【泡泡一分钟】一种用于单张图像大尺度人脸三维重建的VRN算法(ICCV2017-108)
每天一分钟,带你读遍机器人顶级会议文章
标题:Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression
作者:Aaron S. Jackson, Adrian Bulat, Vasileios Argyriou, Georgios Tzimiropoulos
来源:International Conference on Computer Vision (ICCV 2017)
编译:王嫣然 周平
审核:陈世浪
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

人脸三维重建是一个非常困难的计算机视觉基础问题。当前系统通常假设多个面部图像(有时来自相同主题)的可用性作为输入,并且必须解决许多方法学挑战,例如建立较大面部动作,表情和非均匀照明的密集对应。通常,这些方法需要复杂且低效的途径来进行模型构建和拟合。
在该工作中,我们建议使用卷积神经网络来解决现有问题,卷积神经网络模型可以使用二维图像和三维面部模型或扫描件组成的数据集进行训练。本文使用的CNN模型仅用于单个二维面部图像,不需要精准对齐,也不需要在图像间建立密集的对应关系,适用于任意面部姿态和表情,并且可以绕过三维形变模型的构造(训练期间)和拟合(测试期间)以重建三维面部几何体(包括面部不可见部分)。我们通过简单的CNN架构实现这一点,该架构执行从单个二维图像直接回归三维面部几何体的体积表示。尤其是对于大面部姿态和表情的情况,我们还展示了如何将面部标记定位的相关任务与本文所提出的框架结合以提高重建质量。
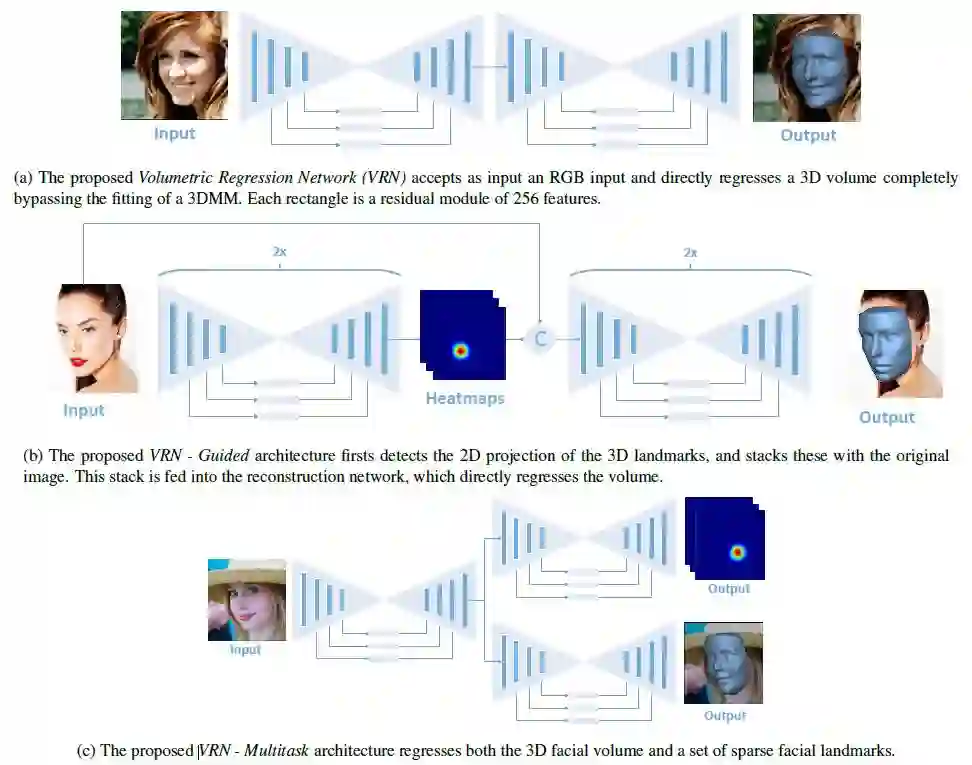
上图分别为本文所提出的VRN、VRN-Guided、VRN-Multitask三种架构图示。VRN算法接受RGB图像作为输入,并直接回归三维体,完全绕过三维形变模型拟合,每个矩形是256个特征组成的残差模块。VRN-Guided算法首先检测三维标记的二维投影,并将它们与原始图像堆叠在一起,该堆栈被送入重建网络后的到结果。VRN-Multitask架构使三维面部体素和一组稀疏面部标记回归得到最终的效果。
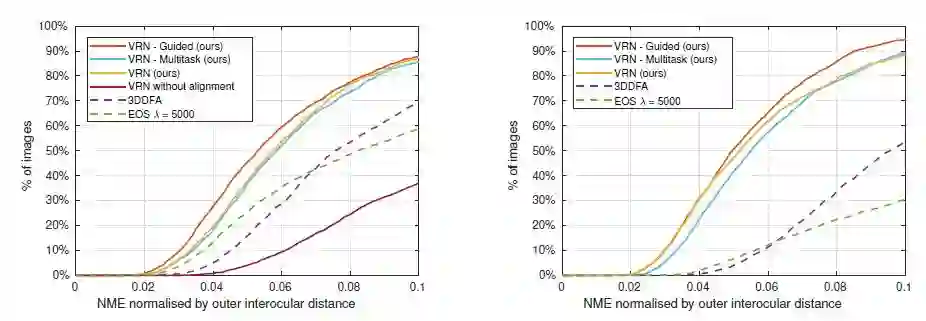
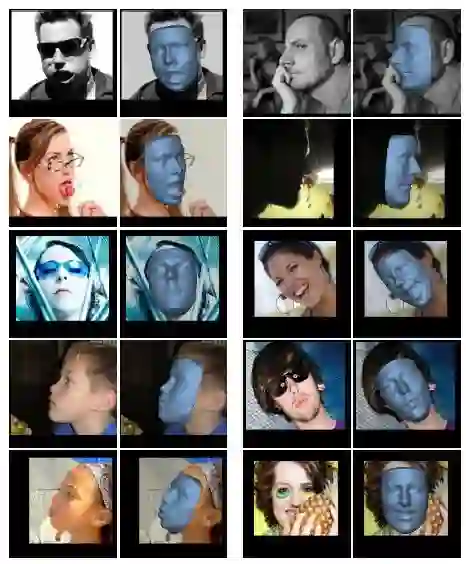
上图分别为在ALFW2000-3D数据集(左)和BU-4DFE数据集(右)上的表现,可以看出,本文提出的三种模型架构具有较高的重建准确率,其中VRN-Guided表现最好,以下是VRN-Guided方法处理AFLW2000-3D数据集的效果展示。

Abstract
3D face reconstruction is a fundamental Computer Vision problem of extraordinary difficulty. Current systems often assume the availability of multiple facial images (sometimes from the same subject) as input, and must address a number of methodological challenges such as establishing dense correspondences across large facial poses, expressions, and non-uniform illumination. In general these methods require complex and inefficient pipelines for model building and fitting. In this work, we propose to address many of these limitations by training a Convolutional Neural Network (CNN) on an appropriate dataset consisting of 2D images and 3D facial models or scans. Our CNN works with just a single 2D facial image, does not require accurate alignment nor establishes dense correspondence between images, works for arbitrary facial poses and expressions, and can be used to reconstruct the whole 3D facial geometry (including the non-visible parts of the face) bypassing the construction (during training) and fitting (during testing) of a 3D Morphable Model. We achieve this via a simple CNN architecture that performs direct regression of a volumetric representation of the 3D facial geometry from a single 2D image. We also demonstrate how the related task of facial landmark localization can be incorporated into the proposed framework and help improve reconstruction quality, especially for the cases of large poses and facial expressions.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




