来自微软的研究者另辟蹊径,提出了一种新的计算机视觉基础模型 Florence。在广泛的视觉和视觉 - 语言基准测试中,Florence 显著优于之前的大规模预训练方法,实现了新的 SOTA 结果。
面对多样化和开放的现实世界,要实现 AI 的自动视觉理解,就要求计算机视觉模型能够很好地泛化,最小化对特定任务所需的定制,最终实现类似于人类视觉的人工智能。计算机视觉基础模型在多样化的大规模数据集上进行训练,可以适应各种下游任务,对于现实世界的计算机视觉应用至关重要。
现有的视觉基础模型,如 CLIP (Radford et al., 2021)、ALIGN (Jia et al., 2021) 和悟道 2.0 等 ,主要侧重于将图像和文本表征映射为跨模态共享表征。近日来自微软的研究另辟蹊径提出了一种新的计算机视觉基础模型 Florence,将表征从粗粒度(场景)扩展到细粒度(对象),从静态(图像)扩展到动态(视频),从 RGB 扩展到多模态。
通过结合来自 Web 规模图像 - 文本数据的通用视觉语言表征, Florence 模型可以轻松地适应各种计算机视觉任务,包括分类、检索、目标检测、视觉问答(VQA)、图像描述、视频检索和动作识别。此外,Florence 在许多迁移学习中也表现出卓越的性能,例如全采样(fully sampled)微调、线性探测(linear probing)、小样本迁移和零样本迁移,这些对于视觉基础模型用于通用视觉任务至关重要。Florence 在 44 个表征基准测试中多数都取得了新的 SOTA 结果,例如 ImageNet-1K 零样本分类任务,top-1 准确率为 83.74,top-5 准确率为 97.18;COCO 微调任务获得 62.4 mAP,VQA 任务获得 80.36 mAP。
论文地址:
https://arxiv.org/pdf/2111.11432v1.pdf
Florence 模型在有噪声的 Web 规模数据上以同一个目标进行端到端训练,使模型能够在广泛的基准测试中实现同类最佳性能。在广泛的视觉和视觉 - 语言基准测试中,Florence 显著优于之前的大规模预训练方法,实现了新的 SOTA 结果。
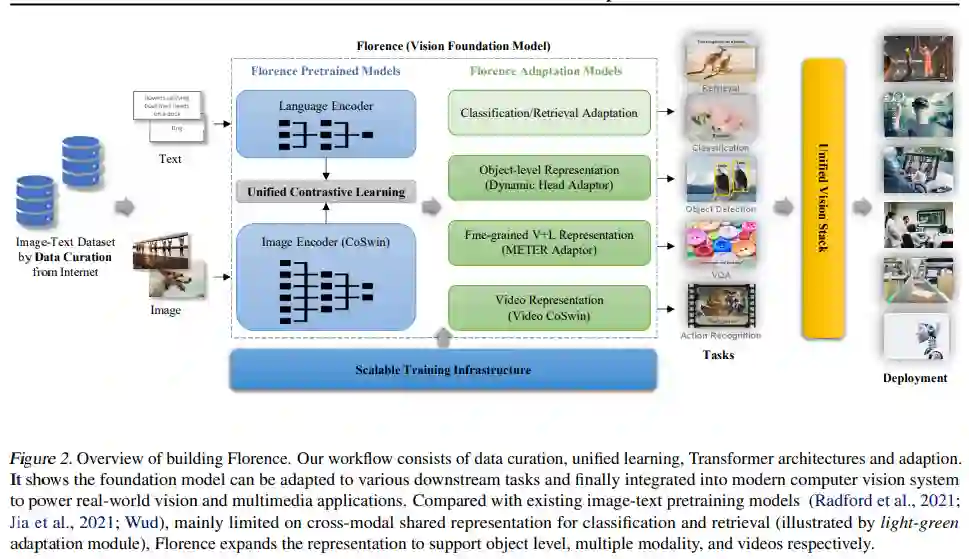
构建 Florence 生态系统包括数据管护、模型预训练、任务适配和训练基础设施,如图 2 所示。
由于大规模数据多样化对基础模型非常重要,因此该研究提出了一个包含 9 亿个图像 - 文本对的新数据集用于训练。由于网络爬取数据通常是具有噪音的自由格式文本(例如,单词、短语或句子),为了获得更有效的学习,该研究使用了 UniCL,这是 Yang 等人最近提出的「统一图像文本对比学习对象」,这种方法已经被证明其比对比和监督学习方法更优越。
为了从图像 - 文本对中学习良好的表示,该研究使用了包括图像编码器和语言编码器的两塔式(two-tower)架构。对于图像编码器,该研究选择了分层 Vision Transformer 。该研究所提架构在继承了 Transformer self-attention 操作性能优势的同时,这些分层架构对图像的尺度不变性进行了建模,并且具有相对于图像大小的线性计算复杂度,这是进行密集预测任务必不可少的属性。
该研究使用 dynamic head adapter(Dai et al., 2021a)、提出的 video CoSwin adapter 从静态图到视频的时间、METER adapter 从图像到语言的模态变化,通过以上该研究将学习到的特征表示沿空间(从场景到对象)进行扩展。Florence 旨在通过小样本和零样本迁移学习来有效适配开放世界,并通过很少的 epoch 训练(例如在检索中)进行有效部署。用户可以根据自己的需求进行定制。
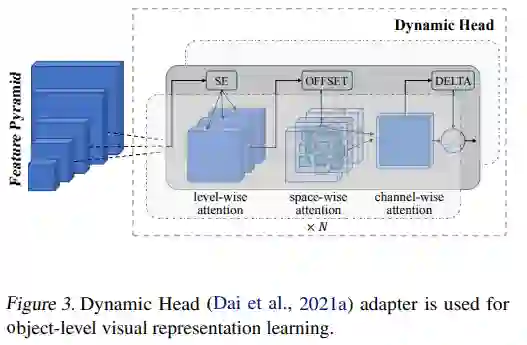
Dynamic Head (Dai et al., 2021a) adapter 用于对象级视觉表示学习。
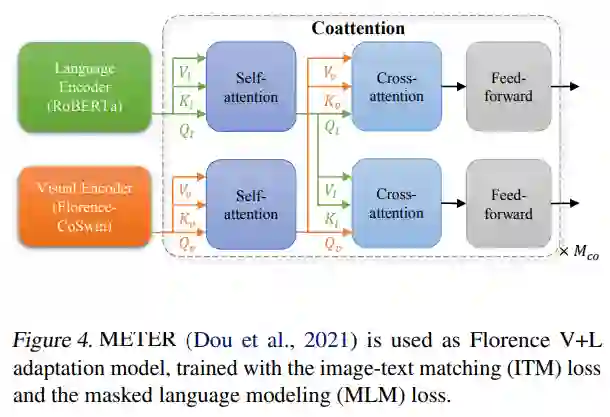
图 4. METER (Dou et al., 2021) 用作 Florence V+L 适配模型,使用图像文本匹配 (ITM) 损失和掩码语言建模 (MLM) 损失进行训练。
从能源和成本方面考虑,以尽可能低的成本构建基础模型是至关重要的。该研究开发了可扩展的训练基础设施,以提高训练效率。Florence 训练基础设施由 ZeRO 、激活检查点、混合精度训练、梯度缓存等多项关键技术组成,从而大大减少了内存消耗,提高了训练吞吐量。
该研究进行了多项实验,表明了 Florence 显著优于之前的大规模预训练方法。
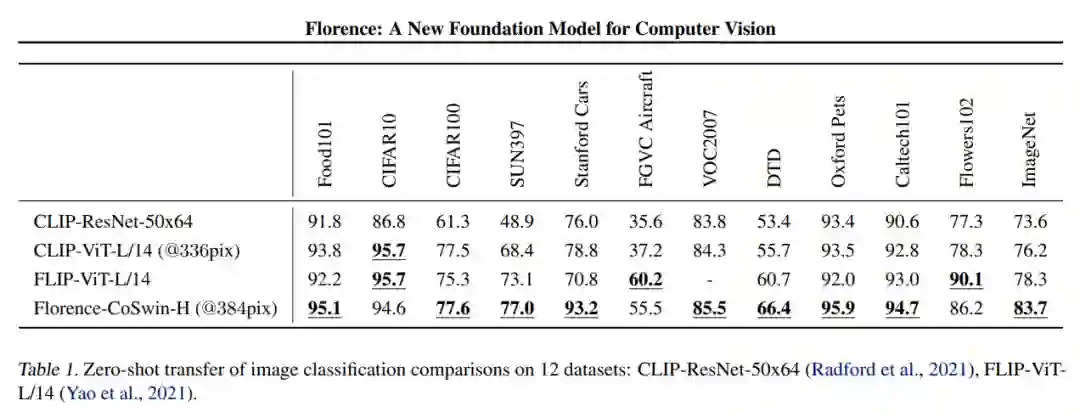
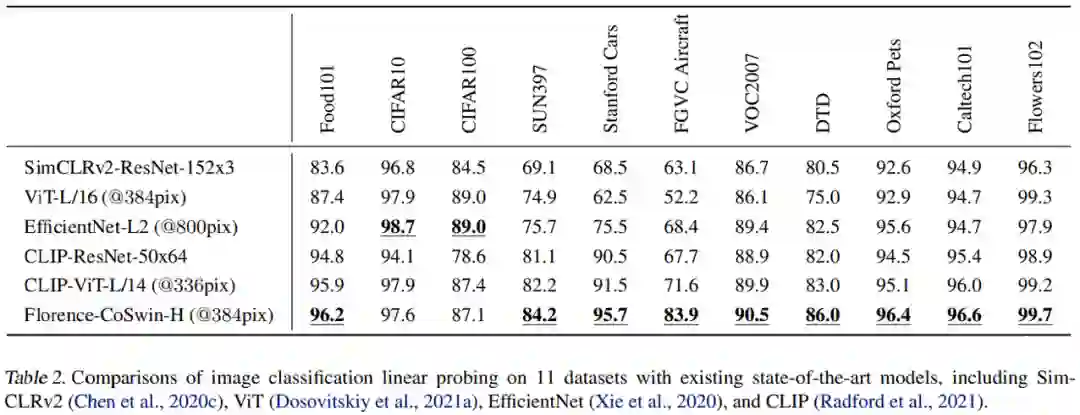
该研究在 ImageNet-1K 数据集和 11 个下游数据集上评估了 Florence 模型。表 1 显示了这 12 个数据集的结果,比较的模型包括 CLIP ResNet 、CLIP Vision Transformer 模型以及 FILIP-ViT,结果显示 Florence 在其中 9 个数据集上表现出色。该研究在 ImageNet-1K 上的零样本迁移方面取得了显着的提高,即 top-1 准确率为 83.74%(比 SOTA 结果高 5.6%),top-5 准确率为 97.18%。
线性评估考虑了 11 个分类基准,这些基准同样也适用于零样本分类迁移。该研究将 Florence 与具有 SOTA 性能的模型进行了比较,包括 SimCLRv2、ViT、Noisy Student 和 CLIP 。
结果表明,Florence 优于现有的 SOTA 结果,不过在 CIFAR10、CIFAR100 这两个数据集上性能不如 EfficientNet-L2 。
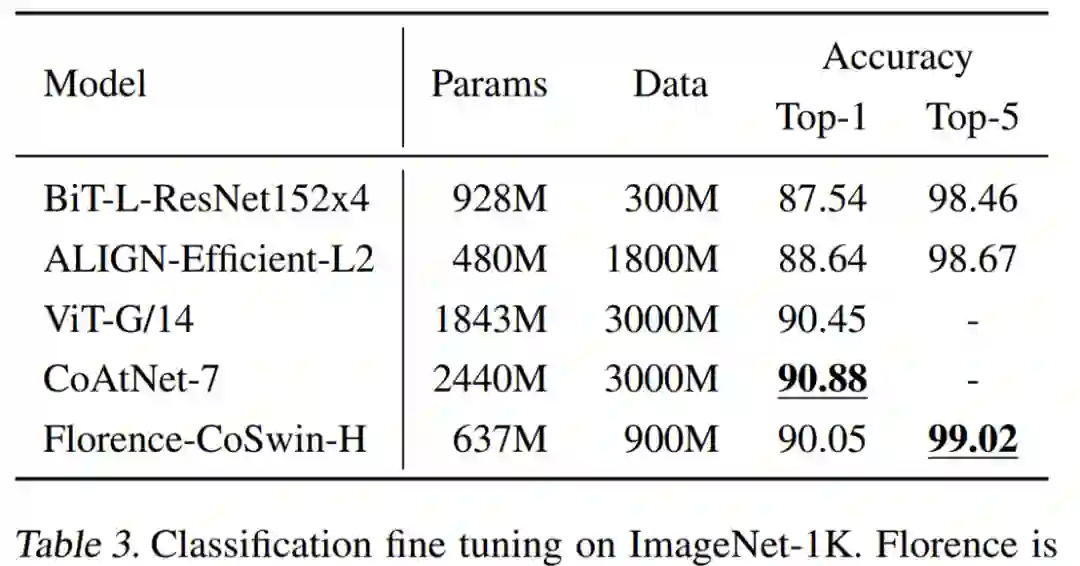
该研究在 ImageNet ILSVRC-2012 基准(Deng et al., 2009)上评估了持续微调的性能,Florence 与几种模型的比较结果如下表 3 所示。Florence 模型的 Top-1 和 Top-5 准确率均优于 BiT(Kolesnikov et al., 2020)和 ALIGN(Jia 等人,2021 年)。Florence 的结果比 SOTA 模型(Dai et al., 2021c)稍差,但其模型和数据规模都比 Florence 大了 3 倍。
下表 4 显示了 Florence 模型适应 CDFSL 基准的结果。与采用集成学习(ensembes learning)和直推学习(transductive learning)的挑战基准获胜者(Liu et al., 2020,下表中用 CW 指代)相比,Florence 采用单一模型,没有对测试数据进行转换,但获得了更优的结果。
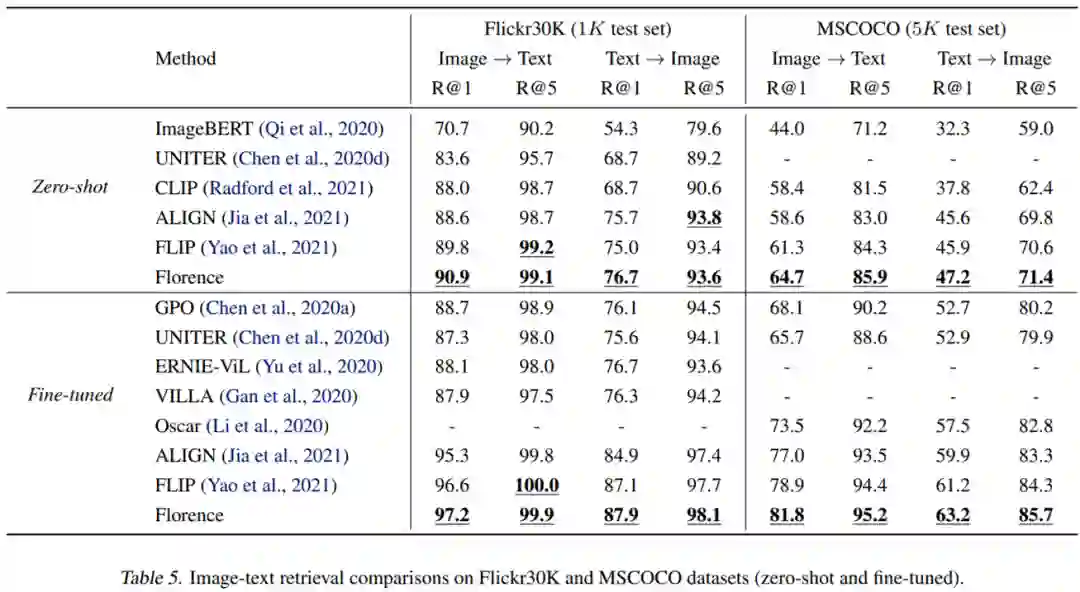
表 5 展示了 Florence 在 Flickr30k 和 MSCOCO 数据集上在文本和图像检索任务上的零样本迁移和微调性能。结果表明,在这两个数据集上,Florence 优于之前所有的微调结果。此外,该方法对检索微调更有效。
目标检测是计算机视觉中最突出的应用之一。与现有的大规模预训练模型(如 CLIP、ALIGN 和 Wu Dao 2.0)相比,Florence 更适用于目标检测任务,因为它的适应性有助于学习对象级视觉表征。研究者通过微调目标检测和零样本迁移任务对来 Florence 的对象级视觉表征性能进行评估。
具体地,研究者在 3 个流行的目标检测数据集上评估了微调性能,它们分别是 COCO(Lin et al., 2015)、Object365(Shao et al., 2019)和 Visual Genome(Krishna et al., 2016)。下表 6 展示了与 SOTA 结果的比较,可以看到,Florence 在这些目标检测基准上取得了新的 SOTA 结果。
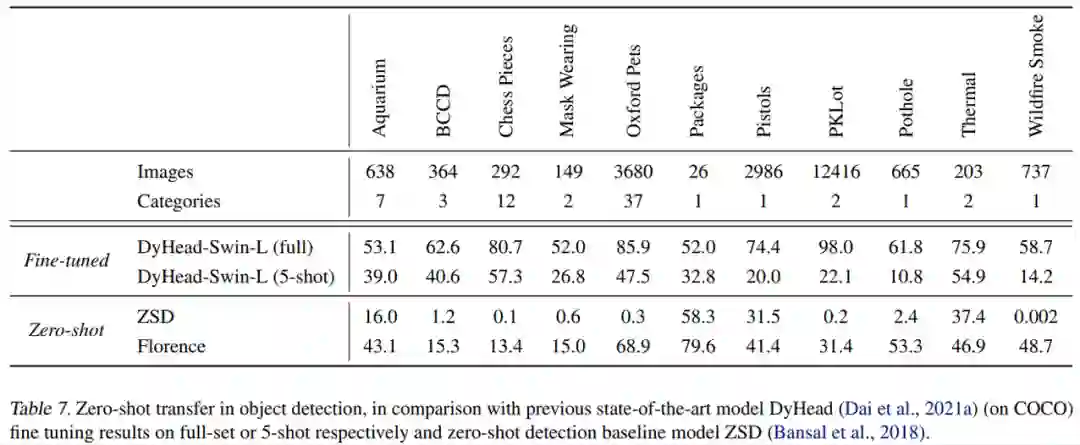
为了评估 Florence 对新的、多样性和面向应用的任务的迁移性,研究者遵循 (Li et al., 2021b) 设计了一个「开放式目标检测基准」,该基准聚合了来自 Roboflow2 的 11 个公共数据集,涵盖了细粒度鱼类 / 象棋检测、无人机视野检测和 thermal 目标检测等多样性场景。下表 7 表明,Florence 模型能够有效地实现到这些任务的零样本迁移。
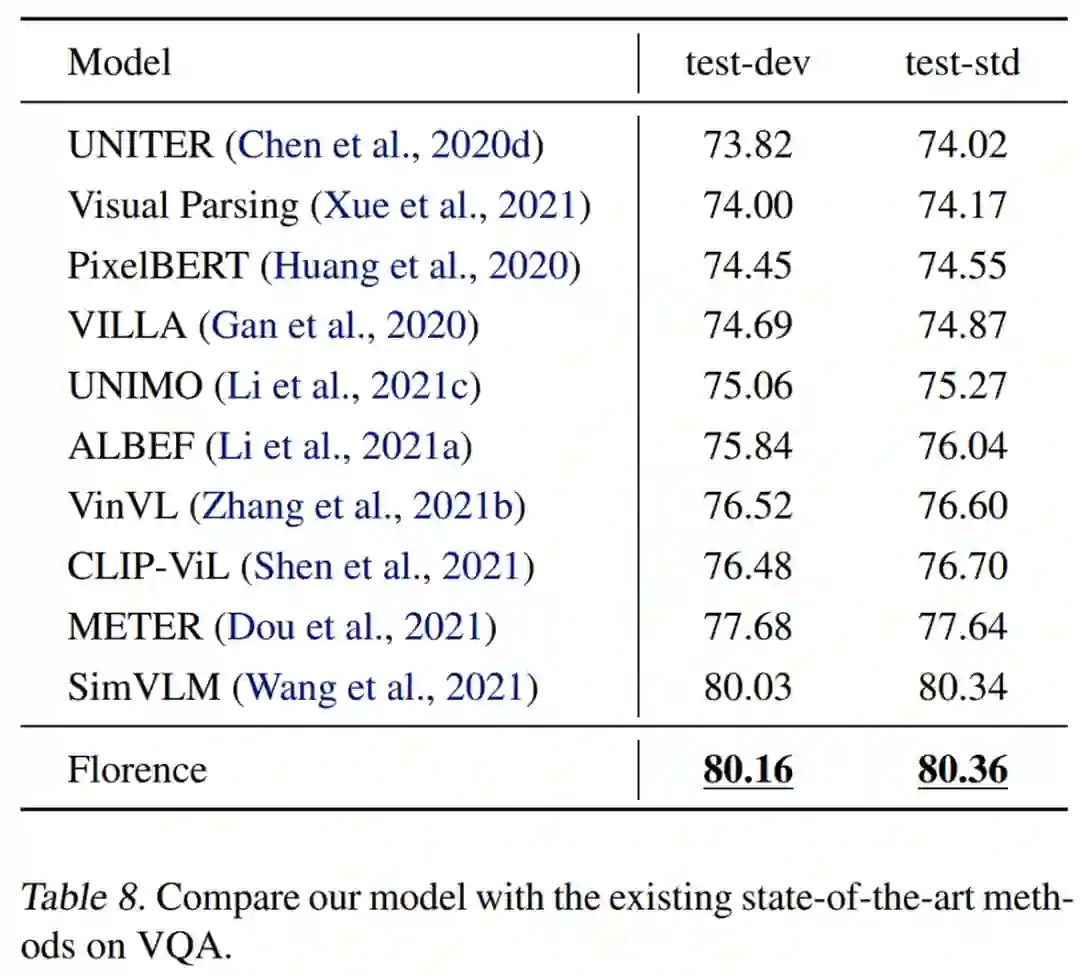
研究者在具有挑战性的 VQA (Goyal et al., 2017) 任务上对预训练模型进行了微调,该任务是根据图像上下文来回答问题。下表 8 展示了与当前方法的比较,结果表明 Florence 实现的了新的 SOTA 性能。与使用了 1.8B 图像到文本对的 SimVLM 模型(Wang et al., 2021)相比,Florence 仅使用 900M 数据即可以预训练图像编码器,20M 数据即可以预训练视觉语言预训练(VLP),但取得的结果更好。这也证明了 Florence 的数据效率。
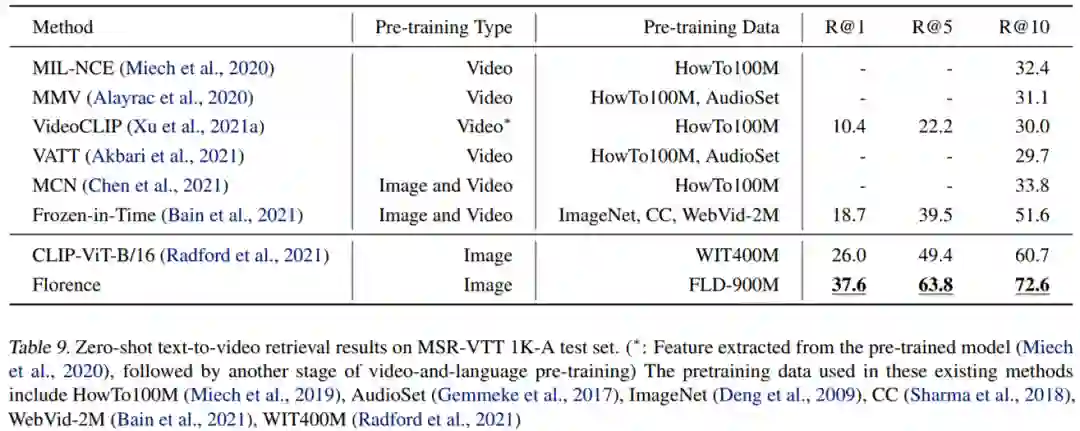
研究者在 MSR-VTT (Xu et al., 2016) 数据集上执行了零样本文本到视频评估,他们报告了在 1K-A test(Yu et al., 2018,包含 1k 个视频和字幕对)上的结果, 并在下表 9 中与当前 SOTA 方法进行了比较。结果表明,CLIP6(Radford et al., 2021)和 Florence 这两个图像到文本预训练模型在 R@1 指标上远远优于其他所有 SOTA 方法。
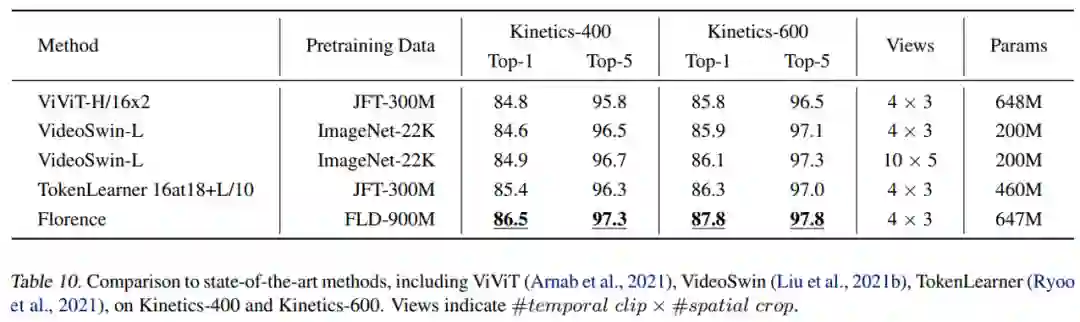
研究者在微调视频动作识别任务上对 Florence 进行评估。下表 10 展示了 Florence 与当前 SOTA 方法的比较,结果表明在 Kinectics-400 和 Kinectics-600 两个数据集上,分别比 SOTA 方法提升 1.1% 和 1.5%。
详解NVIDIA TAO系列分享第2期:
基于Python的口罩检测模块代码解析——快速搭建基于TensorRT和NVIDIA TAO Toolkit的深度学习训练环境
第2期线上分享将介绍如何利用NVIDIA TAO Toolkit,在Python的环境下快速训练并部署一个人脸口罩监测模型,同时会详细介绍如何利用该工具对模型进行剪枝、评估并优化。
TAO Toolkit 内包含了150个预训练模型,用户不用从头开始训练,极大地减轻了准备样本的工作量,让开发者专注于模型的精度提升。本次分享摘要如下:
-
-
-
利用TAO Toolkit快速训练人脸口罩检测模型
-
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com