编辑:小咸鱼 好困 LRS
【新智元导读】近日,微软正式发布了一个新的计算机视觉基础模型Florence(佛罗伦萨),要用一个模型一统多模态天下!Florence可以轻松适用于各种计算机视觉任务,如分类、目标检测、VQA、看图说话、视频检索和动作识别,并在超过40个基准中刷新了SOTA。
今年,在计算机视觉方向的最新成果里面,「多模态」这个词是彻底火了!
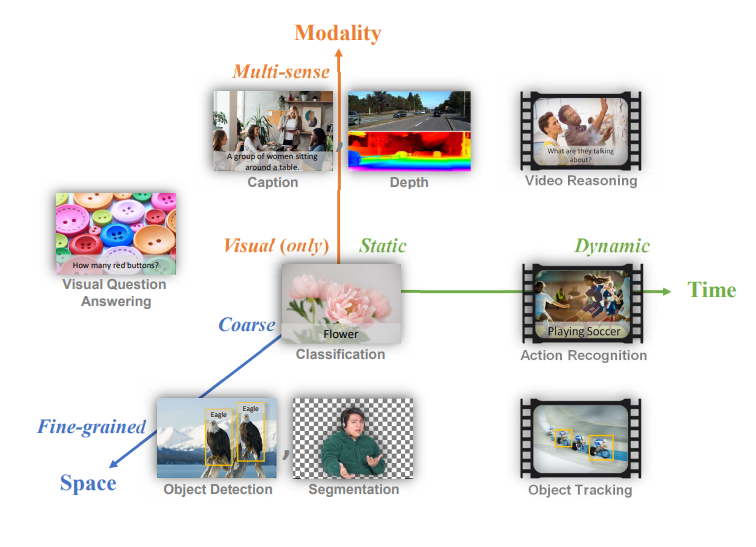
人类对于多样化的、开放的世界,会产生自己的视觉理解,这种视觉理解并不会单单局限在某个特定的任务上(比如,图像分类),也不会仅仅依赖某一种特别的信息输入(比如,静态图像)。
常见的计算机视觉任务被映射到时空模态空间。计算机视觉基础模型应该成为能够胜任所有这些任务的通用视觉系统。
正是这种跨越多个模态的信息融合让人类可以胜任开放世界的各种视觉任务,真正做到对各种视觉信息的「理解」。
这一点启发了研究人员,如果计算机视觉模型需要很好地概括各种模态的信息,且减少对特定任务的定向训练,计算机视觉的基础模型就要在多样化的大规模数据集上进行训练,以适应各种各样的下游任务,来解决现实世界的计算机视觉应用问题。
今年年初,OpenAI推出了CLIP(Contrastive Language–Image Pre-training),它是一个从互联网上收集的4亿对图像和文本来进行训练的多模态模型。
https://arxiv.org/pdf/2103.00020.pdf
它可以从自然语言监督中学习视觉概念,也可以应用于任何视觉分类基准任务,在超过30个现有数据集上对CLIP的zero-shot性能进行测试后,发现它可以与之前特定任务的监督模型相媲美。
在ICML 2021会议上,Google Research发表了「Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision」一文,建议利用公开的图像替代文本数据来训练更大、更先进的视觉和视觉-语言模型ALIGN。
https://arxiv.org/pdf/2102.05918.pdf
ALIGN使用超过10亿的图像和文本对的噪声数据进行训练,在多个图像文本检索任务(Flickr30K 和 MS-COCO)上的zero-shot和微调性能都击败了CLIP,取得了SOTA。
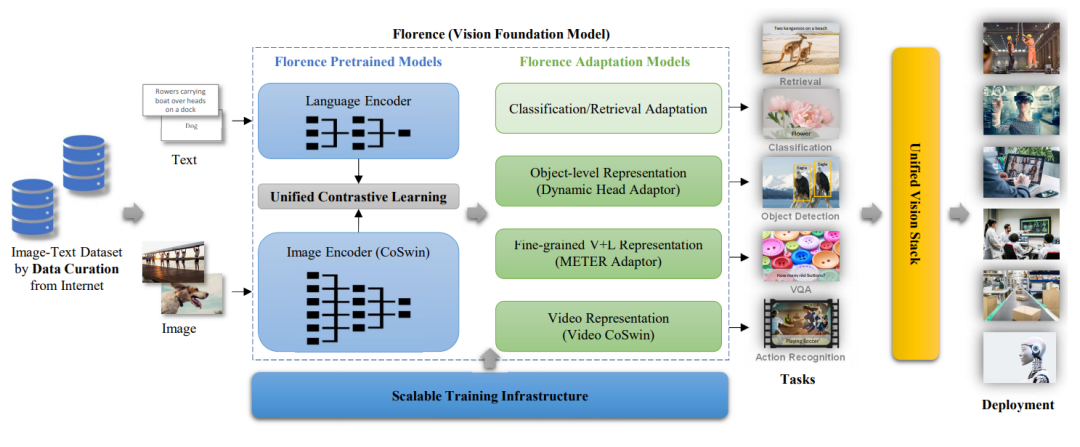
而近日,微软正式宣布了一个新的计算机视觉基础模型Florence(佛罗伦萨),目的是要用一个模型一统多模态天下!
https://arxiv.org/pdf/2111.11432.pdf
现有的视觉基础模型,如CLIP、ALIGN等,主要侧重于将图像和文本映射到一种跨模态的共享表征。
Florence则将表征进行了拓展,不仅拥有从粗略(场景)到精细(对象)的表征能力,还将视觉能力从静态(图像)扩展到动态(视频),从RGB图像扩展到多模态(文字、深度信息)。
通过整合图像-文本数据的通用视觉语言表示能力,Florence可以轻松适用于各种计算机视觉任务,如分类、目标检测、VQA、看图说话、视频检索和动作识别,在多种类型的迁移学习中均表现出色。
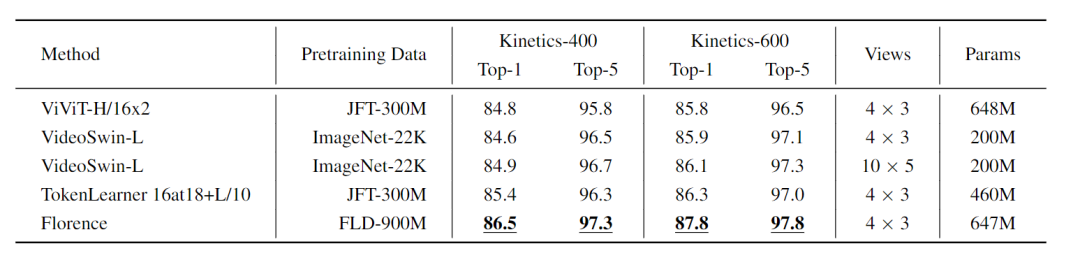
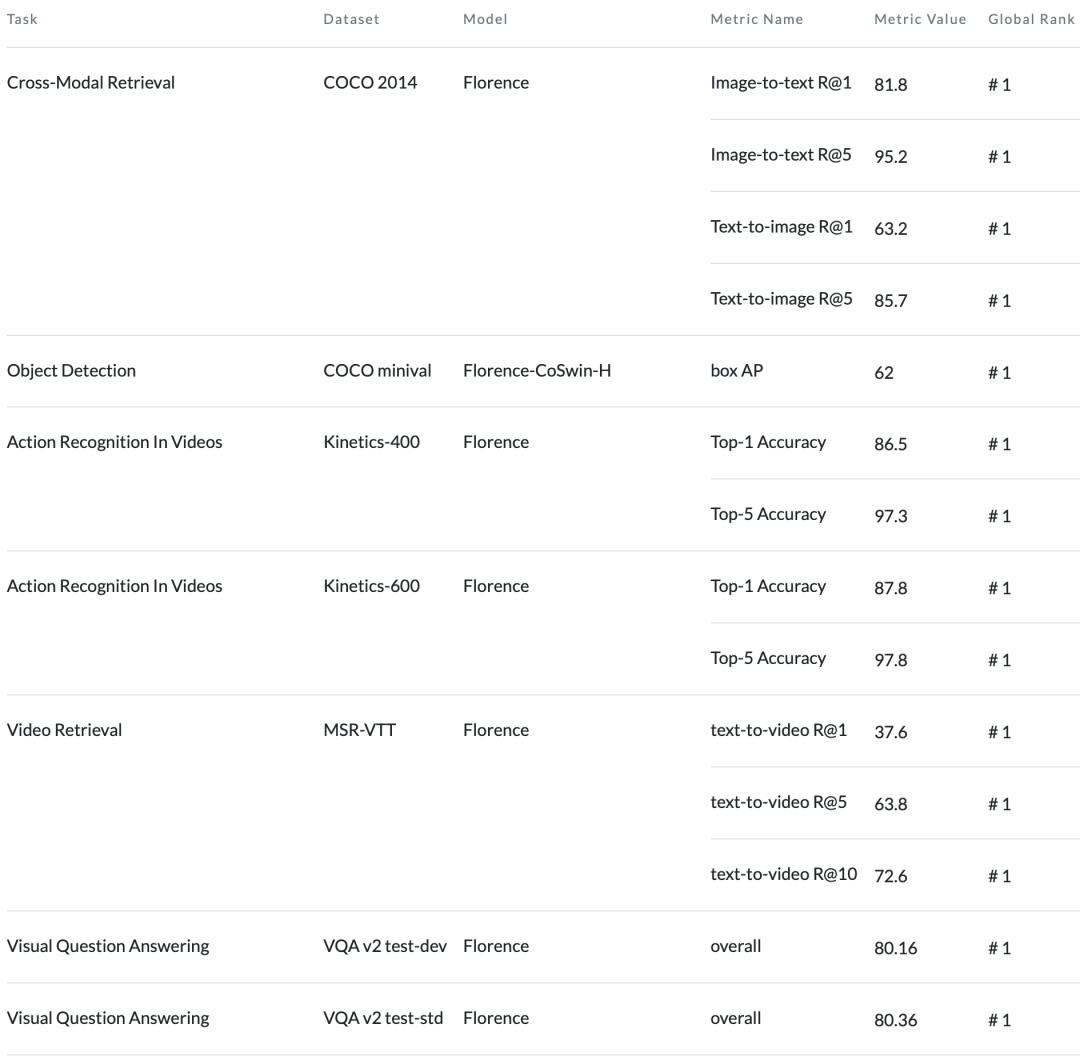
Florence在44个代表性基准中的大多数基准中实现了新的SOTA结果,例如ImageNet-1K zero-shot分类的Top-1准确率为83.74,Top-5准确率为97.18,COCO上微调可实现62 mAP,VQA上达到80.36,Kinetics-600上达到87.8。
![]() 部分结果展示
Florence成功地表明基础模型可以适应各种下游任务,最终集成到现代计算机视觉系统中,为现实世界的视觉和多媒体应用提供动力。
微软Azure AI首席技术官黄学东(Xuedong Huang)也发文称赞这一工作:
部分结果展示
Florence成功地表明基础模型可以适应各种下游任务,最终集成到现代计算机视觉系统中,为现实世界的视觉和多媒体应用提供动力。
微软Azure AI首席技术官黄学东(Xuedong Huang)也发文称赞这一工作:
经过近两年的时间,Project Florence(佛罗伦萨项目)大力推动了计算机视觉的现代化,并在40多个不同的计算机视觉基准任务上取得了新的SOTA。我们正在努力使计算机视觉的认知服务现代化,使其更容易为开发者所用。Florence将实现许多以前不可行的任务。期待未来令人兴奋的旅程!
利用互联网上公开的大量图像-文本数据,微软构建了FLD-900M(FLorenceDataset)数据集。
FLD-900M包含了9亿图像-文本对,970万个独特的查询,总共75亿个token,通过一个程序化的数据整理管道,并行处理大约30亿张互联网图像及其原始描述得到,并进行了严格的数据过滤以确保数据相关性和质量。
Florence预训练模型使用双塔结构:一个12层的Transformer作为语言编码器,类似于CLIP,和一个分层的视觉Transformer(ViT)作为图像编码器。
分层ViT采用的是一个经过修改的Swin Transformer,具有卷积嵌入功能,名为CoSwin Transformer。
Florence使用具有全局平均池的CoSwin Transformer来提取图像特征。在图像编码器和语言编码器的顶部添加了两个线性投影层,以匹配图像和语言特征的尺寸。
Florence预训练模型总共有893M的参数,包括有256M参数的语言Transformer和有637M参数的CoSwin-H Transformer,需要用512个NVIDIA A100 GPU训练10天。
CLIP隐式地假设了每个图像-文本对都有其独特的标注,其他图像会被认为是负样本。然而,在实际的网页数据中,多个图像可能会对应相同的标注。
其中,FLD-900M就包含了3.5亿个这种类型的图像-文本对。在对比学习中,所有与相同文本相关的图像都可以被视为正样本对。
为此,研究人员决定采用统一图像-文本对比学习(UniCL),其中Florence在图像-标签-描述空间中被预训练。
图像-标签空间的统一学习将两种流行的学习范式统一起来,将图像映射到标签上以学习辨别性的表征(即监督学习),并给每个描述分配一个独特的标签以进行语言-图像预训练(即对比学习)。
实验表明,具有丰富内容的长篇语言描述比短篇描述(如一两个词)更有利于图像-文本表征学习,微软通过生成提示模板的方式来丰富描述,并作为数据的补充。
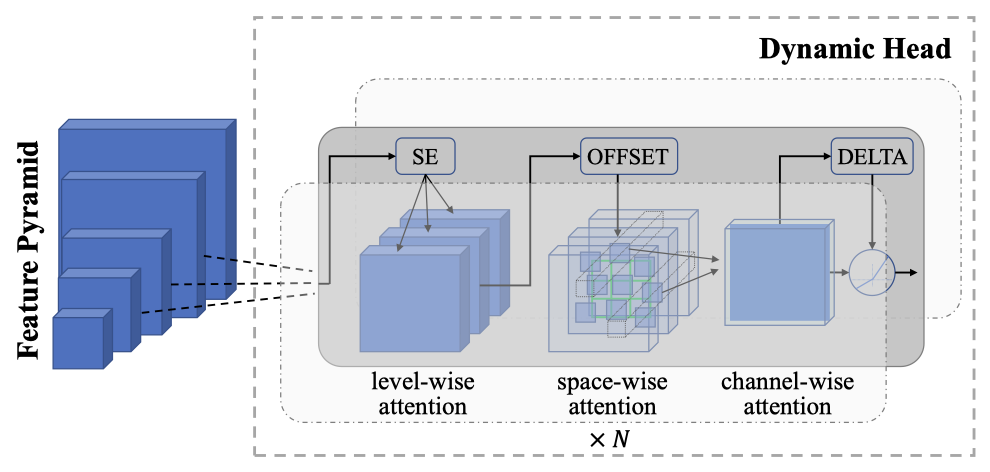
对于密集的预测任务(如目标检测)来说,学习细粒度(即对象层面)的表征是很重要的。
研究人员在预训练的图像编码器(即CoSwin)中加入了Dynamic Head作为adapter,从而实现从粗略的(场景)到精细的(对象)的视觉表示学习。
为此,研究人员构建了一个大规模的物体检测数据集,FLOD-9M(for FLorence Object detection Dataset),用于物体检测预训练。
FLOD-9M合并了几个著名的物体检测数据集,包括COCO、LVIS、OpenImages、Object365。此外,还通过在ImageNet-22K数据集上生成伪边界框,进一步扩大了我们的数据。最后,FLOD-9M涵盖了8,967,286张图像,25,190个对象类别,以及33,408,237个边界框,包括注释和伪标签。
然后,在128个NVIDIA-A100 GPU上用了7天的时间对Dynamic Head模型进行了12个epochs的预训练,batch size为128。
V+L(Vision+Language tasks)表征学习
同样,在视觉问题回答(VQA)和图像标注方面,细粒度的表征(即对象级别)也是必不可少的。
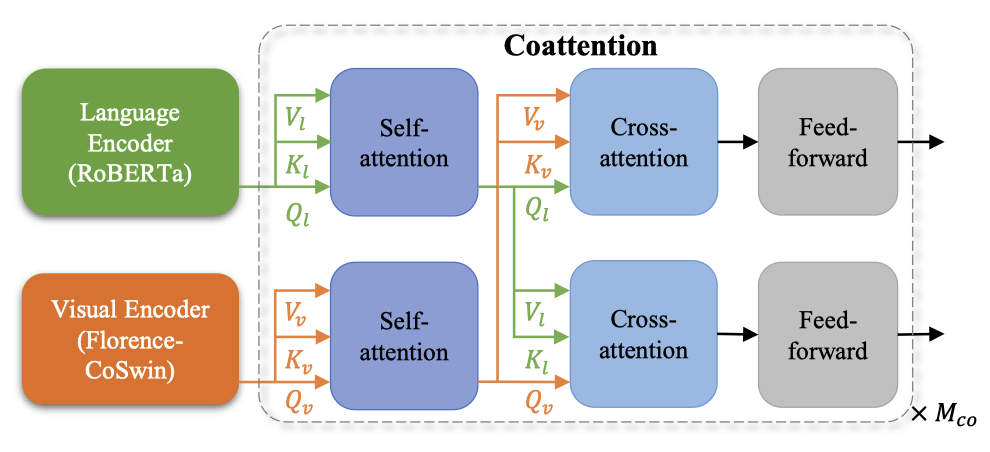
因此,在Florence的V+L(Vision+Language tasks)适应模型中,研究人员用预训练的CoSwin和预训练的Roberta作为语言编码器,以及METER作为adapter。
用图像-文本匹配(ITM)损失和掩码语言建模(MLM)损失进行训练
研究人员将上述两种模式融合在一起,用基于coattention的Transformer学习上下文表征。
共同注意力模型可以将文本和视觉特征分别送入两个Transformer,每个Transformer的顶层编码层包括一个自注意力块、一个交叉注意力块和一个前馈网络块。
训练时,先用图像-文本匹配损失和掩码语言建模损失来训练模型。然后,在下游的VQA任务上对模型进行微调。
Transformer中基于自注意的设计使得图像和视频识别系统的统一成为可能。比如,视频CoSwin adapter可以将CoSwin的图像编码器借用到视频领域。
首先,图像标记化层被替换为视频标记化层。相应地,视频CoSwin将CoSwin的标记化层从二维卷积层替换为三维卷积层,将每个三维管道转换为一个token。
作为3D卷积权重的初始化,CoSwin预训练的2D卷积权重沿着时间维度被复制,并除以时间核大小,以保持输出的平均值和方差不变。
视频CoSwin使用基于三维卷积的patch合并算子。这种重叠的合并可以增强token之间的空间和时间上的相互作用。
在自注意层中用三维移位的局部窗口取代二维移位的窗口设计,然后沿着时间维度复制预训练的CoSwin的二维相对位置嵌入矩阵来初始化三维位置嵌入矩阵。
此外,所有其他层和权重(包括自注意、FFN)都可以直接从预训练的CoSwin中继承。
在计算机视觉中,zero-shot学习通常是指通过描述性文本对类别进行预测。作为一个视觉基础模型,Florence可以直接用来预测图像和文本片段是否在任务数据集中语义上匹配。
实验部分遵循CLIP的设置,对于每个数据集,使用数据集中所有类的名称作为潜在文本对集,并使用Florence预测的最可能的「图像、文本」对。
通过语言编码器计算CoSwin图像的特征embedding和可能文本集的特征embedding,然后计算这些embedding之间的余弦相似性,对所有类别的相似性得分进行排序,选择前1或前5个类别作为预测类别。
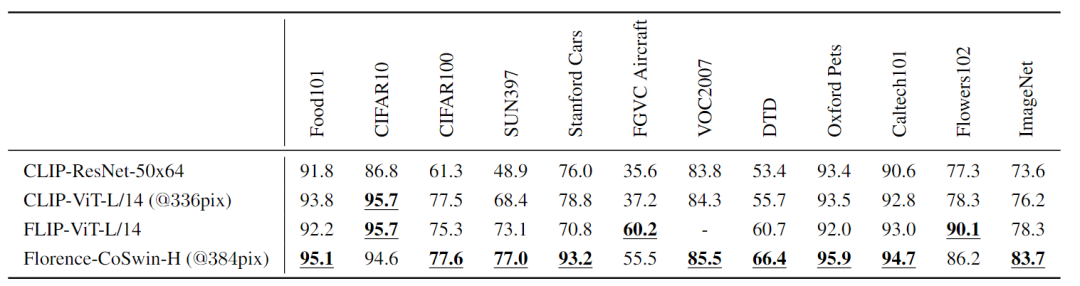
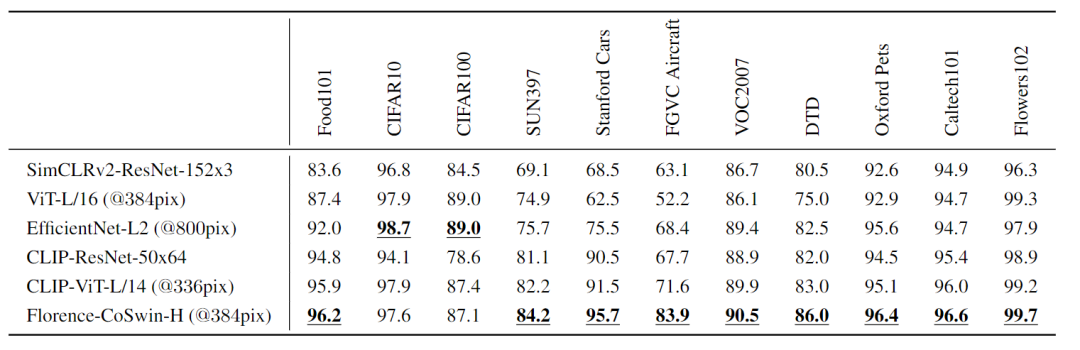
在ImageNet-1K数据集和11个下游数据集上,对Florence 模型进行评估,并与CLIP ResNet和Vision Transformer模型以及同时期的工作FLIP实现的最佳性能进行了比较。
Florence在12个任务中的9个表现优于SOTA模型,并且在ImageNet-1K上的zero-shot迁移方面取得了显著的改进,Top-1最高精度为83.74%(比之前SOTA结果高出5.6%),Top-5最高精度为97.18%。
在最近的研究,如自监督学习、带noisy student的自训练(self-training)和对比学习中,Linear Probe是评估模型质量的另一个重要指标。
对于Linear Probe,实验设置与CLIP相同,其中图像编码器(也是视觉模型的骨架网络)在训练中保持不变,只有附加的线性层可以在下游数据训练中进行微调。
对于每个任务,研究人员复现后的结果与其论文报告结果之间的方差为±0.1。Linear Probe考虑了11个分类基准,这些基准也用于zero-shot迁移分类实验。根据实验结果可以发现,Florence始终优于现有SOTA的结果。
在CIFAR10和CIFAR100这两个数据集中,输入图像的分辨率相当低(32×32),而分辨率更高的训练能够明显提高性能。
11个数据集的图像分类Linear Probe与现有的最新模型的比较,包括SimCLRV2、ViT、EfficientNet-L2和CLIP
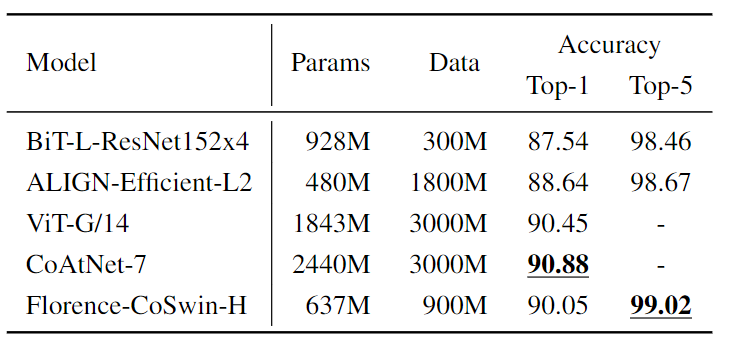
Florence可以轻松支持对新类别分类任务的连续微调。在不改变或添加任何东西到模型架构中的情况下,使用相同的预训练损失函数,继续针对特定任务的数据进行训练。将类名称输入到Florence的文本编码器,以获得文本特征的embedding。
研究人员在ImageNet ILSVRC-2012基准上评估了Florence连续微调的性能。使用CoSwin-H图像编码器在512×512的分辨率进行了微调,batch size为8192,训练10个epoch,使用余弦学习率衰减。
可以发现Florence模型的性能比具有更大的模型参数量的BiT效果还好,比接收更大规模数据训练的ALIGN模型在Top-1和Top-5精度上更好,结果仅略差于SoTA模型。
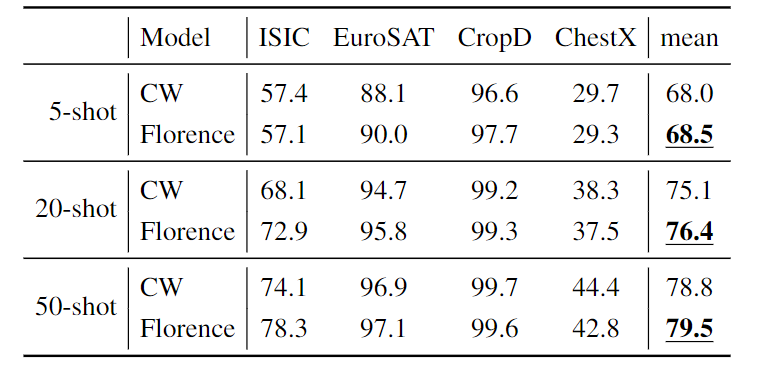
Few-Shot跨域分类能够衡量算法适应下游目标任务的能力。测试使用的基准数据包括:CropDisease (植物叶片图像,14种以上植物的38种疾病状态)、EuroSAT(RGB卫星图像,10类)、ISIC 2018(皮肤病变的DER-MOSCOPIC图像,7种疾病状态)和ChestX (胸部X射线,16种情况)。
评估包括5-shot、20-shot和50-shot的5-way分类。为了预测类别,研究人员将一个单层线性层作为CoSwin图像编码器的adapter head。
对于adapter head的动量SGD,学习率和动量值分别为0.99/0.01。在训练和测试中数据增强方法使用水平翻转,图像编码器和分类器头之间的dropout 率为0.5。
与其他ensemble模型相比,Florence模型使用的是一个单模型,并且还取得了更好的性能。
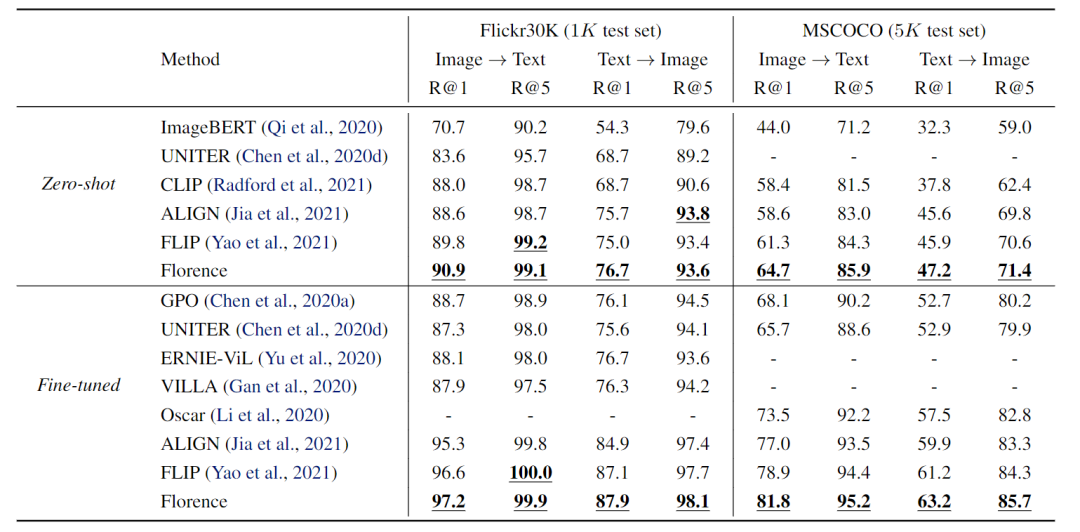
Image-Text检索实验数据集采用的是Flickr30K和MSCOCO。
对于zero-shot检索,研究人员将输入的文本(或图像)输入到Florence的语言(或图像)编码器中,并通过图像(或语言)编码器计算出一组可能的图像(或文本)的特征embedding。
然后计算这些embedding的余弦相似性,并将相似性分数排序到测试集上,以选择Top-1或Top-5的结果。
Florence的性能优于之前在两个数据集上取得的所有结果。
此外,Florence模型在检索时的微调效率更高,在Flickr30K和MSCoco上分别只需要ALIGN的6%到8%的微调epoch就可以。
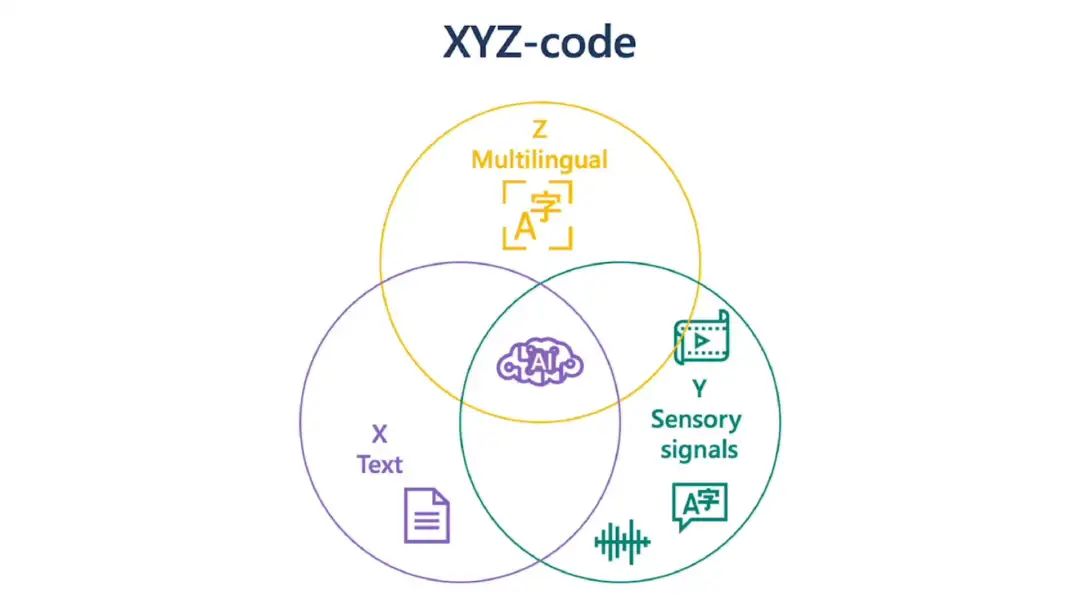
其实,我们可以从一个独特的视角来看待人类认知的三个属性之间的关系:单语言文本(X)、音频或视觉感官信号(Y)和多语言(Z)。
在这三者的交叉点上,有一种神奇的东西——XYZ-code。这种联合表征可以创造出更强大的AI,从而更好地说、听、看和理解。
未来,微软Florence项目将包括更多的视觉任务和应用,例如深度/流量估计、跟踪和更多的视觉-语言任务,为构建视觉基础模型铺平道路,并为数百万个真实世界的视觉任务和应用提供动力
参考资料:
https://arxiv.org/pdf/2111.11432.pdf
![]()




 部分结果展示
部分结果展示