FAIR何恺明团队最新研究:定义ViT检测迁移学习基线

极市导读
本文是FAIR的何恺明团队关于ViT在COCO检测任务上的迁移学习性能研究。它以Mask R-CNN作为基线框架,以ViT作为骨干网络,探索了不同初始化策略对于模型性能的影响。实验表明:masking机制的无监督学习机制(如MAE、BEiT)首次在COCO检测任务迁移学习中取得了令人信服的性能提升 。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2111.11429
本文是FAIR的何恺明团队关于ViT在COCO检测任务上的迁移学习性能研究。它以Mask R-CNN作为基线框架,以ViT作为骨干网络,探索了不同初始化策略对于模型性能的影响;与此同时,为尽可能保证对比的公平性,还对不同超参数进行了大量的实验;此外,为将ViT作为多尺度模式,参考XCiT对ViT不同部分的特征进行尺度调整以达成多尺度特征输出;为使得ViT模型能处理大分辨率图像,还对ViT的架构进行了改进,引入了全局与局部自注意力机制,进一步提升了模型性能取得了更佳的均衡。该文的一系列实验表明:masking机制的无监督学习机制(如MAE、BEiT)首次在COCO检测任务迁移学习中取得了令人信服的性能提升 。
Abstract
为测试预训练模型能否带来性能增益(准确率提升或者训练速度提升),目标检测是一个常用的且非常重要的下游任务。面对新的ViT模型时,目标检测的复杂性使得该基线变得尤为重要(non-trivial )。然而架构不一致、缓慢训练、高内存占用以及未知训练机制等困难阻碍了标准ViT在目标检测任务上的迁移学习。
本文提出了训练技术以克服上述挑战,并采用标准ViT作为Mask R-CNN的骨干。这些工具构成了本文的主要目标:我们比较了五种ViT初始化,包含SOTA自监督学习方法、监督初始化、强随机初始化基线。
结果表明:近期提出的Masking无监督学习方法首次提供令人信服的迁移学习性能改善 。相比监督与其他自监督预训练方法,它可以提升 指标高达4% ;此外masking初始化具有更好的扩展性,能够随模型尺寸提升进一步提升其性能。
Method
因其在目标检测与迁移学习领域的无处不在性,我们采用Mask R-CNN作为基线方案。该选择也旨在对简洁性与复杂性进行均衡,同时提供具有竞争力(也许并非SOTA)的结果。相比原始版本,我们为Mask R-CNN提供了不同的改进模块与训练方案。
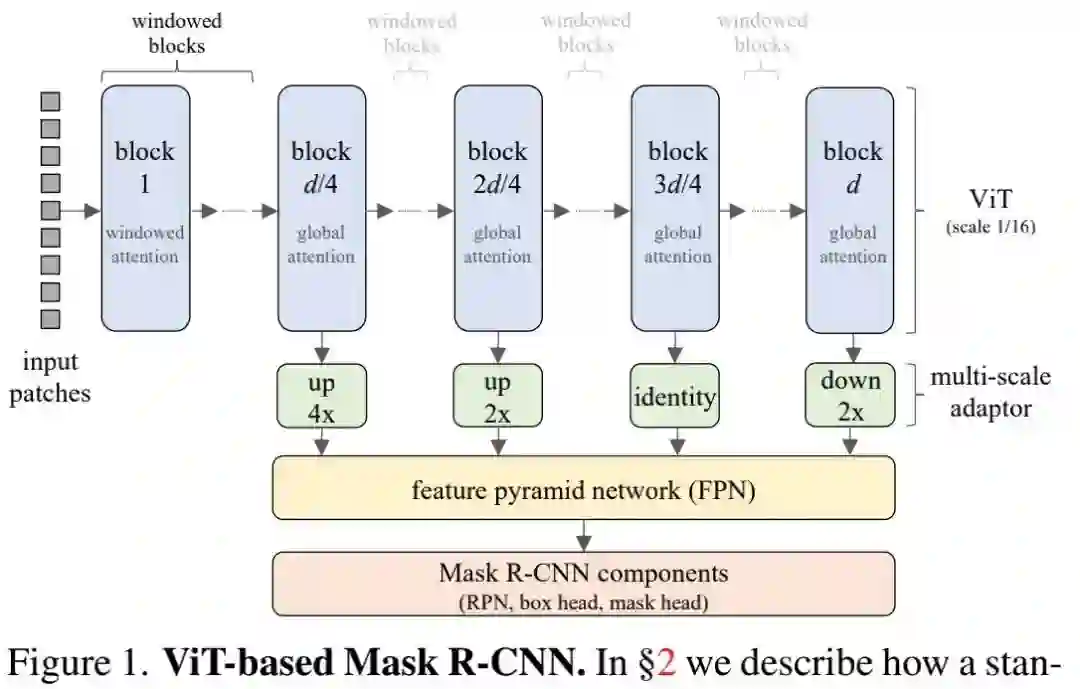
ViT Backbone
接下来,我们将解决如下两个ViT作为Mask R-CNN骨干的技术障碍
-
如何与FPN适配;
-
如何降低内存占用与推理耗时。
FPN Compatibility Mask R-CNN可以与输出单尺度特征的骨干,也可与输出多尺度特征(多尺度特征将被送入FPN处理)的骨干协同工作。由于FPN能够提供更好的检测结果,故我们采用了FPN方案。
然而,采用FPN存在这样一个问题:ViT仅输出单尺度特征,而非CNN的多尺度特征 。为解决该问题,我们采用了XCiT中的技术对ViT中间特征进行上/下采样以提供四种不同分辨率的特征(可参见上面图示绿框部分)。
第一个模块采用两个stride=2的 转置卷积进行4倍上采样;第二个模块采用一个stride=2的 转置卷积进行2倍上采样;第三个模块不做任何处理;最后一个模块采用stride=2的MaxPool进行下采样。
假设块尺寸为16,这些模块将输出stride分别为4、8、16、32的特征并被送入到FPN中。
注:Swin与MViT通过修改VIT架构解决了ViT无法输出多尺度特征的问题。这种处理方式也是一个重要的研究方向,但它与ViT的简单设计相悖,会阻碍新的无监督学习(如MAE)探索。因此,本文仅聚焦于上述生成多尺度特征的改动方式。
Reducing Memory and Time Complexity 采用ViT作为Mask R-CNN的骨干会导致内存与耗时挑战。ViT中的每个自注意力操作会占用 空间。
在预训练过程中,该复杂度是可控的( )。而在目标检测中,标准图像尺寸为 ,这就需要近21倍多的像素和图像块,这种高分辨率用于检测小目标。由于自注意力的复杂度,哪怕基线ViT-B也需要占用20-30G GPU显存(batch=1,FP16) 。
为降低空间与时间复杂度,我们采用Windowed Self-attention,即局部自注意力,而非全局自注意力。我们将 图像块拆分为非重叠 窗口并在每个窗口独立计算自注意力。这种处理方式可以大幅降低空间复杂度与时间复杂度,我们默认设置 。
Windowed Self-attention的一个缺陷在于:骨干不能跨窗口聚合信息。针对此,我们每 隔 模块添加一个全局自注意力模块 。
Upgraded Modules
相比原始Mask R-CNN,我们对其内置模块进行了如下改动:
-
FPN中的卷积后接BN;
-
RPN中采用两个卷积,而非一个卷积;
-
RoI分类与Box回归头采用四个卷积(带BN)并后接一个全连接,而非原始的两层MLP(无BN);
-
Mask头中的卷积后接BN
Training Formula
相比原始训练机制,我们采用了从头开始训练+更长训练周期的训练机制(如400epoch)。我们希望让超参尽可能的少,同时抵制采用额外的数据增广与正则技术。然而,我们发现:DropPath对于ViT骨干非常有效(性能提升达2 ),故我们采用了该技术。
总而言之,训练机制如下:
-
LSJ数据增广( 分辨率,尺度范围[0.1,2.0]);
-
AdamW+Cosine学习率衰减+linear warmup
-
DropPath正则技术;
-
batch=64,混合精度训练。
当采用预训练初始时,微调100epoch;当从头开始训练时,训练400epoch。
Hyperparameter Tuning Protocol
为使上述训练机制适用于同模型,我对学习率lr、权值wd衰减以及drop path rate三个超参进行微调,同时保持其他不变。我们采用ViT-B+MoCoV3进行了大量实验以估计合理的超参范围,基于所得估计我们构建了如下调节机制:
-
对每个初始化,我们固定dp=0.0,对lr与wd采用grid搜索,固定 搜索中心为 ,以此为中心搜索;
-
对于ViT-B,我们从 中选择dp(预训练参数时,训练50epoch;从头开始时,则训练100epoch),dp=0.1为最优选择;
-
对于ViT-L,我们采用了ViT-B的最后lr与wd,并发现dp=0.3是最佳选择。
注:在训练与推理过程中,图像将padding到 尺寸。
Initialization Methods
在骨干初始化方面,我们比较了以下五种:
-
Random:即所有参数均随机初始化,无预训练;
-
Supervised:即ViT骨干在ImageNet上通过监督方式预训练,分别为300和200epoch;
-
MoCoV3:即在ImageNet上采用无监督方式预训练ViT-B与ViT-L,300epoch;
-
BEiT:即采用BEiT方式对ViT-B与ViT-L预训练,800epoch;
-
MAE:即采用MAE对ViT-B与ViT-L预训练,1600eoch;
Nuisance Factors in Pre-training
尽管我们尽可能进行公平比较,但仍存一些“令人讨厌”的不公因子:
-
不同的预训练方法采用了不同的epoch;
-
BEiT采用可学习相对位置偏置,而非其他方法中的绝对位置嵌入;
-
BEiT在预训练过程中采用了layer scale,而其他方法没采用;
-
我们尝试对与训练数据标准化,而BEiT额外采用了dVAE。
Experiments&Analysis

上表比较了不同初始化方案的性能,从中可以看到:
-
无论何种初始化,采用ViT-B/L作为骨干的Mask R-CNN训练比较平滑,并无不稳定因素,也不需要额外的类似梯度裁剪的稳定技术 ;
-
相比监督训练,从头开始训练具有1.4指标提升(ViT-L)。也即是说:监督预训练并不一定比随机初始化更强;
-
MoCoV3具有与监督预训练相当的性能;
-
对于ViT-B,BEiT与MAE均优于随机初始化与监督预训练;
-
对于ViT-L,BEiT与MAE带来的性能提升进一步扩大,比监督预训练高达4.0.
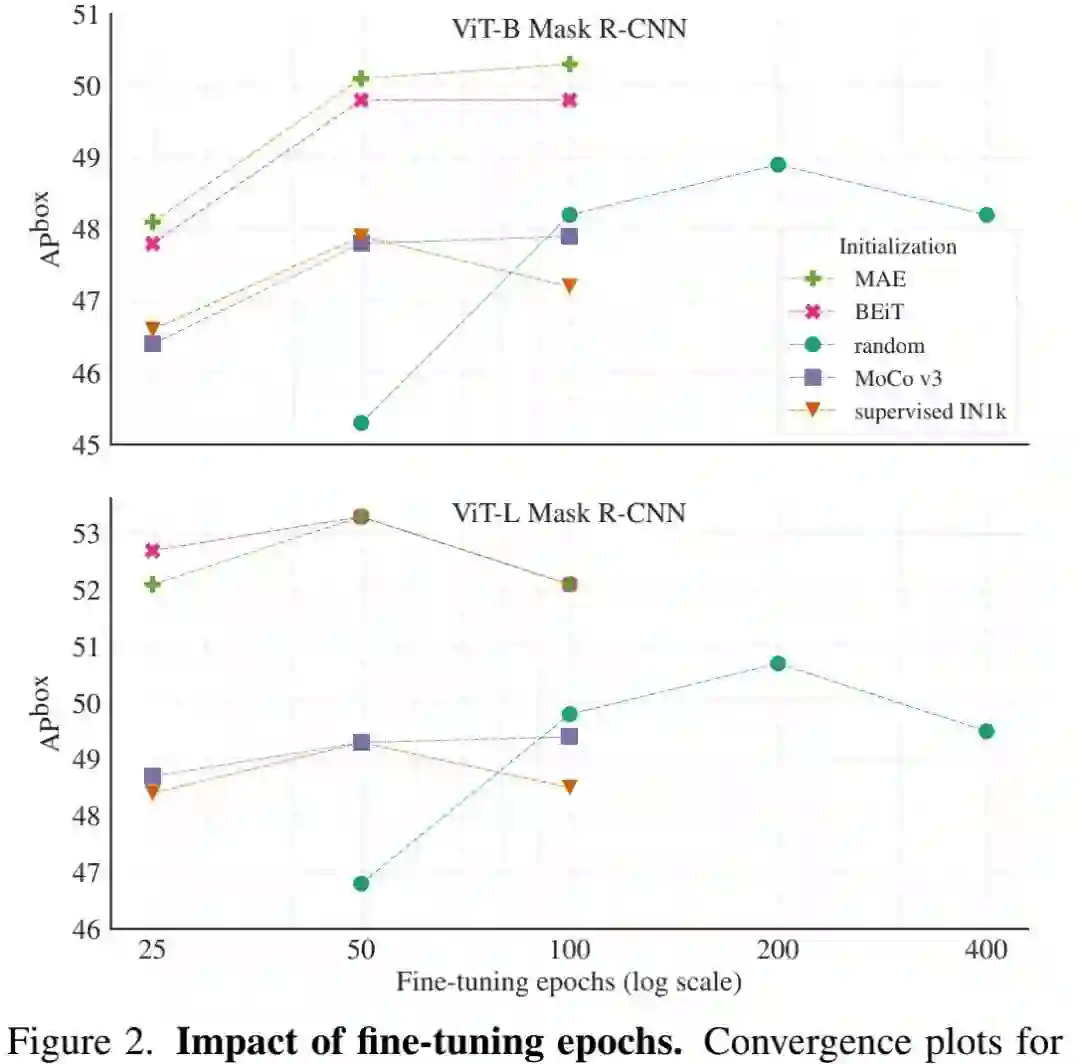
上图给出了预训练是如何影响微调收敛的,可以看到:相比随机初始化,预训练初始化可以显著加速收敛过程,大约加速4倍 。
Discussion
对于迁移学习来说,COCO数据集极具挑战性。由于较大的训练集(约118K+0.9M标准目标),当随机初始化训练时可以取得非常好的结果。我们发现:
-
现有的方法(如监督预训练、MoCoV3无监督预训练)的性能反而会弱于随机初始化基线方案 。
-
已有的无监督迁移学习改进对比的均为监督预训练,并不包含随机初始化方案;
-
此外,他们采用了较弱的模型,具有更低的结果(约40 ),这就导致:不确定如何将已有方法迁移到SOTA模型中。
我们发现:MAE与BEiT提供了首个令人信服的COCO数据集上的指标提升 。更重要的是:这些masking方案具有随模型大小提升进一步改善检测迁移学习能力的潜力 ,而监督预训练与MoCoV3等初始化方式并无该能力。
Ablations and Analysis

上表对比了单尺度与多尺度版本Mask R-CNN的性能,从中可以看到:多尺度FPN设计可以带来1.3-1.7指标提升 ,而耗时仅提升5-10%,多尺度内存占用提升小于1%。

上表对比了降低显存与时间复杂度的不同策略,可以看到:
-
局部+全局的组合方式(即第二种)具有最佳的内存占用与耗时均衡;
-
相比纯局部自注意力方式,全局自注意力可以带来2.6指标提升。
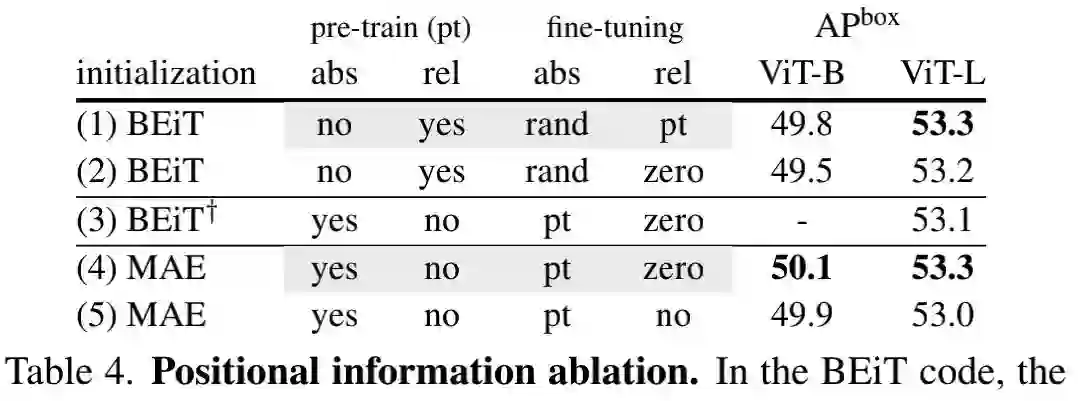
上表比较了不同位置信息的性能对比,从中可以看到:
-
对于仅使用绝对位置嵌入的预训练模型,在微调阶段引入相对位置偏置可以带来0.2-0.3指标提升;
-
预训练相对位置偏置可以带来0.1-0.3指标增益;
-
相对位置偏置会引入额外的负载:训练与推理耗时分别增加25%和15%,内存占用提升15%。
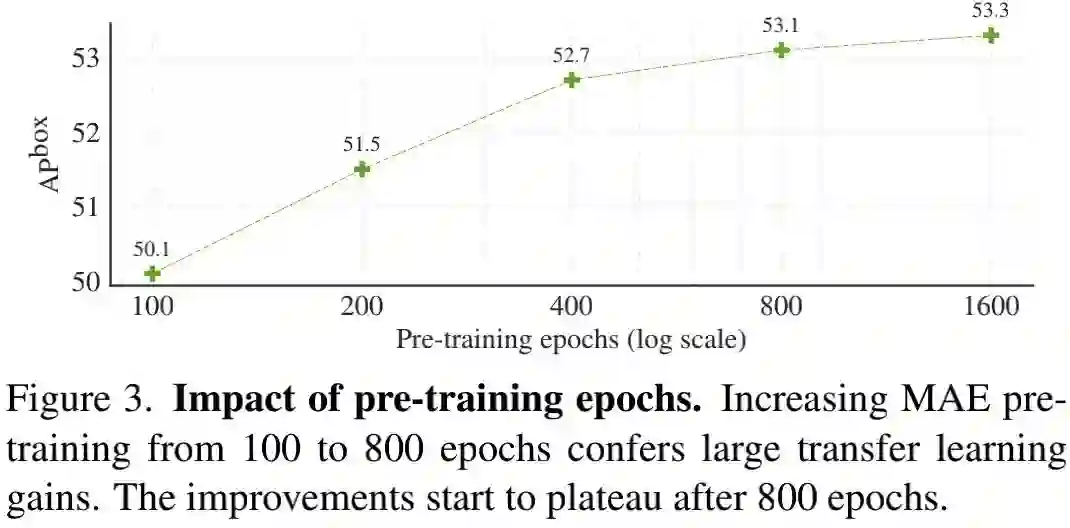
上图对比了预训练周期对于性能的影响,可以看到:
-
在100-800epoch预训练周期下,越多的预训练周期带来越高的迁移学习性能;
-
在800-1600epoch下,仍可带来0.2指标的性能增益。
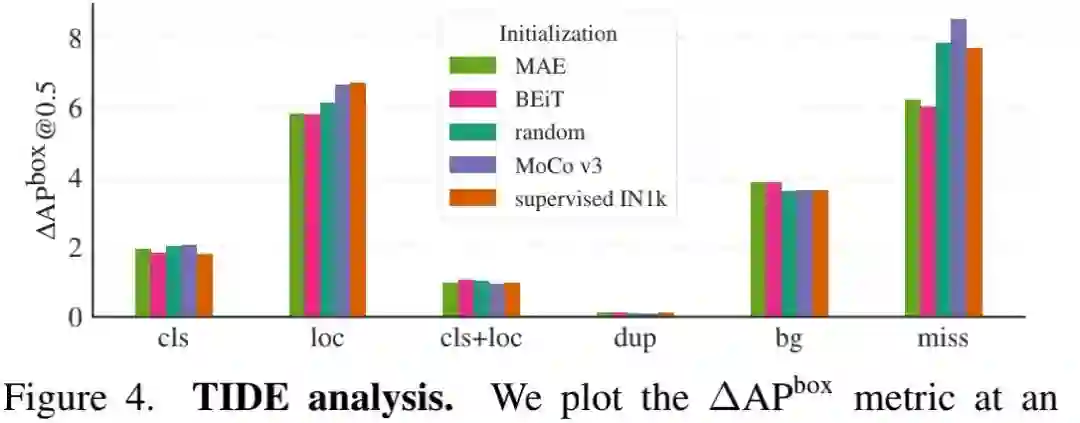
上图给出了TIDE工具生成的误差分析,可以看到:
-
对于正确定位的目标,所有的初始化可以得到相似的分类性能;
-
相比其他初始化,MAE与BEiT可以改善定位性能。

上表给出了不同骨干的复杂度对比(ViT-B与ResNet-101具有相同的性能:48.9 ),可以看到:
-
在推理耗时方面,ResNet-101骨干更快;
-
在训练方面,ViT-B仅需200epoch即可达到峰值性能,而ResNet-101需要400epoch。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# 极市平台签约作者#

happy
知乎:AIWalker
AIWalker运营、CV技术深度Follower、爱造各种轮子
研究领域:专注low-level,对CNN、Transformer、MLP等前沿网络架构
保持学习心态,倾心于AI技术产品化。
公众号:AIWalker
作品精选




