模型FastDiff作为声码器,及基于此设计了全新的端到端语音合成模型。其使用扩散步条件卷积核预测器,并使用噪声下采样模块,强化声码器对于扩散步的条件依赖,以优化扩散模型生成质量。
经评估,FastDiff对波形的直接建模能力要比DiffWave更强同时计算量更低。同时,基于FastDiff设计的FastDiff-TTS端到端生成模型,不需要使用中间特征、多任务学习或者对抗训练,旨在解决端到端语音合成的不稳定问题。FastDiff-TTS引入语音空间变量编码模块,增强模型多风格学习能力,旨在适用于生成多语者、多风格的语音合成场景。
整体方案思路
FastDiff 的生成核心算法是基于降噪扩散概率模型。
在理论方面,定义语音样本为: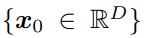
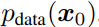

扩散过程:
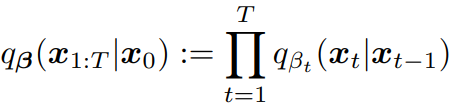
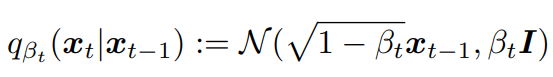
反向过程:
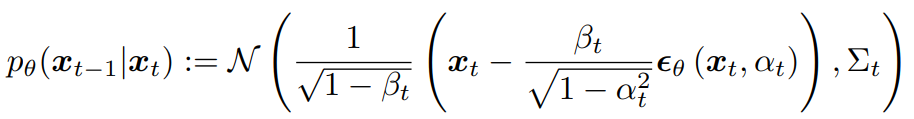
我们通过最大化证据下界(Evidence Lower Bound,ELBO),可以推导出简化的训练损失。这里,我们参考BDDM [1],有效的训练方法是用随机梯度下降优化:
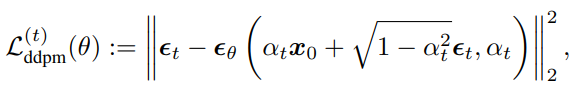
其中,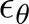
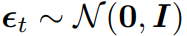
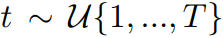
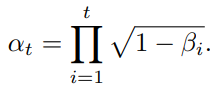
其中,仅有噪声编制与去噪步数 T 是需要预先定义的,其他变量都可以依次计算出。
FastDiff:高效的带噪波形条件建模
FastDiff的主要创新点来自于降噪模型结构方面:
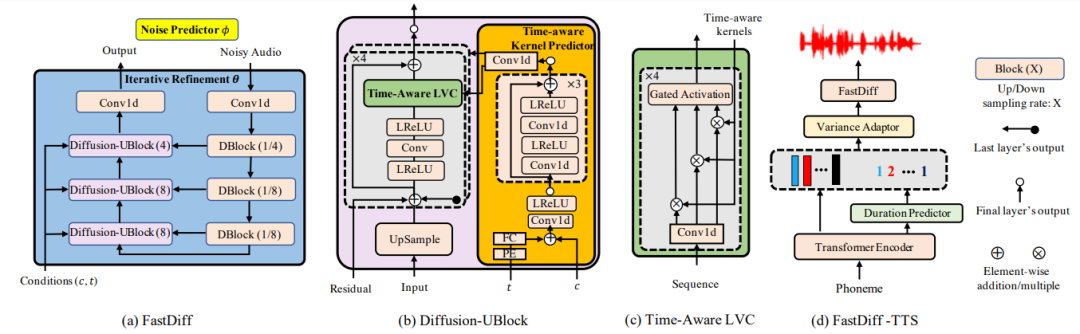
如图(a)所示,FastDiff模型主要由三层降采样块(DBlock)以及三层条件上采样块(Diffusion UBlock)构成。模型输入为带噪音频(Noisy Audio),噪声步数索引(表示为 t),梅尔频谱条件(Mel-spectrogram,表示为c)。DBlock等同于WaveGrad中的DBlock结构。而新设计的条件上采样块(Diffusion UBlock)如图(b)所示,先使用位置编码(Positional Encoding,PE)对 t 编码,然后经线性层后跟c相加,然后作为卷积核预测器(Kernel Predictor)的输入。预测的卷积核会在Time-Aware Location-Variable Convolutoin(LVC)中使用。以下是引入Time-Aware LVC的作用和原理解释。
为了有效的捕获条件的局部信息,FastDiff参考了LVCNet [2] 设计Time-Aware LVC,如图(c)所示,位置变量卷积能对梅尔频谱和噪声步数编码条件进行高效建模,使之能对应于不同的噪声水平,均能够高质量地生成所预测的卷积核。能在保持模型尺寸的同时获得了更优的音质和速度。该模块输入包括下采样的带噪音频,以及预测的卷积核。在Time-Aware LVC中,Gated Activation Unit(GAU)门激活单元是为了提高本语音合成深度模型对于多说话人数据集的通用性,它在WaveNet中被证明能够有效地增加深度神器网络网络中的非线性。
总结FastDiff每步降噪的建模过程:卷积核预测器以噪声等级和梅尔频谱为条件,输出预测的卷积核。带噪音频通过三次下采样,经过LReLU激活与Conv1d一维卷积计算后,与先前获得的预测卷积核,一同参与计算Time-Aware LVC区域卷积。得到的音频通过GAU以增加非线性,与残差相加后送到下一层Diffusion UBlock的子层(共四层),最后模型输出预测还原的噪声向量。
当降噪神经网络被充分训练之后,FastDiff利用BDDM算法训练Schedule network来得到步数更少的噪声编制。当得到搜索后的噪声编制,FastDiff能用以下的采样算法来进行高速的音频合成。


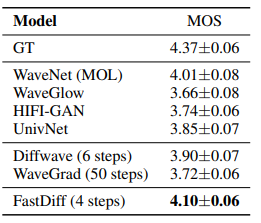
在LJSpeech数据的实验中,如下表所示,FastDiff能以4步降噪就能拿到相比前者最先进的声码器更优的主观及客观听感指标,同时FastDiff是首个在生成速度上能跟非DDPM类模型可比的(略比WaveGlow快)。在生成多样性上面,实验中较低的NDB和JSD也验证了FastDiff和其他DDPM类模型能比较避免模式坍塌问题。
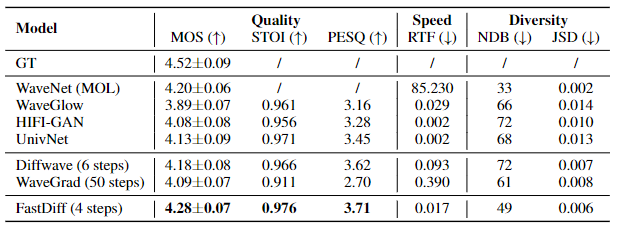
由于在LJSpeech的单人语音数据集,我们还用了多人语音数据集VCTK来测试在LJSpeech上训练的不同声码器对未知说话人泛化性能。如下表所示,在用未知说话人语音作为输入时FastDiff仍能维持相当高的合成质量,且要远胜其他声码器。
FastDiff-TTS: 简单却有效的端到端语音合成模型
如图(d)所示,我们还设计了端到端语音合成模型FastDiff-TTS。其特点是结构非常简单却有效,在FastDiff的前端只加入了以下两个模块:
A. Transformer Encoder文本编码器
通过MFA强制对齐工具进行预处理后,得到phoneme和时长。将phoneme编码为phoneme embedding,并加入位置编码position encoding[6]。将序列通过文字编码器(Transformer Encoder),得到表征音素的隐变量。
B. Variance Adaptor语音空间变量编码
本模块主要提供风格化的语音建模。经过时长预测器后,模型将音素序列扩展到梅尔长度。同时,在该模块中加入风格表征,包括:语者变量(Speaker Embedding)、情感变量(Emotion Embedding)、语言变量(Linguistic Embedding)等进行风格化建模,提升生成音频的表达性。
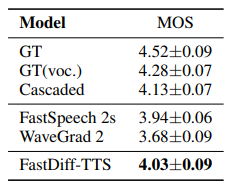
在LJSpeech的实验中,我们对比了FastDiff-TTS跟传统的声学模型接声码器方法(Cascaded: PortaSpeech + FastDiff)和两个最新的端到端语音合成技术:FastSpeech 2s和WaveGrad 2。如下表所示,FastDiff-TTS虽然在合成质量上仍未能超越学模型接声码器的Casaded方法,在主观评测上能拿到了比最新全端到端语音合成技术更高的MOS分数。
参考文献
[1] Max W. Y. Lam, Jun Wang, Dan Su, and Dong Yu. "BDDM: Bilateral Denoising Diffusion Models for Fast and High-Quality Speech Synthesis." In Proc. ICLR 2022.
[2] Zeng Zhen, et al. "LVCNet: Efficient Condition-Dependent Modeling Network for Waveform Generation." In Proc. ICASSP 2021.

* 欢迎转载,请注明来自腾讯AI Lab微信(tencent_ailab)




