完全基于Transformer的目标检测器,ICLR匿名论文实现视觉、检测统一

极市导读
一种新的集成视觉和检测 Transformer 的目标检测器 ViDT。ViDT 在现有的完全基于 transformer 的目标检测器中获得了最佳的 AP 和延迟权衡,其对大型模型的高可扩展性,可达 49.2AP。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
Transformer 在 NLP 任务中取得不错的发展,许多研究将其引入到计算机视觉任务中。毫不夸张的说,Transformer 正在改变计算机视觉的格局,尤其是在识别任务方面。例如 Detection transformer 是第一个用于目标检测的、端到端的学习系统,而 vision transformer 是第一个完全基于 transformer 的图像分类架构。在本文中,一篇被 ICLR 2022 接收的匿名论文集成了视觉和检测 Transformer (Vision and Detection Transformer,ViDT) 来构建有效且高效的目标检测器。
ViDT 引入了一个重新配置的注意力模块(reconfigured attention module),将 Swin Transformer 扩展为一个独立的目标检测器,之后是一个计算高效的 Transformer 解码器,该解码器利用多尺度特征和辅助(auxiliary)技术,在不增加计算负载的情况下提高检测性能。
在 Microsoft COCO 基准数据集上的评估表明,ViDT 在现有的完全基于 transformer 的目标检测器中获得了最佳的 AP 和延迟权衡,其对大型模型的高可扩展性,可达 49.2AP。

论文地址:https://openreview.net/pdf?id=w4cXZDDib1H
ViDT:视觉与检测 Transformer
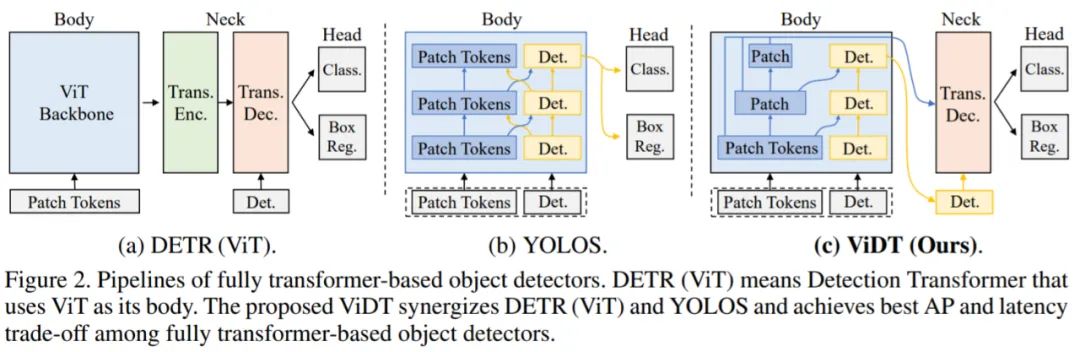
ViDT 架构如下图 2 (c) 所示:
-
首先,ViDT 引入了一种改进的注意力机制,名为 Reconfigured Attention Module (RAM),该模块有助于 ViT 变体处理附加的 [DET(detection tokens)] 和 [PATCH(patch tokens)] token 以进行目标检测。因此,ViDT 可以将最新的带有 RAM 的 Swin Transformer 主干修改为目标检测器,并利用其具有线性复杂度的局部注意力机制获得高可扩展性;
-
其次,ViDT 采用轻量级的无编码器 neck 架构来减少计算开销,同时仍然在 neck 模块上启用额外的优化技术。请注意,neck 编码器是不必要的,因为 RAM 直接提取用于目标检测的细粒度表示,即 [DET ] token。结果,ViDT 获得了比 neck-free 对应物更好的性能;
-
最后,该研究引入了用于知识蒸馏的 token 匹配新概念,它可以在不影响检测效率的情况下从大型模型到小型模型带来额外的性能提升。
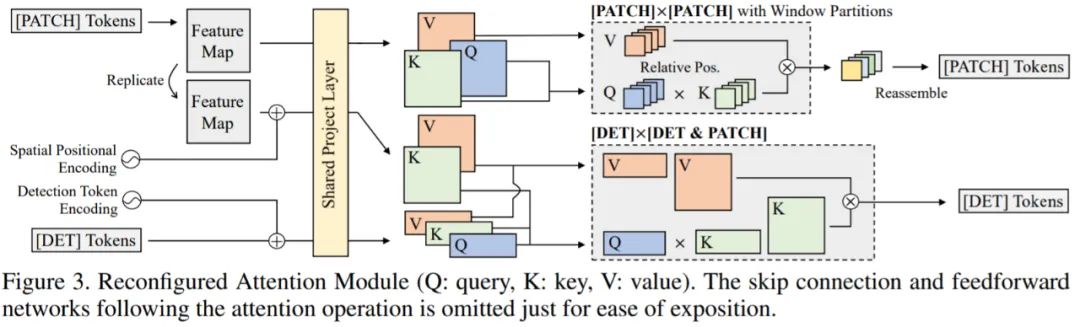
RAM 模块
该研究引入了 RAM 模块,它将与 [PATCH] 和 [DET] token 相关的单个全局注意力分解为三个不同的注意力,即 [PATCH]×[PATCH]、[DET]× [DET] 和 [DET] × [PATCH] 注意力。如图 3 所示,通过共享 [DET] 和 [PATCH] token 的投影层,全部复用 Swin Transformer 的所有参数,并执行三种不同的注意力操作:
ENCODER-FREE neck 结构
为了利用多尺度特征图,ViDT 结合了多层可变形 transformer 解码器。在 DETR 家族中(图 2 (a)),其 neck 部分需要一个 transformer 编码器,用于将从骨干中提取的用于图像分类的特征转换为适合目标检测的特征;编码器通常在计算上很昂贵,因为它涉及 [PATCH] × [PATCH] 注意力。然而,ViDT 只保留了一个 Transformer 解码器作为其 neck,因为带有 RAM 的 Swin Transformer 直接提取适合目标检测的细粒度特征作为独立的目标检测器。因此,ViDT 的 neck 结构在计算上是高效的。
解码器从带有 RAM 的 Swin Transformer 接收两个输入:(1)从每个阶段生成的 [PATCH] token(2)从最后阶段生成的 [DET ] token,如图 2 (c) 的 Neck 所示。在每个可变形的 transformer 层中,首先执行 [DET] × [DET] 注意力。对于每个 [DET] token,应用多尺度可变形注意力以生成一个新的 [DET] token,聚合从多尺度特征图
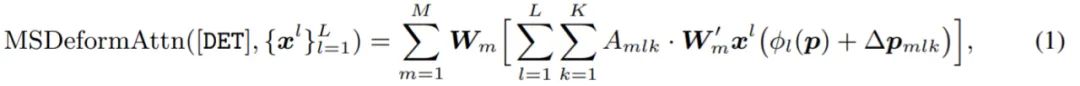
用于目标检测的 token 匹配知识蒸馏
虽然大型模型具有实现高性能的高容量,但在实际使用中它的计算成本可能很高。因此,该研究还提出了一种简单的知识蒸馏方法,可以通过 token 匹配从大型 ViDT 模型中迁移知识。
匹配每一层的所有 token 在训练中非常低效,因此,该研究只匹配对预测贡献最大的 token。两组 token 直接相关:(1)P:用作多尺度特征图的 [PATCH] token 集合,由 body 中的每个阶段生成,(2)D:[DET ] token 的集合,它们是从 neck 的每个解码层生成的。因此,基于 token 匹配的蒸馏损失公式为:
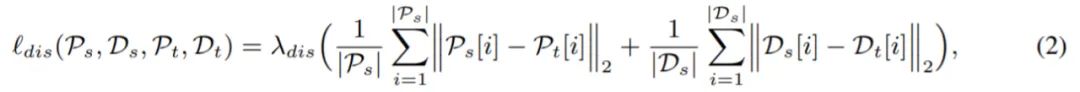
评估
表 2 将 ViDT 与 DETR (ViT) 和 YOLOS 的 AP、FPS 等进行了比较,其中 DETR (ViT) 有两个变体:DETR 和 Deformable DETR。
实验结果表明:ViDT 实现了 AP 和 FPS 之间的最佳权衡。凭借其高可扩展性,其性能优于 1 亿个参数的 Swin-base,在相似的 AP 的下,FPS 比 Deformable DETR 快 2 倍。此外,ViDT 参数为 16M,得到 40.4AP,比 DETR (swin-nano) 和 DETR (swin-tiny) 高分别高 6.3AP、12.6AP。
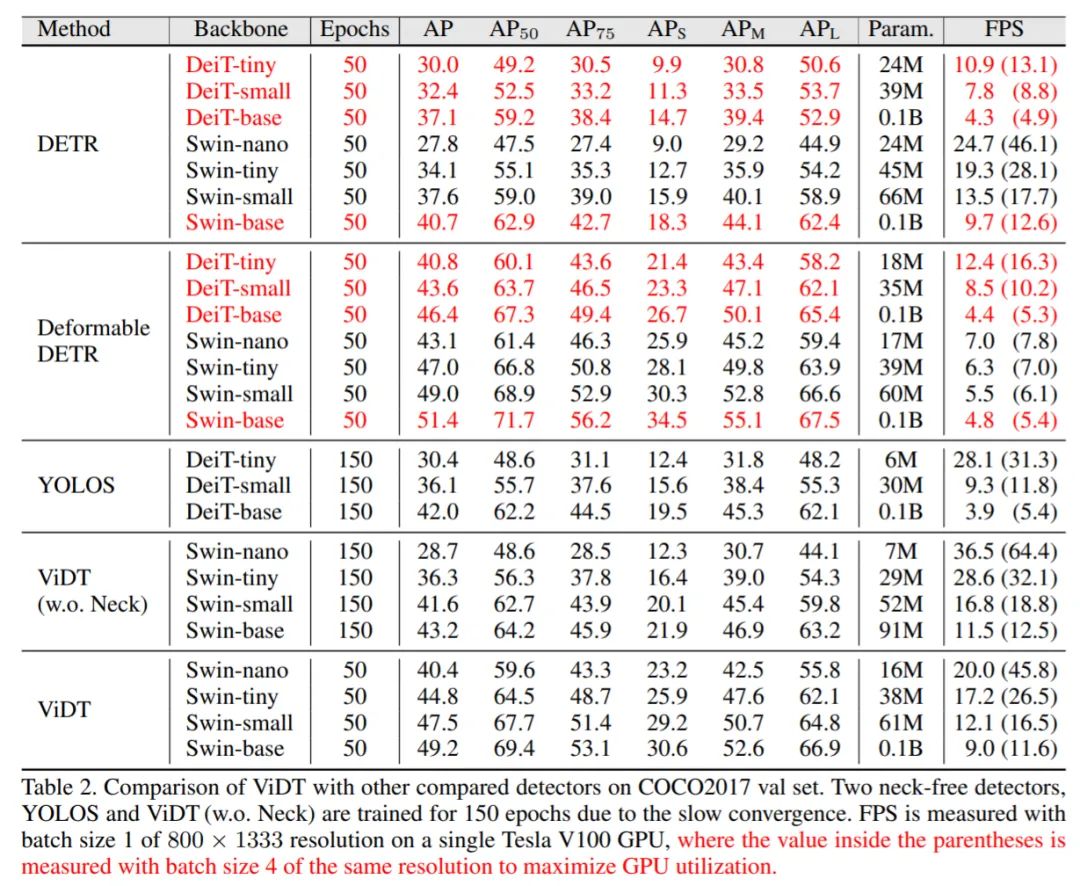
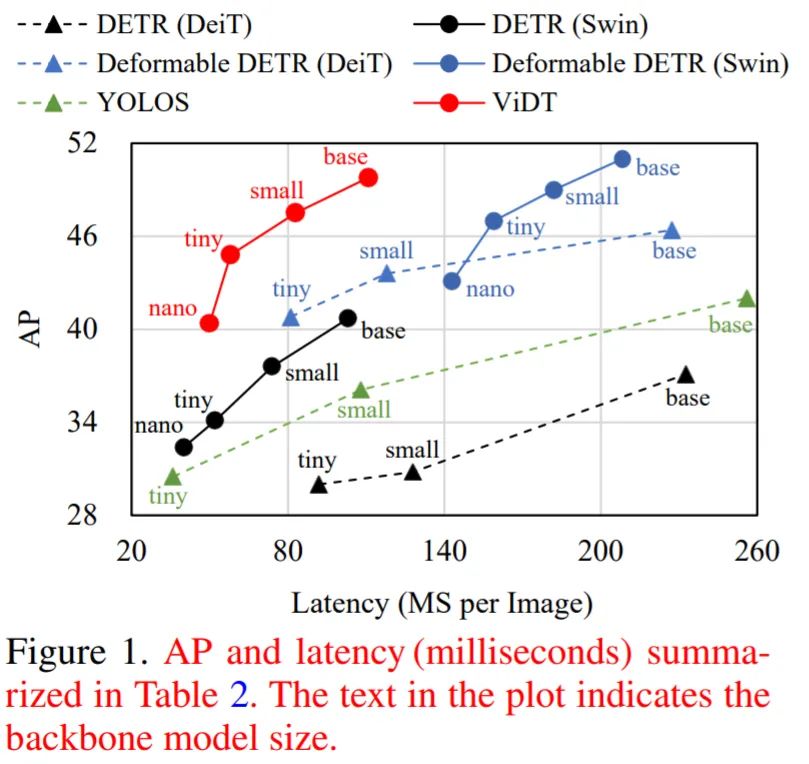
表 3 对比了不同空间位置编码与 ViDT(w.o. Neck)的结果。结果表明:pre-addition 比 post-addition 带来的性能提升更高,即 sinusoidal encoding 优于 learnable 编码;因此,正弦空间编码的 2D 归纳偏置在目标检测中更有帮助。特别是,与不使用任何编码相比,使用正弦编码的预加法(pre-addition)将 AP 增加了 5.0。
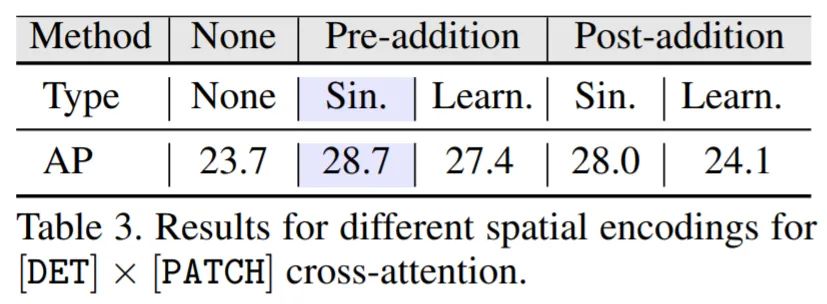
表 4 总结了使用不同选择策略进行交叉注意力(cross-attention)时的 AP 和 FPS,其中 Swin Transformer 总共包含四个阶段。有趣的是,只要在最后阶段激活交叉注意力,所有策略都表现出相似的 AP。由于在各个阶段中以自下而上的方式提取特征,因此在低级别阶段很难直接获得有关目标对象的有用信息。因此,研究者想要获得较高的 AP 和 FPS,只使用最后阶段是最好的设计选择,因为 [PATCH] token 的数量最少。

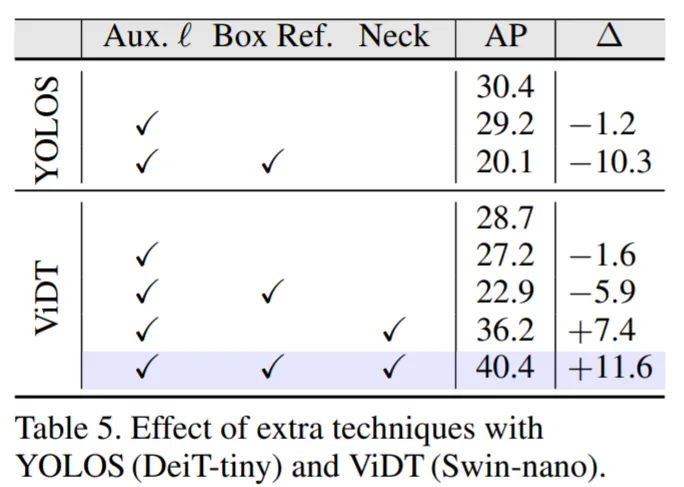
为了彻底验证辅助解码损失(auxiliary decoding loss)和迭代框细化(iterative box refinement)的有效性,该研究甚至对 YOLOS 等 neck-free 检测器进行了扩展。表 5 显示了两种 neck-free 检测器 YOLOS 和 ViDT (w.o. Neck) 性能。实验结果证明在 ViDT 中使用 Neck 解码器来提高目标检测性能是合理的。
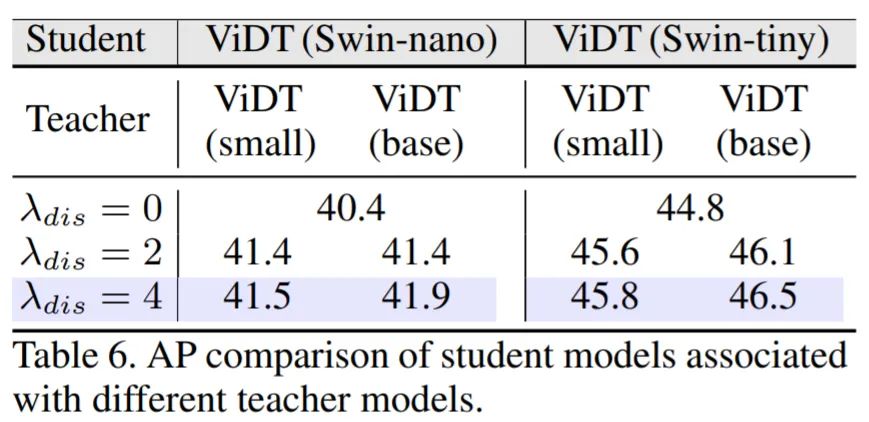
下图表明:教师模型的规模越大,学生模型的收益越大。从系数来看,系数值越大,性能越好。模型蒸馏将 AP 提高了 1.0-1.7,而不会影响学生模型的推理速度。
研究者将所有提议的组件结合起来,以实现目标检测的高精度和速度。如表 8 所示,有四个组件:(1) RAM 将 Swin Transformer 扩展为独立的目标检测器,(2) neck 解码器利用多尺度特征和两种辅助技术,(3) 从大模型中获益知识蒸馏,(4) 解码层 drop 进一步加快推理速度。结果表明:当使用 Swin-nano 作为其主干时,它仅使用 13M 参数就达到了 41.7AP 和合理的 FPS。此外,当使用 Swin-tiny 时,它仅损失了 2.7 FPS 而表现出 46.4AP。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“数据集”获取30+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



