何恺明组新论文:只用ViT做主干也可以做好目标检测
转载机器之心报道
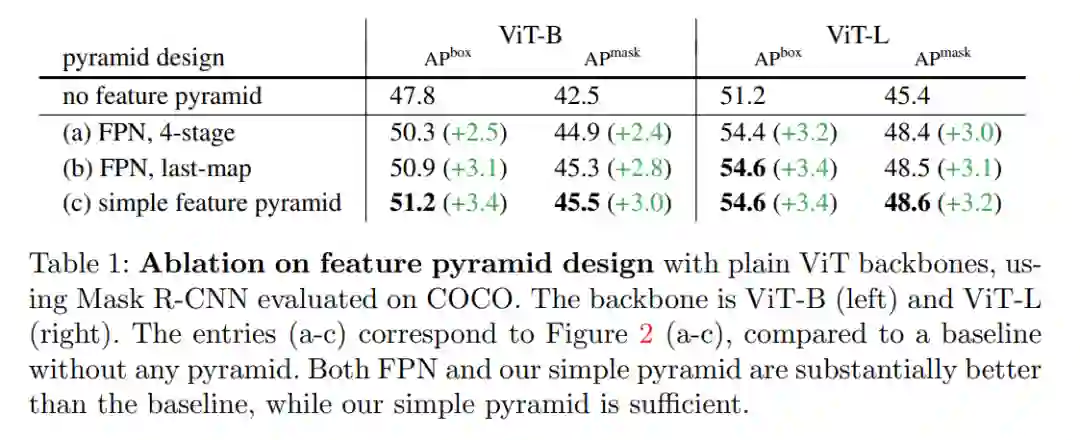
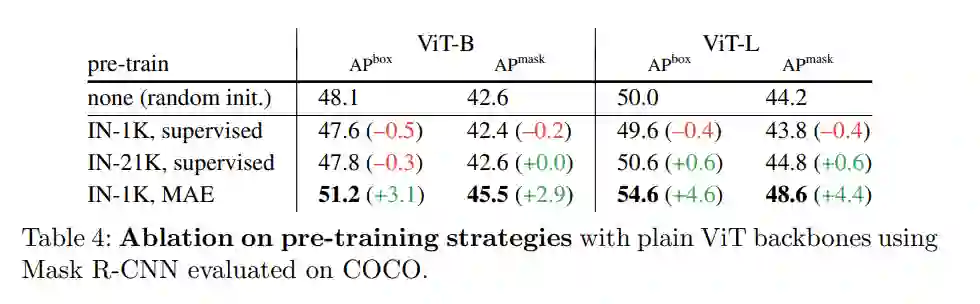
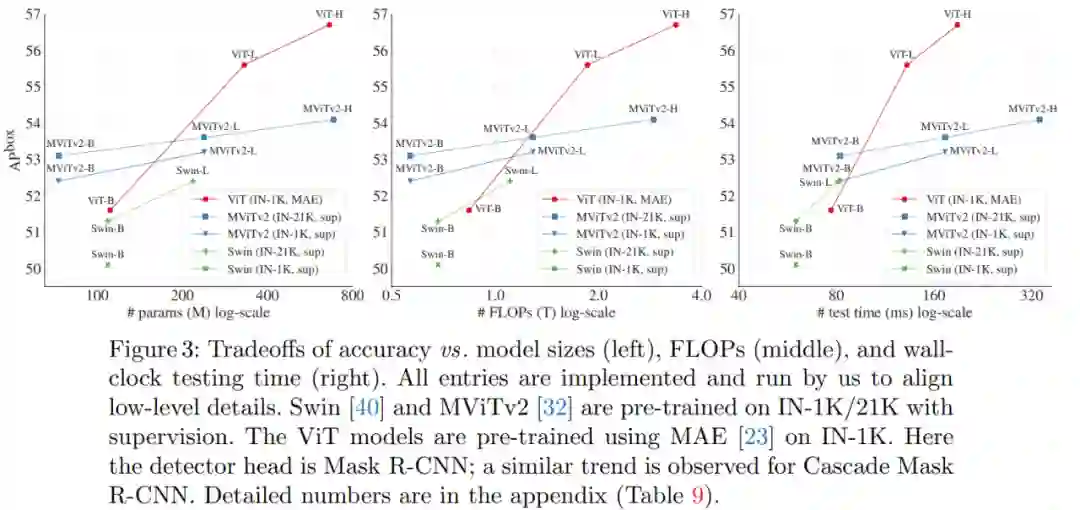
做目标检测就一定需要 FPN 吗?昨天,来自 Facebook AI Research 的 Yanghao Li、何恺明等研究者在 arXiv 上上传了一篇新论文,证明了将普通的、非分层的视觉 Transformer 作为主干网络进行目标检测的可行性。他们希望这项研究能够引起大家对普通主干检测器的关注。

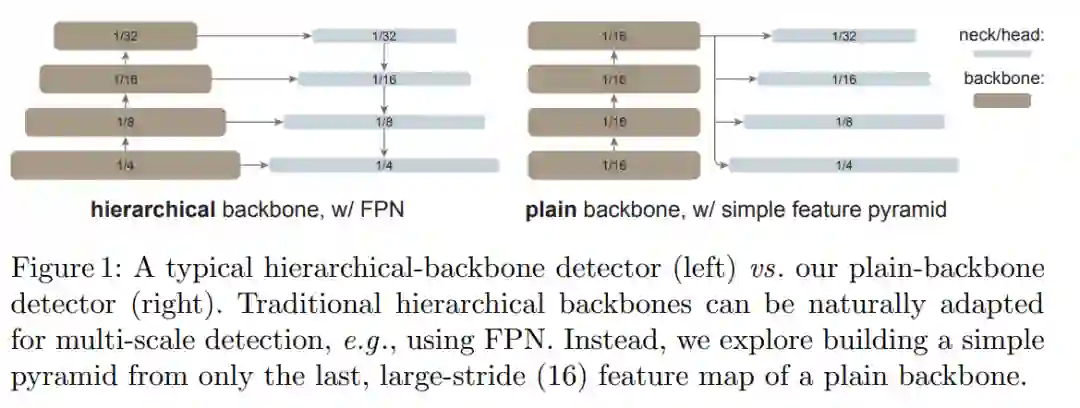
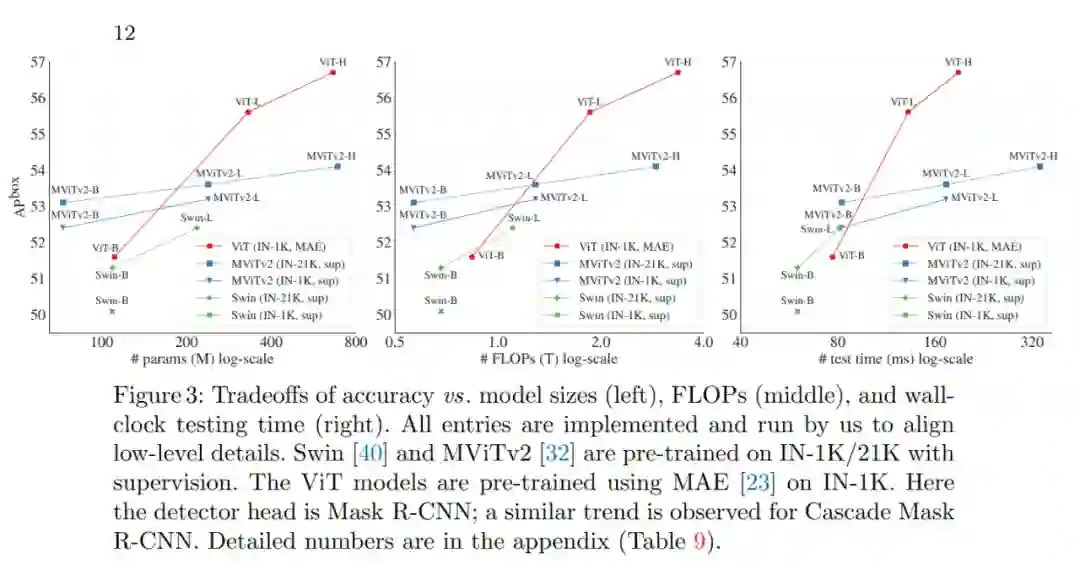
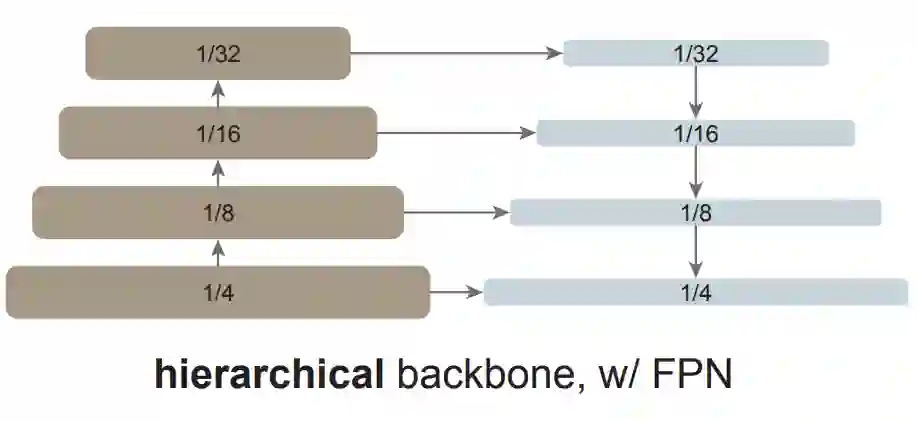

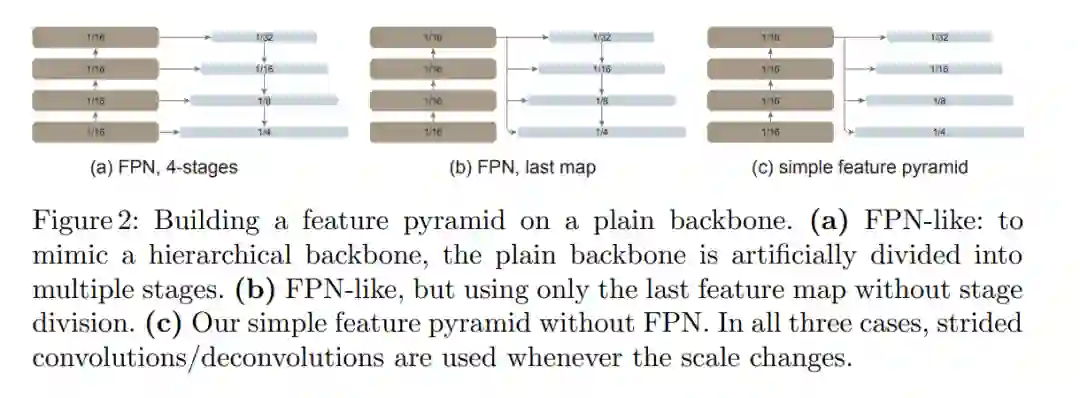
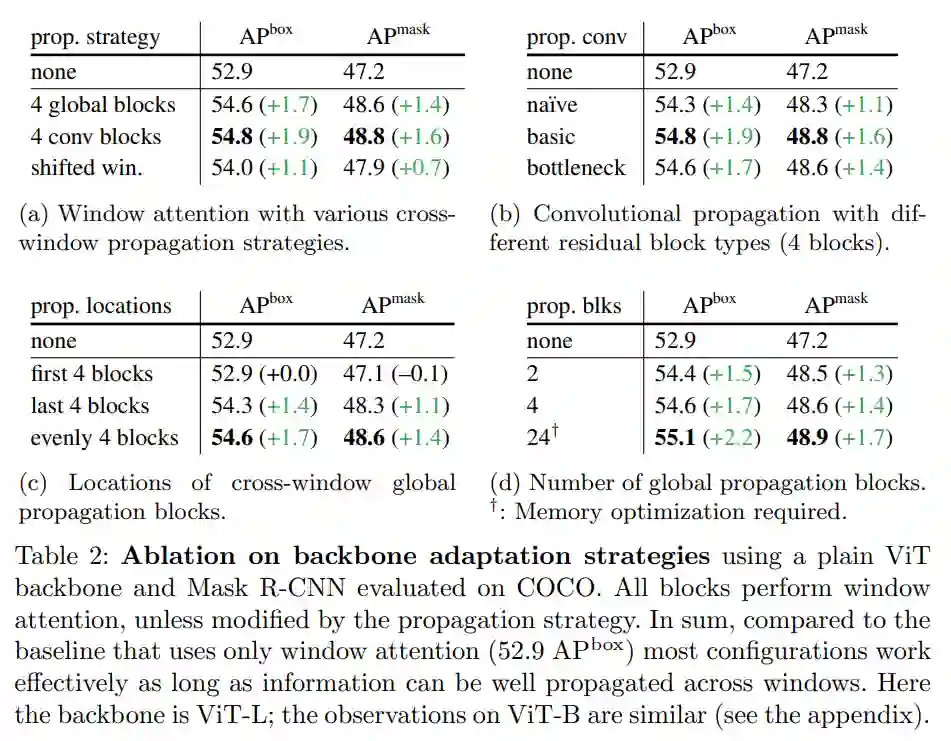
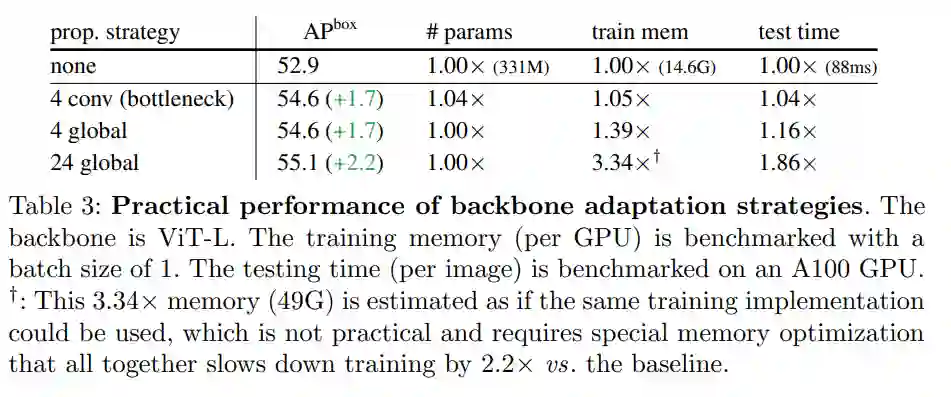
全局传播。该策略在每个子集的最后一个块中执行全局自注意力。由于全局块的数量很少,内存和计算成本是可行的。这类似于(Li et al., 2021 )中与 FPN 联合使用的混合窗口注意力。
卷积传播。该策略在每个子集之后添加一个额外的卷积块来作为替代。卷积块是一个残差块,由一个或多个卷积和一个 identity shortcut 组成。该块中的最后一层被初始化为零,因此该块的初始状态是一个 identity。将块初始化为 identity 使得该研究能够将其插入到预训练主干网络中的任何位置,而不会破坏主干网络的初始状态。


专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“EPVT” 就可以获取《Exploring Plain Vision Transformer Backbones for Object Detection》专知下载链接



登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文