一个既能做CV任务,也能做NLP任务的Transformer模型!谷歌&UCLA提出统一的基础模型

极市导读
在本文中,作者探讨了建立一个统一的基础模型的可能性,可以适应视觉和纯文本的任务。基于BERT和ViT,作者设计了一个统一的Transformer,由特定模态tokenizer、共享Transformer编码器和特定任务输出head组成。>>加入极市CV技术交流群,走在计算机视觉的最前沿
本文分享论文 『Towards a Unified Foundation Model: Jointly Pre-Training Transformers on Unpaired Images and Text』 ,由谷歌 & UCLA 联合提出统一的基础模型,是一个既能做 CV 任务,也能做 NLP 任务的 Transformer 模型!
详细信息如下:

-
论文链接:https://arxiv.org/abs/2112.07074
-
项目链接:未开源
01 Motivation
近年来,不同领域的深度学习模型,特别是计算机视觉和自然语言处理,在模型结构和学习方法方面已逐渐趋同于非常相似的范式:以预训练-微调的方式学习的Transformer,这被称为基础模型。
在NLP社区,以前的作品表明,在大型文本语料库上预训练的Transformer,在广泛的下游文本任务上进行微调时,可实现SOTA的性能。
在视觉领域,基于Transformer的模型最近在图像分类、目标检测和全景分割等任务上取得了令人满意的结果。
这些Transformer通常在大型图像数据集上进行预训练,然后根据特定任务进行微调。然而,尽管Transformer在各个领域取得了成就,但仍然需要为每个领域维护一个大型基础模型。这限制了此类模型的影响,并与长期追求的通用智能目标背道而驰,后者旨在以有效的方式同时处理多种模态。
在见证了深度学习到基于Transformer的基础模型的范式转换之后,各种各样的问题自然而然地出现了:我们可以建立一个统一的Transformer来解决不同模态的任务吗?如果没有,是否可以对单个Transformer进行预训练,然后对其进行微调以适应不同模态的任务?
在本文中,作者通过探索为视觉和文本模态构建单个预训练的Transformer的方法来回答上面的问题,该Transformer可以进一步微调以适应不同的下游任务。从BERT 和ViT开始,作者提出了一个统一的基础Transformer,名为 “ViT-BERT”,由三个模块组成:
-
模态特定tokenizer:每个模态都有自己的tokenizer来处理特殊形式的输入;
-
共享Transformer编码器: 所有模态和任务共享一个Transformer作为模型的主体;
-
任务特定head: 每个任务都有一个轻量级的分类器来预测特定任务的输出。
设计理念是在共享Transformer编码器中具有最小的模态特性和任务特性参数,以及尽可能多的参数和计算。因此,作者对模态特有的tokenizer采用单层patch投影和嵌入,对每个任务特定的head采用两层MLP。作者在未匹配的图像和文本上预训练提出的统一Transformer。然后,该模型作为一个统一的基础模型,它可以很好地拓展到只有视觉和文本的任务。
为了预训练统一的基础Transformer,作者提出了两种技术。首先,为了为联合预训练提供丰富,准确的监督信号,作者利用单独训练的BERT和ViT作为教师模型,并应用知识蒸馏来训练所提出的模型。其次,为了调和来自不同任务的潜在的影响梯度,作者设计了一种新颖的梯度掩蔽策略,以平衡来自文本和图像预训练任务的学习信号。具体地说,作者创建了一个掩码,根据文本梯度的大小为文本预训练选择最重要的一组参数,其余的参数由图像预训练进行更新。所提出的梯度掩蔽策略在训练过程中逐渐应用,直到达到所需的掩蔽稀疏度。
作者通过对仅视觉和仅文本任务进行微调来评估联合预训练的ViT-BERT模型的表示能力。更具体地说,作者在图像分类任务(如CIFAR-10/100和ImageNet)上对模型进行了微调,以测试它在多大程度上可以转换为以图像作为输入的视觉任务。作者还根据GLUE基准对其进行了微调,以测试其对自然语言理解的能力。
实验结果表明,与单独训练的BERT和ViT相比,图像和文本的联合预训练效果出人意料地好,不会导致下游任务的显著性能下降。所提出的知识精馏和梯度掩蔽策略可以进一步提高性能以接近单独训练模型的水平,验证了它们在预训练统一基础Transformer上的有效性。
02 方法
2.1. Unified Transformer
2.1.1 Modality-specific Tokenizer
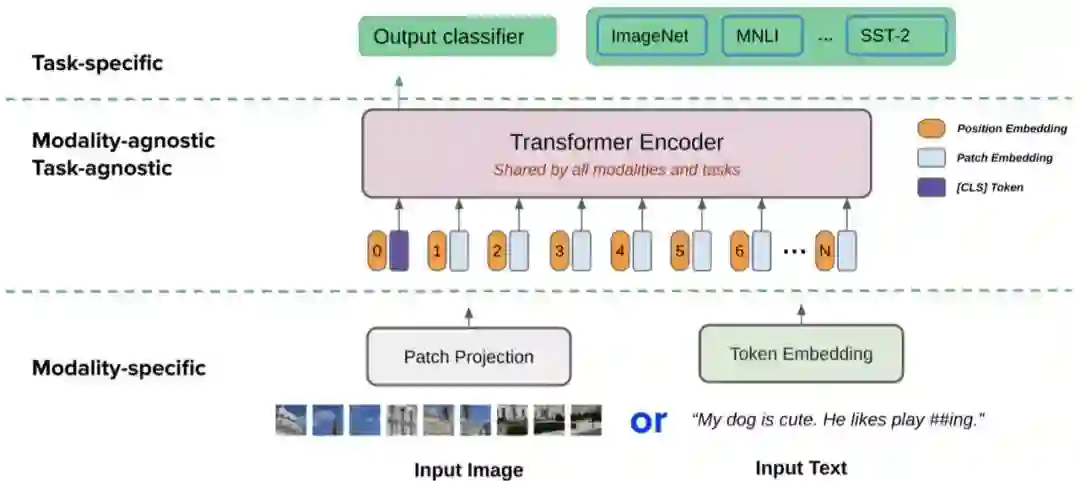
作者考虑两种输入方式:图像或文本。注意,这里不使用图像-文本对进行预训练,所以下面的公式不考虑成对的图像和文本作为输入。
只有视觉的任务需要感知图像作为输入。受视觉Transformer (ViT) 的启发, 作者首先将图像 切片为一系列patch , 其中 是patch分辨率, 是产生的patch数。然后, 每个patch都经过flatten, 并由线性投影 进行embed, 最 后, 添加类token , 并添加了位置嵌入 。从形式上讲, 图像被处理成一系列patch嵌 入, 如下所示:
在纯文本任务中,输入文本以与BERT中相同的方式被tokenize为如下token序列:
其中 是单词嵌入矩阵, 是文本的位置嵌入, 是段嵌入。作者没有为模态类型添加任何额外的 嵌入, 因为它不会给实验带来任何改进。
2.1.2 Shared Transformer Encoder
Transformer编码器由包括多头自注意力(MSA)层和MLP层的堆叠块组成。
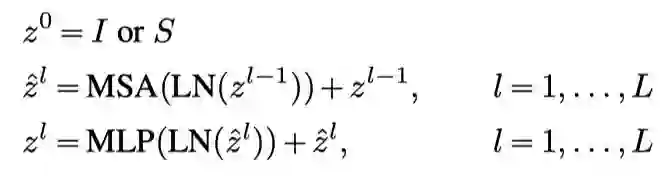
Transformer编码器的最终输出是在最后一层token嵌入,用作不同任务head的输入。
2.1.3 Task-specific Heads
特定于任务的预测头应用于Transformer编码器的最终输出。在这项工作中解决的所有任务,包括预训练任务和下游任务,都可以转化为分类问题。为了预测输出类,作者采用了一个具有GELU激活的两层MLP 分类器,其hidden size等于Transformer编码器的hidden size:
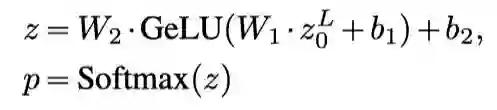
其中,是第一层的权重和偏差,是第二层的权重和偏差,p是输出类的预测概率分布。注意,在大多数任务中,是class token在Transformer的最后一层的嵌入,除了masked language modelling,在masked language modelling中,它是masked token在最后一层的嵌入。
2.2. Joint Pre-Training
本节将讨论所提出的模型在图像和文本上的联合预训练。联合预训练属于多任务学习的范畴,长期以来,由于诸如冲突梯度或灾难性遗忘等优化问题,人们一直认为多任务学习非常具有挑战性。联合训练神经网络以同时执行多个任务通常需要对各个任务进行仔细的校准,以确保没有一个任务特定的损失占主导地位。这些问题在本文的情况下更加严重,因为预训练非常嘈杂,通常需要数百万个优化步骤才能收敛,特别是对于文本的预训练。
作者从两个角度来解决上述问题:
-
利用知识蒸馏为联合训练提供额外准确的监督;
-
设计了一种梯度掩蔽策略,以适应来自不同任务的潜在冲突梯度。
2.2.1 Knowledge Distillation
本节中将讨论如何使用知识蒸馏来改进文本和图像的联合预训练。假设我们可以访问原始的BERT和ViT模型,它们分别在文本或图像模式上进行预训练,作为提出的统一模型的两个教师模型。这里要解决的问题是如何利用这两位教师进行训练。
知识蒸馏最大程度地减少了教师模型和学生模型的概率分布之间的Kullback-Leibler (KL) 差异。设为教师模型的预测logits,为学生模型的预测logits,y为ground-truth标签。蒸馏的目标是:
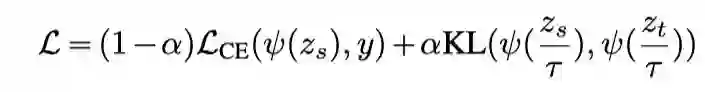
其中 ψ 表示softmax函数,α 是平衡ground-truth label的交叉熵损失 () 和KL散度的比率,τ 是蒸馏中使用的温度超参数。
因为同时在文本和图像上训练学生模型,所以每个训练batch都包括文本和图像。因此训练过程包含图像任务的损失和文本任务的损失。可以简单地相加这两个损失,并计算组合梯度来更新模型。
2.2.2 Gradient Masking
但是由于这两个损失函数针对不同的方式和目标进行了优化,因此它们可以为联合训练产生一致的梯度。简单地将两个损失相加,即完全忽略梯度冲突,可能会减慢训练过程,并使模型优化处于次优状态。
因此,作者从神经网络剪枝文献中获得灵感,探索适应冲突梯度的新方法,而不是直接相加这两种损失。通常认为,当前的大型神经网络是高度过度参数化的,并且用于从神经网络中消除不必要的权重 (即,剪枝) 的技术已经显示出能够通过甚至90% 减少训练网络的参数计数而不损害准确性。
受神经网络剪枝结果的启发,作者提出了一种新的梯度掩蔽策略,以协调来自文本预训练和图像预训练的潜在冲突梯度。主要思想是,保留文本预训练的最重要梯度的子集,而忽略其他梯度,为图像预训练留出空间。设 θ 为共享Transformer编码器中的参数,分别为文本预训练任务和图像预训练任务的损失。作者通过一种自适应的掩码M将文本和图像预训练任务中的梯度结合起来:
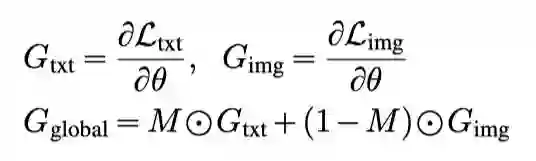
直观地说,掩码M应该为文本预训练选择最重要的梯度,并将其余梯度留给图像预训练,因此基于的大小启发式地生成掩码M。受网络修剪文献中使用的迭代幅度修剪算法的启发,作者设计了一个迭代梯度掩蔽程序,以逐渐增加掩蔽的稀疏性,算法如下图所示。

迭代梯度掩蔽程序带来的额外计算成本可以忽略不计,因为在整个训练过程中,掩蔽M仅更新几次,例如,如果最终掩蔽率(β)设置为50%,每次迭代掩蔽率(δ)设置为10%,则掩蔽只会更新5次。因此,梯度掩蔽策略不会减慢训练过程。
03 实验
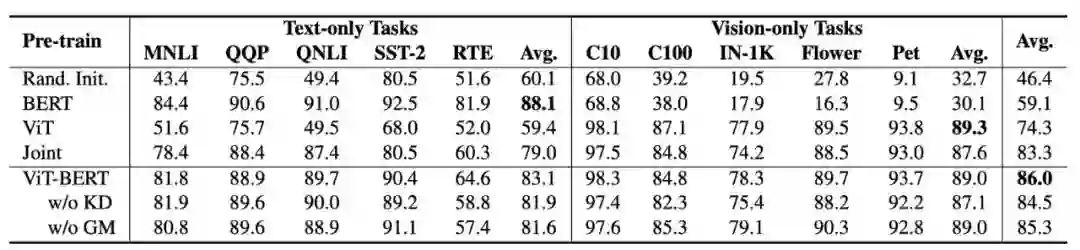
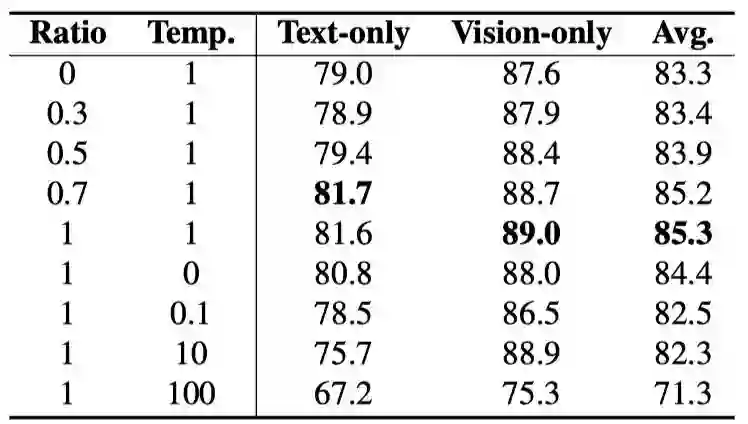
上表展示了不同distillation ratio和temperature的实验结果。
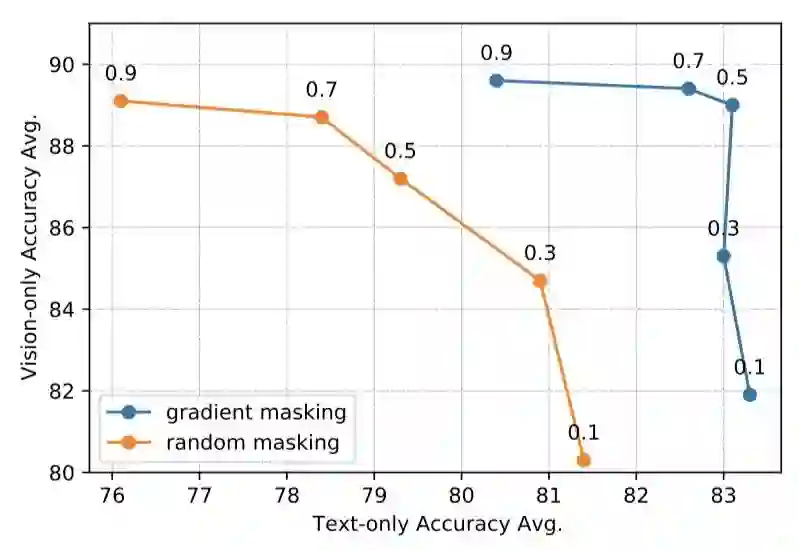
上图展示了不同mask ratio的实验结果。
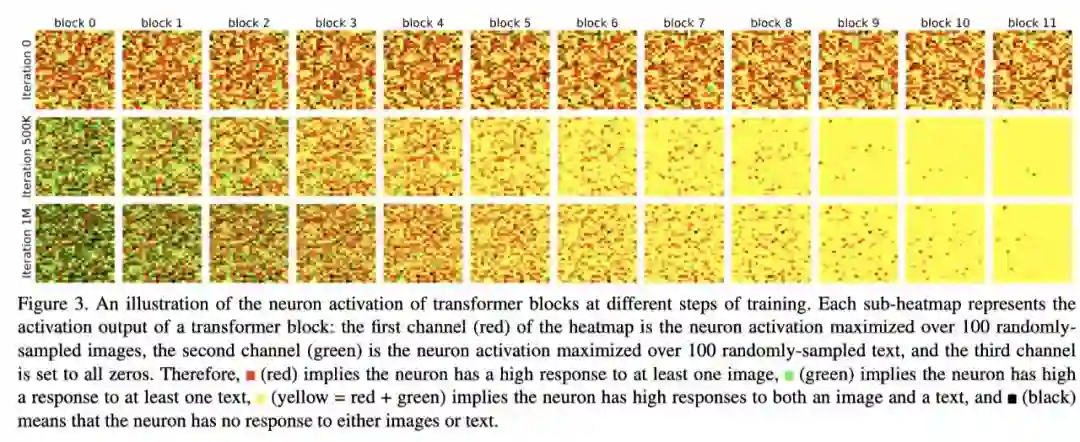
上图展示了在训练的不同步骤中,Transformer块的神经元激活值图示。
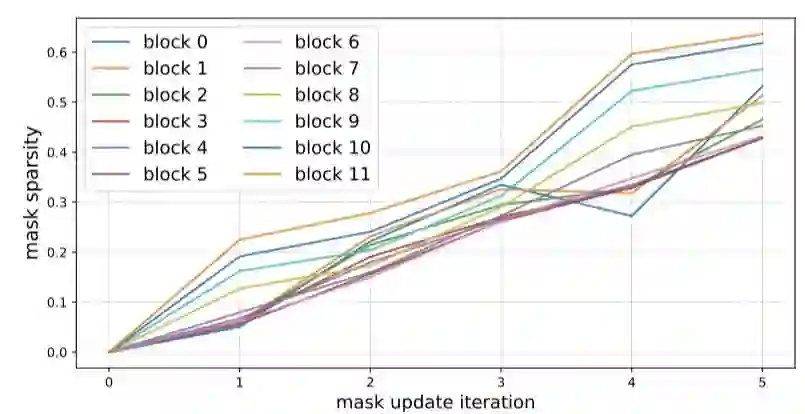
上图展示了在掩码更新的不同迭代时,Transformer编码器中所有块的掩码的稀疏性。

上图展示了在不同的mask更新迭代中,Transformer编码器块0、6和11的梯度mask的可视化。
04 总结
这篇文章提出怎么去联合训练一个同时能够处理text-only和image-only的Transformer模型,为了模型的训练的稳定,作者在本文中提出了两个比较有用的技巧,第一个是使用已经训练好的单模态模型(BERT和ViT)作为教师模型,在训练过程中,模型需要拟合教师模型的输出结果;第二个是不同的模态更新不同的参数,从而使得训练更加有效,防止多模态和大量数据导致的模型拟合困难。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



