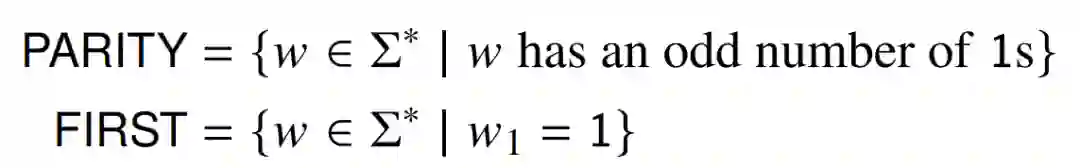机器之心 & ArXiv Weekly Radiostation
本周论文包括谷歌大牛 Jeff Dean 发文探索深度学习发展的黄金十年;Google Research 的研究者们提出了一种称为「自洽性(self-consistency)」的简单策略,显著提高了大型语言模型的推理准确率。
目录
A Golden Decade of Deep Learning: Computing Systems & Applications
Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Reconfigurable Magnetic Slime Robot: Deformation, Adaptability, and Multifunction
Video Diffusion Models
Overcoming a Theoretical Limitation of Self-Attention
RETHINKING NETWORK DESIGN AND LOCAL GEOMETRY IN POINT CLOUD: A SIMPLE RESIDUAL MLP FRAMEWORK
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:A Golden Decade of Deep Learning: Computing Systems & Applications
摘要:
自从计算机诞生之初,人类就梦想着能够创造出会思考的机器。1956 年在达特茅斯学院组织的一个研讨会上,约翰 · 麦卡锡提出人工智能这个概念,一群数学家和科学家聚集在一起寻找如何让机器使用语言、形成抽象理解和概念、以解决现存的各种问题,当时研讨会参与者乐观地认为,在几个月的时间里这些问题能取得真正的进展。
事实证明,预留几个月的时间安排过于乐观。在接下来的 50 年里,创建人工智能系统的各种方法开始流行,但后来又遭遇过时,包括基于逻辑的系统、基于规则的专家系统和神经网络。
直到 2011 年左右,人工智能才开始进入发展关键阶段,取得了巨大的进步,这得益于深度学习中神经网络的复兴,这些技术的进步有助于提高计算机看、听和理解周围世界的能力,使得人工智能在科学以及人类探索的其他领域取得巨大进步。这其中有哪些原因呢?
近日,谷歌大牛 Jeff Dean 发表了一篇文章《 A Golden Decade of Deep Learning: Computing Systems & Applications 》,文章探索了深度学习在这黄金十年里,计算系统以及应用进步的原因都有哪些?本文重点关注三个方面:促成这一进步的计算硬件和软件系统;过去十年在机器学习领域一些令人兴奋的应用示例;如何创建更强大的机器学习系统,以真正实现创建智能机器的目标。
Jeff Dean 的这篇文章发表在了美国文理学会会刊 Dædalus 的 AI 与社会(AI & Society)特刊上。
推荐:
谷歌大牛 Jeff Dean 单一作者撰文:深度学习研究的黄金十年。
论文 2:Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing
摘要:
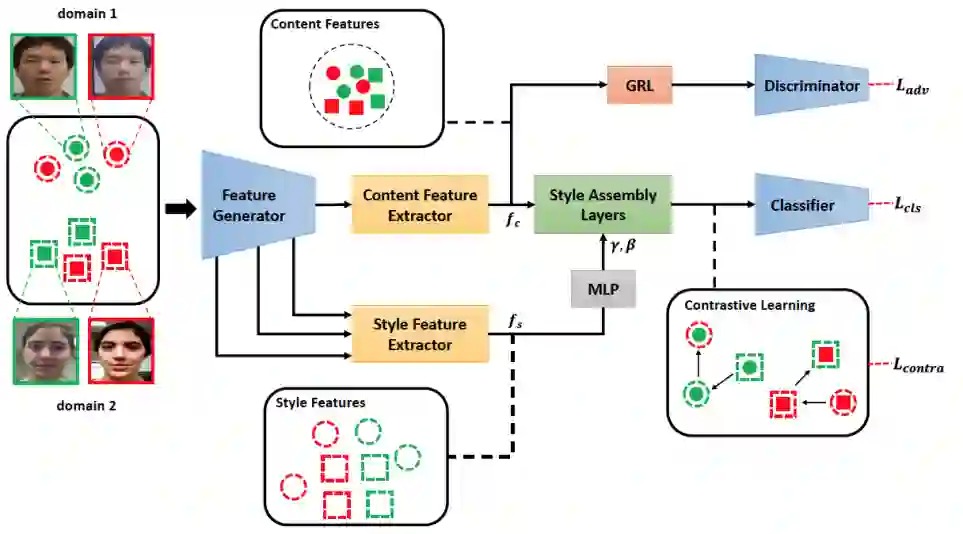
在这篇文章中,该研究提出了一个新的网络结构 SSAN,用以实现具有域泛化性的活体检测算法。与过去的方法直接在图像完全表征上提升域泛化性的思路不同,该研究基于内容特征和风格特征在统计特性上的差异,对他们实施不同的处理。具体而言,对于内容特征,本文采用了对抗学习的方式,使得网络无法对他们进行数据域层面的区分。对于风格特征,本文使用了对比学习的策略,来强化与活体相关的风格信息,同时抑制域信息相关的部分。然后,本文对配对的内容和风格特征进行组合,构成完全特征表示,并用以最后的分类。
此外,为了弥合学术界与工业界之间的差异,本文通过合并现有的公开数据集,建立了大规模活体检测测试协议。在现有的协议和本文所提出的协议上,所提出的 SSAN 算法均取得了最佳的表现。
本文方法的整体框架如图二所示。首先,本文使用一个双流网络来对图像的内容信息和风格信息进行提取。第二步,一种风格重组的方法被提出,以使不同的内容特征和风格特征进行组合。然后,为了抑制域相关的风格信息,同时增强活体相关的风格信息,本文在重组后的特征空间上使用了对比学习的策略。最后,总的损失函数用来训练所提出的网络。
推荐:
快手、北邮提出基于特征组合的域泛化性活体检测算法,多项 SOTA。
论文 3:Self-Consistency Improves Chain of Thought Reasoning in Language Models
摘要:
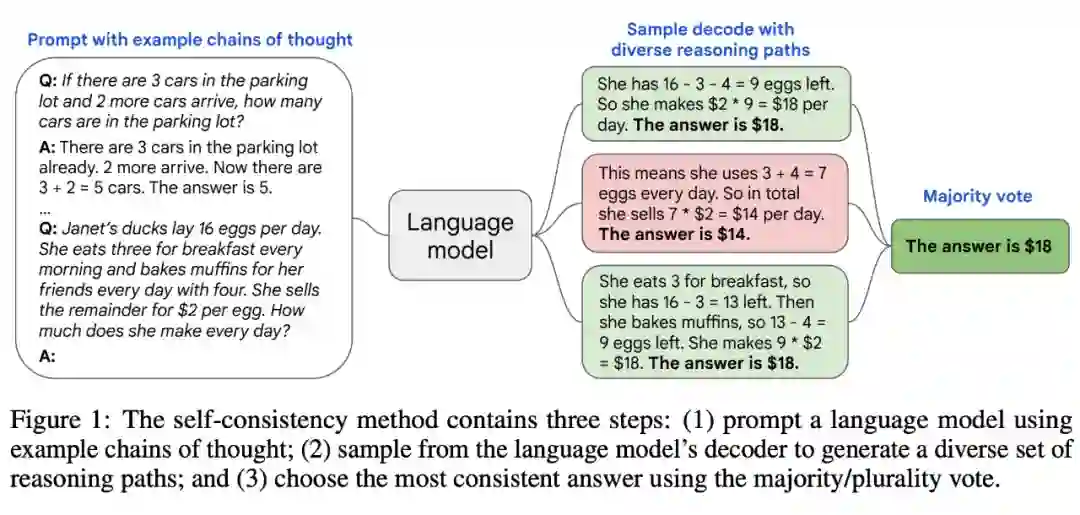
尽管语言模型在一系列 NLP 任务中取得了显著的成功,但它们的推理能力往往不足,仅靠扩大模型规模不能解决这个问题。基于此,Wei et al. (2022) 提出了思维提示链(chain of thought prompting),提示语言模型生成一系列短句,这些短句模仿一个人在解决推理任务时可能采用的推理过程。
现在来自 Google Research 的研究者们提出了一种称为「自洽性(self-consistency)」的简单策略,它显著提高了大型语言模型的推理准确率。
简单来说,复杂的推理任务通常有多个能得到正确答案的推理路径,自洽方法通过思维提示链从语言模型中采样一组不同的推理路径,然后返回其中最自洽的答案。
该方法在一系列算术和常识推理基准上评估自洽性,可以稳健地提高各种语言模型的准确性,而无需额外的训练或辅助模型。当与最近的大型语言模型 PaLM-540B 结合使用时,自洽方法将多个基准推理任务的性能提高到 SOTA 水平。
该方法是完全无监督的,预训练语言模型直接可用,不需要额外的人工注释,也不需要任何额外的训练、辅助模型或微调。
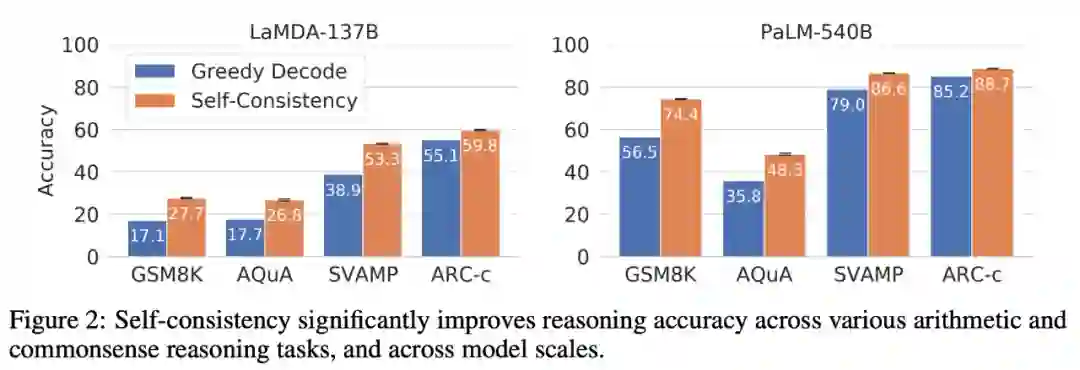
该研究在三种大型语言模型上评估一系列算术推理和常识推理任务的自洽性,包括 LaMDA-137B (Thoppilan et al., 2022)、PaLM-540B (Chowdhery et al., 2022) 和 GPT-3 175B (Brown et al., 2020)。研究者发现,对于这几种规模不同的语言模型,自洽方法都能显著提高其推理能力。与通过贪心解码(Wei et al., 2022)生成单一思维链相比,自洽方法有助于在所有推理任务中显著提高准确性,如下图 2 所示。
推荐:
用自洽性提升大模型推理能力,谷歌解答基准中 75% 数学问题,比 GPT-3 提升 20%。
论文 4:Reconfigurable Magnetic Slime Robot: Deformation, Adaptability, and Multifunction
摘要:
看过电影《毒液》的朋友都知道,「共生体」以液体状的形式出现,即使被打成肉泥或是一滩水,只要有足够的时间也可以恢复。现在,具有这般强大修复功能的机器人出现了。
这种「磁性粘液机器人」和粘液怪 slime 同名,是由来自哈尔滨工业大学和香港中文大学的研究者共同研发的,研究发表在同行评审期刊《Advanced Functional Materials》上。
slime 由聚乙烯醇、硼砂和钕磁铁颗粒的混合物制成。研究团队成员、香港中文大学教授张立说:「这种材料就像是水和淀粉的混合物,是一种非牛顿流体,其粘度会在外力作用下发生变化。当你快速触摸它时,它就像一个固体。当你轻轻地、慢慢地触摸它时,它就像液体一样。」
由于该粘液中含有钕磁铁等磁性颗粒,因此能够由磁铁控制其移动和变形,并且具有良好的导电性,可与电极相连,充当电路开关。
![]()
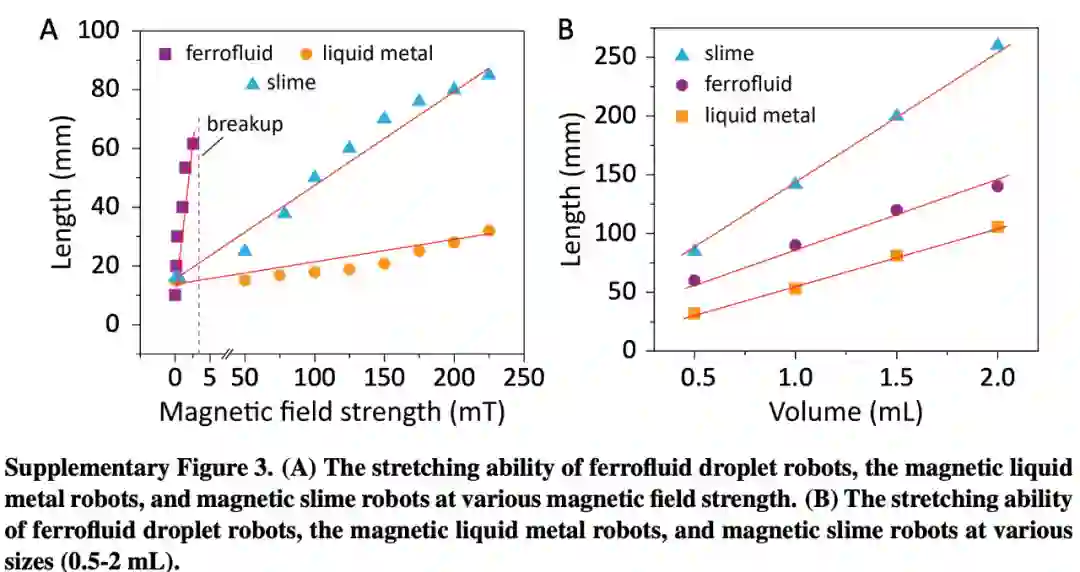
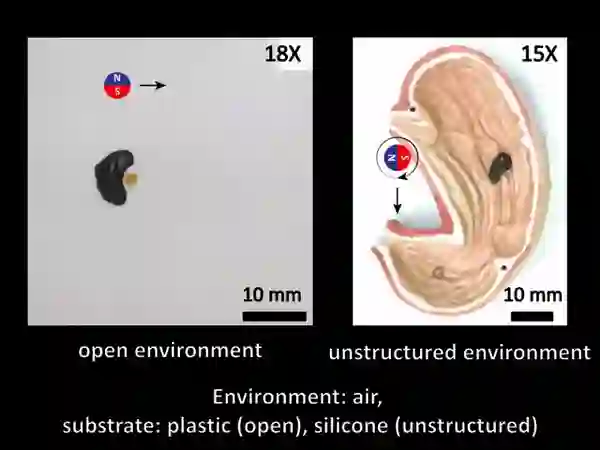
slime 具备极好的拉伸性能,可以通过 1.5mm 的狭窄缝隙而不断裂。该研究在相同的磁场条件下,比较了铁磁流体液滴机器人和 slime 的拉伸能力。
此外,slime 能够变成 O 形或 C 形来环绕细小的物体,一些科学家认为这可能对消化系统有用,例如减少吞下小电池的危害。他们认为使用这种粘液机器人对电池进行封装,形成一种惰性涂层,可以避免有毒电解质泄漏的危害。
![]()
推荐:
来自哈尔滨工业大学和香港中文大学的研究者共同研发了一种磁性粘液机器人,具有强大的变形功能。
论文 5:Video Diffusion Models
摘要:
扩散模型并不是一个崭新的概念,早在 2015 年就已经被提出。其核心应用领域包括音频建模、语音合成、时间序列预测、降噪等。
那么它在视频领域表现如何?先前关于视频生成的工作通常采用诸如 GAN、VAE、基于流的模型。
在视频生成领域,研究的一个重要里程碑是生成时间相干的高保真视频。来自谷歌的研究者通过提出一个视频生成扩散模型来实现这一里程碑,显示出非常有希望的初步结果。本文所提出的模型是标准图像扩散架构的自然扩展,它可以从图像和视频数据中进行联合训练,研究发现这可以减少小批量梯度的方差并加快优化速度。
为了生成更长和更高分辨率的视频,该研究引入了一种新的用于空间和时间视频扩展的条件采样技术,该技术比以前提出的方法表现更好。
![]()
这项研究有哪些亮点呢?首先谷歌展示了使用扩散模型生成视频的首个结果,包括无条件和有条件设置。先前关于视频生成的工作通常采用其他类型的生成模型,如 GAN、VAE、基于流的模型和自回归模型。
其次该研究表明,可以通过高斯扩散模型的标准公式来生成高质量的视频,除了直接的架构更改以适应深度学习加速器的内存限制外,几乎不需要其他修改。该研究训练生成固定数量的视频帧块的模型,并且为了生成比该帧数更长的视频,他们还展示了如何重新调整训练模型的用途,使其充当对帧进行块自回归的模型。
下图左为利用梯度方法的视频帧,图右为利用自回归扩展基线替代(replacement)方法的帧。可以看到,使用梯度方法采用的视频比基线方法具有更好的时间相干性。
推荐:
视频生成无需 GAN、VAE,谷歌用扩散模型联合训练视频、图像,实现新 SOTA。
论文 6:Overcoming a Theoretical Limitation of Self-Attention
摘要:
尽管 transformer 模型在许多任务中都非常有效,但它们对一些看起来异常简单的形式语言却难以应付。Hahn (2020) 提出一个引理 5),来试图解释这一现象。这个引理是:改变一个输入符号只会将 transformer 的输出改变 𝑂(1/𝑛),其中 𝑛 是输入字符串的长度。
因此,对于接收(即判定某个字符串是否属于某个特定语言)只取决于单个输入符号的语言,transformer 可能会以很高的准确度接受或拒绝字符串。但是对于大的 𝑛,它必须以较低的置信度做出决策,即给接受字符串的概率略高于 ½,而拒绝字符串的概率略低于 ½。更准确地说,随着 𝑛 的增加,交叉熵接近每个字符串 1 比特,这是最坏情况的可能值。
近期,在论文《Overcoming a Theoretical Limitation of Self-Attention》中,美国圣母大学的两位研究者用以下两个正则语言(PARITY 和 FIRST)来检验这种局限性。
Hahn 引理适用于 PARITY,因为网络必须关注到字符串的所有符号,并且其中任何一个符号的变化都会改变正确答案。研究者同时选择了 FIRST 作为引理适用的最简单语言示例之一。它只需要注意第一个符号,但因为更改这个符号会改变正确答案,所以该引理仍然适用。
尽管该引理可能被解释为是什么限制了 transformer 识别这些语言的能力,但研究者展示了三种可以克服这种限制的方法。
首先,文章通过显式构造表明,以高准确度识别任意长度的语言的 transformer 确实是存在的。研究者已经实现了这些结构并通过实验验证了它们。正如 Hahn 引理所预测的那样,随着输入长度的增加,这个构建的 transformer 的交叉熵接近 1 比特(也就是,仅比随机猜测好一点)。但文章也表明,通过添加层归一化,交叉熵可以任意接近零,而与字符串长度无关。
研究者在实践中还发现,正如 Bhattamishra 等人所指出的,transformer 无法学习 PARITY。也许更令人惊讶的是,在学习 FIRST 时,transformer 可能难以从较短的字符串泛化到较长的字符串。尽管这不是 Hahn 引理的逻辑上可以推出的结果,但它是 Hahn 引理预测行为的结果。幸运的是,这个问题可以通过简单的修改来解决,即将注意力的 logit 乘以 log 𝑛。此修改还改进了机器翻译中在长度方面的泛化能力。
推荐:
有论文检验了 transformer 在两种形式语言上的理论缺陷,并且设计了方法克服这种缺陷。
论文 7:RETHINKING NETWORK DESIGN AND LOCAL GEOMETRY IN POINT CLOUD: A SIMPLE RESIDUAL MLP FRAMEWORK
摘要:
3D 点云数据由于其无序性 (unorderness)、稀疏性 (sparisity) 和不规则性(irregularity)等特点,往往难以处理。为了描述 3D 数据的几何特征,研究者专注于局部几何的获取,提出各种基于卷积、图卷积或者注意力机制的「复杂的」局部几何描述模块。然而这些操作往往会导致较慢的推理速度,并没有带来实质的提高。
近日,来自美国东北大学和哥伦比亚大学的研究者发现,复杂的局部几何描述模块也许并不是 3D 网络的关键, 一个纯 MLP 架构的网络能取得更好的结果,并且能够大幅提升推理速度。该论文已被 ICLR 2022 接收,代码已经开源。
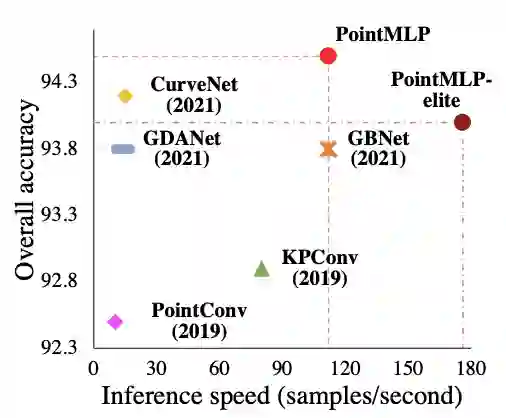
作者引入了一个轻量级的局部几何仿射模块,可以自适应地转换局部区域中的点特征。由此提出的新网络架构称为 PointMLP。下图显示了 PointMLP 在 modelNet40 上与其他网络的速度 / 准确率比较。
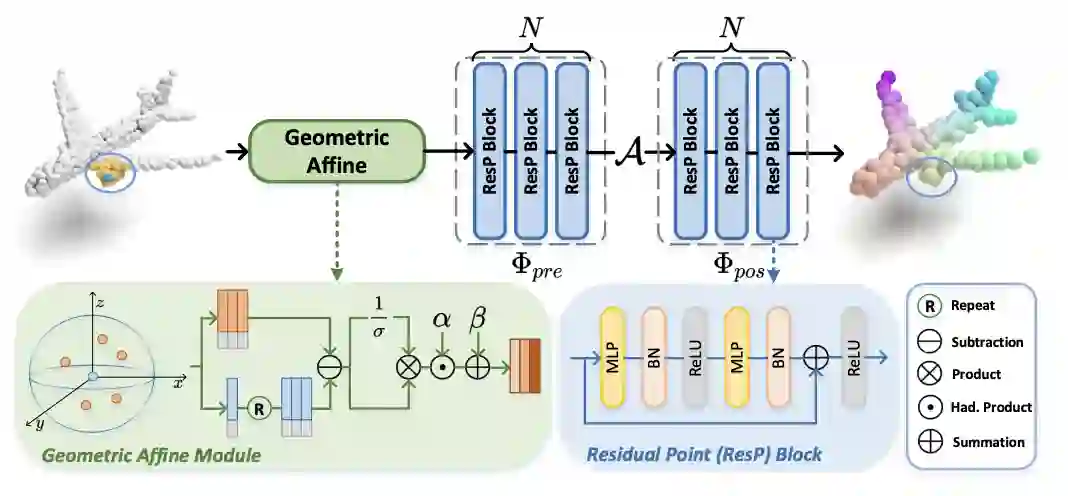
PointMLP 的架构非常简单,与传统的点云网络类似, PointMLP 也采用了阶段结构,每一阶段(stage)通过最远点下采样以减少计算量。下图展示了 PointMLP 任意一阶段的操作。
给定输入点云,PointMLP 使用残差点 MLP 块逐步提取局部特征。在每个阶段,PointMLP 首先使用几何仿射模块 (Geometric Affine Module)对局部点进行仿射变换,然后通过几个残差 MLP 模块 (Residual Point Block) 来提取深层的特征。注意此时的局部区域中仍包含多个点,作者通过一个简单的聚合器 (使用的是 max-pooling) 来将局部多个点聚合成一个点以描述局部信息, 并且再次使用残差 MLP 模块来提取特征。
PointMLP 通过重复多个阶段 (每个阶段中通道数翻倍) 逐步扩大感受野,并模拟完整的点云几何信息。为了进一步提高推理速度、减轻模型大小,该研究减少了每个阶段的通道数以及残差 MLP 模块的个数,并在残差 MLP 模块中引入了瓶颈 (bottleneck) 结构。研究者将得到的更加轻量化的版本称作 PointMLP-elite。
推荐:
纯 MLP 的点云网络:新架构 PointMLP 大幅提高点云分类准确率和推理速度。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. A Distant Supervision Corpus for Extracting Biomedical Relationships Between Chemicals, Diseases and Genes. (from Andrew McCallum)
2. PSP: Pre-trained Soft Prompts for Few-Shot Abstractive Summarization. (from Yang Gao)
3. CUNI-KIT System for Simultaneous Speech Translation Task at IWSLT 2022. (from Alexander Waibel)
4. Label Semantic Aware Pre-training for Few-shot Text Classification. (from Dan Roth)
5. Unified Speech-Text Pre-training for Speech Translation and Recognition. (from Abdelrahman Mohamed)
6. Beam Decoding with Controlled Patience. (from Dragomir Radev, Noah A. Smith)
7. Learning to Generalize to More: Continuous Semantic Augmentation for Neural Machine Translation. (from Rong Jin)
8. EHRKit: A Python Natural Language Processing Toolkit for Electronic Health Record Texts. (from Dragomir Radev)
9. Rows from Many Sources: Enriching row completions from Wikidata with a pre-trained Language Model. (from Chin-Yew Lin)
10. Decomposed Meta-Learning for Few-Shot Named Entity Recognition. (from Chin-Yew Lin)
本周 10 篇 CV 精选论文是:
1. SpoofGAN: Synthetic Fingerprint Spoof Images. (from Anil K. Jain)
2. Open-World Instance Segmentation: Exploiting Pseudo Ground Truth From Learned Pairwise Affinity. (from Jitendra Malik)
3. Simple Baselines for Image Restoration. (from Xiangyu Zhang, Jian Sun)
4. ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension. (from Trevor Darrell)
5. Rapid model transfer for medical image segmentation via iterative human-in-the-loop update: from labelled public to unlabelled clinical datasets for multi-organ segmentation in CT. (from Lei Zhang)
6. Towards Reliable Image Outpainting: Learning Structure-Aware Multimodal Fusion with Depth Guidance. (from Lei Zhang)
7. Defensive Patches for Robust Recognition in the Physical World. (from Dacheng Tao)
8. Panoptic-PartFormer: Learning a Unified Model for Panoptic Part Segmentation. (from Dacheng Tao)
9. Fashionformer: A simple, Effective and Unified Baseline for Human Fashion Segmentation and Recognition. (from Dacheng Tao)
10. Probabilistic Representations for Video Contrastive Learning. (from Ig-Jae Kim)
本周 10 篇 ML 精选论文是:
1. Approximation of Lipschitz Functions using Deep Spline Neural Networks. (from Michael Unser)
2. The Two Dimensions of Worst-case Training and the Integrated Effect for Out-of-domain Generalization. (from Eric P. Xing)
3. METRO: Efficient Denoising Pretraining of Large Scale Autoencoding Language Models with Model Generated Signals. (from Tie-Yan Liu, Jianfeng Gao)
4. Neural Operator with Regularity Structure for Modeling Dynamics Driven by SPDEs. (from Tie-Yan Liu)
5. Out-of-distribution Detection with Deep Nearest Neighbors. (from Xiaojin Zhu)
6. Federated Learning with Partial Model Personalization. (from Abdelrahman Mohamed, Lin Xiao)
7. Unsupervised Anomaly and Change Detection with Multivariate Gaussianization. (from Gustau Camps-Valls)
8. When Should We Prefer Offline Reinforcement Learning Over Behavioral Cloning?. (from Sergey Levine)
9. Generative Negative Replay for Continual Learning. (from Davide Maltoni)
10. Accelerated Policy Learning with Parallel Differentiable Simulation. (from Wojciech Matusik)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com