ICLR 2022 | 首次实现用MLP做检测和分割!上科大和腾讯开源AS-MLP:一种轴向位移的MLP框架

极市导读
本文提出一种轴向位移的MLP框架,首次实现用MLP做检测分割。本文将更多的注意力放在局部的特征提取上,进一步提升了MLP-based框架的性能,实验结果也是令人印象深刻的。代码也是十分简洁,在ImageNet-1K数据集上以88M的参数和15.2 GFLOPs能达到83.3%的准确率。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

AS-MLP: An Axial Shifted MLP Architecture for Vision
单位:上海科技大学,腾讯优图
Paper: https://arxiv.org/abs/2107.08391
Code: https://github.com/svip-lab/AS-MLP
一、研究动机
在过去的十年中,卷积神经网络 (CNN) 已经受到了广泛的关注,并已成为计算机视觉中框架搭建的标准。随着对 self-attention 的深入探索和研究,基于 Transformer 的架构也逐渐出现。最近,基于 MLP 的网络框架被提出,其中几乎所有的网络参数都是从 MLP(线性层)中学习的,并取得了惊人的结果,可与类 CNN 模型相媲美。
这些惊人的结果推动了我们对基于 MLP 的架构的探索。在 MLP-Mixer中,该模型通过矩阵转置和 token-mixing 投影获得全局感受野,从而抓取了长距离依赖关系。然而,这很少充分利用局部信息,这在CNN 架构中是非常重要,因为并非所有像素都需要长距离依赖,而局部信息更侧重于提取低层特征。在基于Transformer的架构中,一些论文已经强调了局部感受野的优势,并在Transformer中引入了局部信息,如Localvit、NesT等。在这些想法的驱动下,我们主要探索局部性对基于 MLP 的架构的影响。
为了在基于 MLP 的架构中引入局部性,一个最简单、最直观的想法是在 MLP-Mixer 中添加一个窗口,然后对窗口内的特征进行局部信息的 token-mixing 投影,就像在 Swin Transformer 中所做的一样。然而,对于基于 MLP 的架构,如果我们划分窗口 (例如,7 x 7) 并在窗口中执行 token-mixing 投影,如果共享线性层,那么将只有 49 x 49 的参数,这极大地限制了模型容量,从而影响参数的学习和最终结果。如果不共享线性层,由于固定的 MLP 维度,模型将无法应用于下游任务。因此,我们为基于 MLP 的架构提出了一种轴向位移策略,我们在水平和垂直方向上空间移动特征。轴向位移可以将不同空间位置的特征排列在相同的位置。之后,使用 MLP 来组合这些功能,简单而有效。 这种方法使模型能够获得更多的局部依赖,从而提高性能。它还使我们能够像卷积核一样设计 MLP 结构,例如设计核大小和膨胀率。
基于轴向位移策略,我们设计了轴向位移的 MLP 架构,命名为 AS-MLP。我们的 AS-MLP 在 ImageNet-1K 数据集中使用 88M 参数和 15.2 GFLOP 获得 83.3% Top-1 准确率,无需任何额外的训练数据。与基于Transformer的架构相比,这种简单而有效的方法优于所有基于 MLP 的架构,并实现了具有竞争力的性能。AS-MLP 架构也可以转移到下游任务,例如目标检测。据我们所知,这也是第一个将基于 MLP 的架构应用于下游任务的工作。使用 ImageNet-1K 数据集中的预训练模型,AS-MLP 在 COCO 验证集上获得 51.5 mAP,在 ADE20K 数据集上获得 49.5 MS mIoU,与基于Transformer的架构相比具有竞争力。
二、具体的网络结构
总体的网络结构如图一所示,AS-MLP一共有四个stage,对于图像分类任务,输入分辨率为224,在经过不同的stage时分辨率逐渐降低,最终的输出将使用交叉熵损失做图像分类。
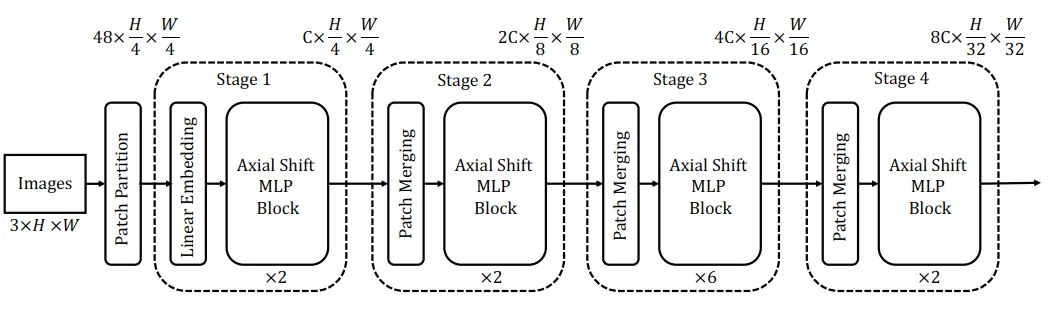
图二显示了在每个stage中AS-MLP block的结构以及轴向位移的过程。经过channel projection之后特征被分别使用vertical shift和horizontal shift来提取特征,得到的结果进行相加。在水平位移的过程中,来自不同位置的特征将被重新组合,之后通过MLP。
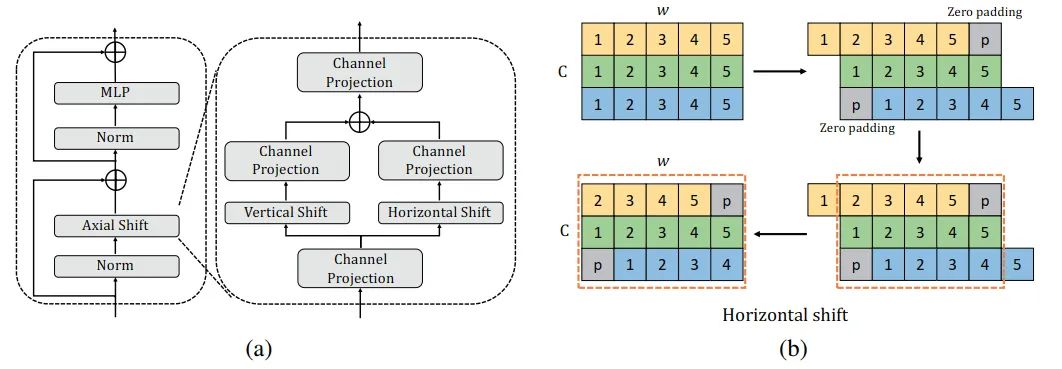
我们也对不同操作的感受野进行了分析,图三显示了神经网络中不同操作的感受野。在AS-MLP中,我们能使用不同的shift size和dilation rate,因此使得网络具有不同的感受野。例如,图四中的第六张图显示了当shift size为3,dilation rate为2时候的感受野大小。
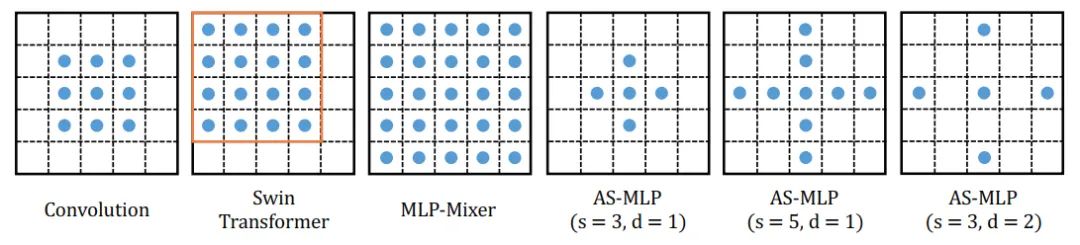
图四显示了AS-MLP框架的各种变种。不同的框架配置具有不同的参数量和计算量,用于与其他方法进行公平的结果比较。

三、实验结果
(一)在ImageNet-1K数据集上的图像分类性能
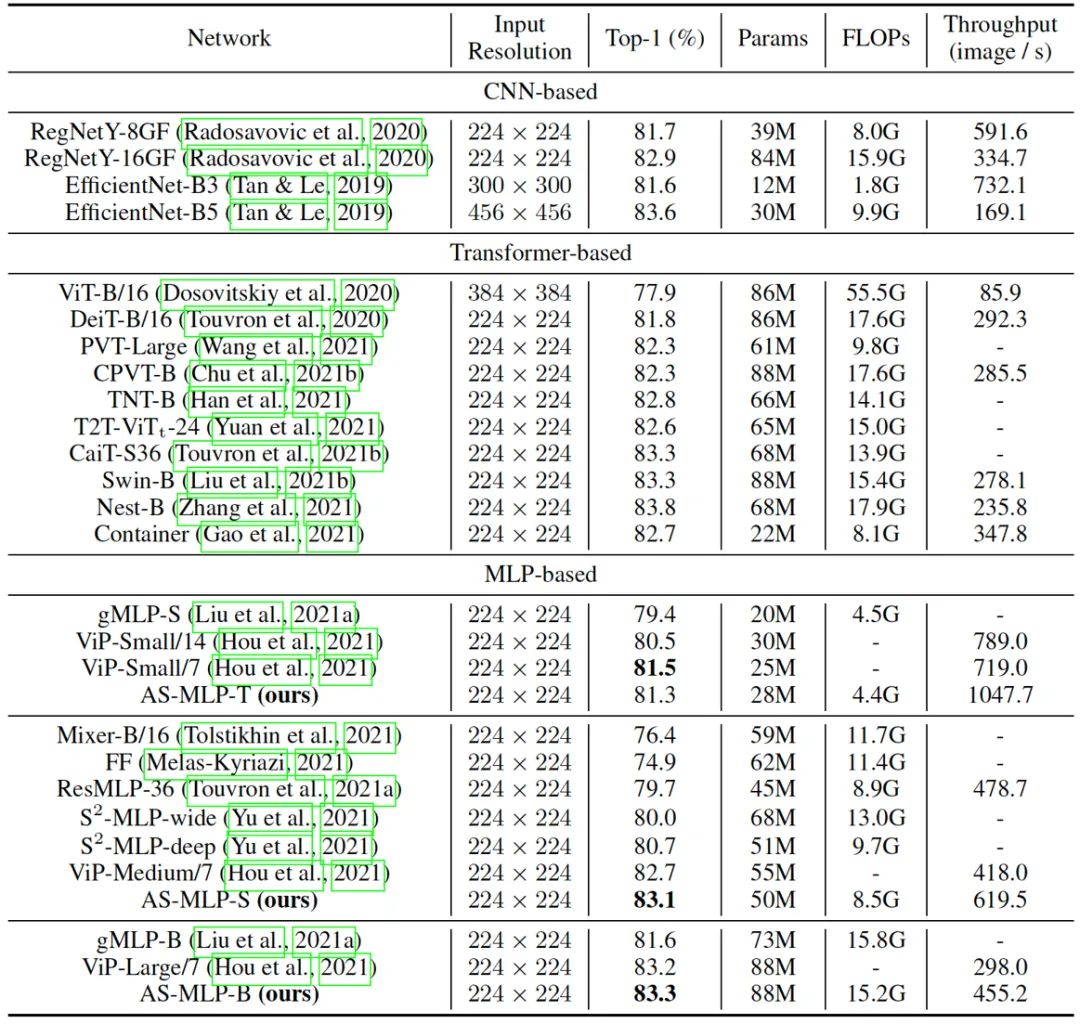
表一显示了所有网络在图像分类任务上的结果。我们将所有网络架构分为基于 CNN、基于 Transformer 和基于 MLP 的架构。输入分辨率为 224 x 224。当保持相似的参数量和计算量时,我们提出的 AS-MLP 优于其他基于 MLP 的架构。例如,AS-MLP-S 获得了83.1%的准确度,这优于 Mixer-B/16 (76.4%) 和 ViP-Medium/7 (82.7\%)。此外,与基于Transformer的网络框架相比,它获得了具有竞争力的性能。例如 AS-MLP-B 获得了83.3%的准确度,这与Swin-B的性能相当,显示了我们的 AS-MLP 框架的有效性。
(二)在COCO数据集上的目标检测性能
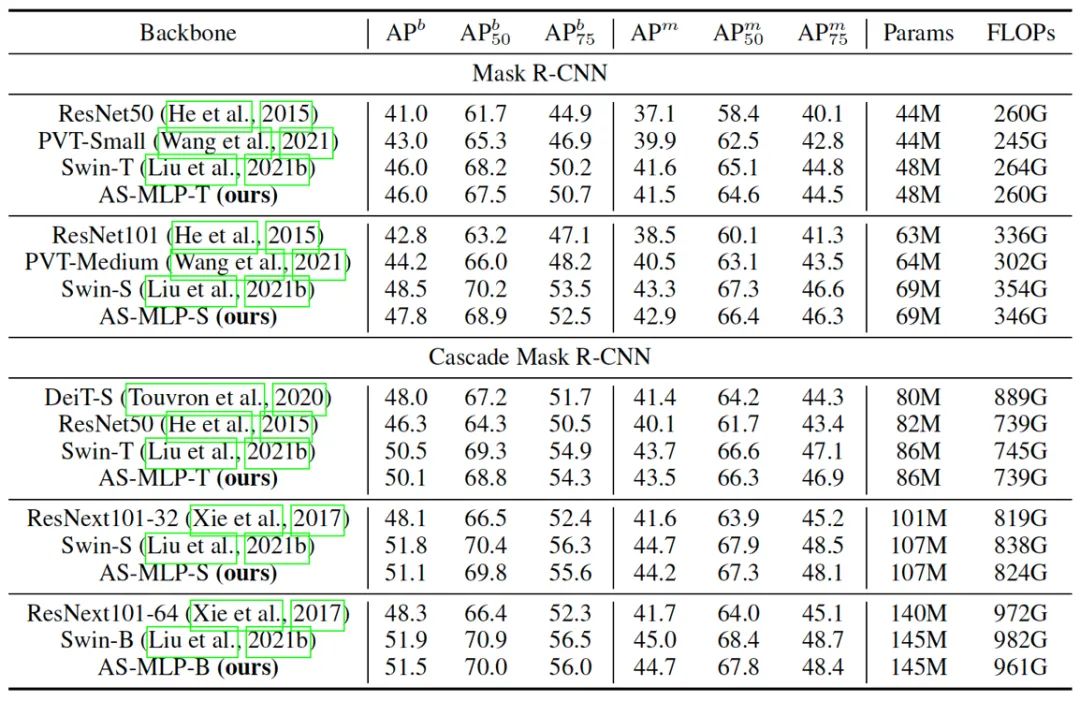
目标检测和实例分割的结果见表二,值得注意的是,我们没有将我们的方法与 MLP-Mixer 进行比较,因为它使用固定的空间维度进行 MLP操作,目标检测的输入尺寸不是固定的,因此不能迁移到目标检测中。据我们所知,我们是第一个将基于 MLP 的架构应用于目标检测的工作。我们的 AS-MLP 在类似的资源限制下实现了与 Swin Transformer 相当的性能。具体来说,Cascade Mask R-CNN + Swin-B在145M参数下达到51.9 ,Cascade Mask R-CNN + AS-MLP-B在145M参数下获得51.5 。图五也显示了目标检测和实例分割的结果。

(三)在ADE20K数据集上的语义分割性能
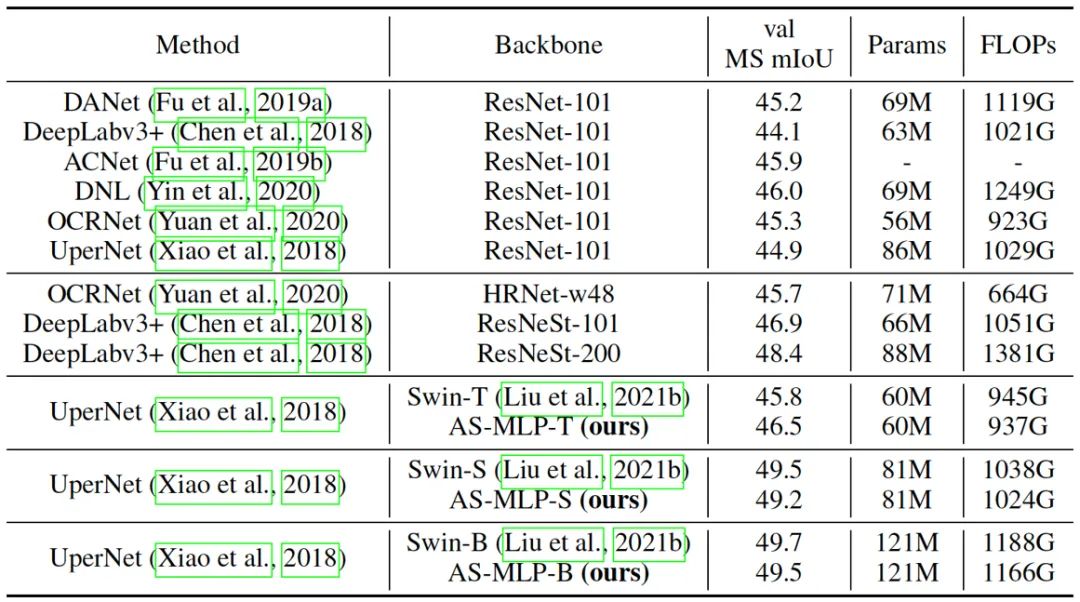
表三显示了我们的 AS-MLP 在 ADE20K 数据集上的性能。请注意,我们也是第一个将基于 MLP 框架应用于语义分割的工作。在更少的计算量的情况下,AS-MLP-T 取得了比 Swin-T 更好的结果(46.5 vs. 45.8 MS mIoU)。对于大型模型,UperNet + Swin-B 有着 49.7 MS mIoU,121M 参数和 1188 GFLOPs,UperNet + AS-MLP-B 有 49.5 MS mIoU,121M 参数和 1166 GFLOPs,这也显示了我们 的AS-MLP在处理下游任务时的有效性。图六也显示了我们的方法在ADE20K数据集上的语义分割的结果。

四、结论
本文提出一种轴向位移的MLP框架,首次实现用MLP做检测分割。本文将更多的注意力放在局部的特征提取上,进一步提升了MLP-based框架的性能,实验结果也是令人印象深刻的。代码也是十分简洁,在ImageNet-1K数据集上以88M的参数和15.2 GFLOPs能达到83.3%的准确率。
本文算是一个比较基本的baseline,在下游任务上的表现也仅仅和transformer相近,笔者认为在下游任务上仍然有很大的提升空间。
公众号后台回复“数据集”获取30+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~





