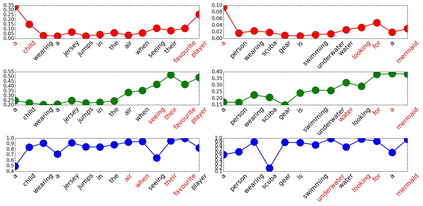
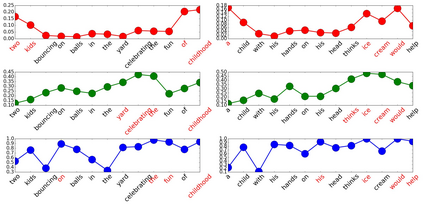
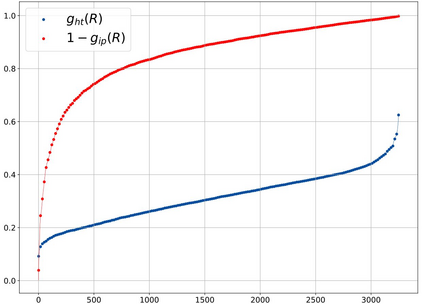
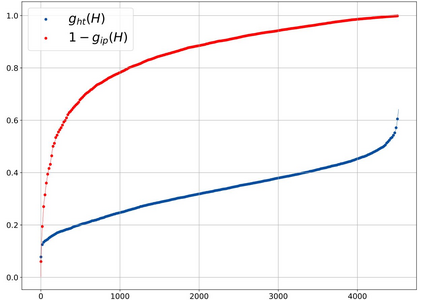
Generating stylized captions for an image is an emerging topic in image captioning. Given an image as input, it requires the system to generate a caption that has a specific style (e.g., humorous, romantic, positive, and negative) while describing the image content semantically accurately. In this paper, we propose a novel stylized image captioning model that effectively takes both requirements into consideration. To this end, we first devise a new variant of LSTM, named style-factual LSTM, as the building block of our model. It uses two groups of matrices to capture the factual and stylized knowledge, respectively, and automatically learns the word-level weights of the two groups based on previous context. In addition, when we train the model to capture stylized elements, we propose an adaptive learning approach based on a reference factual model, it provides factual knowledge to the model as the model learns from stylized caption labels, and can adaptively compute how much information to supply at each time step. We evaluate our model on two stylized image captioning datasets, which contain humorous/romantic captions and positive/negative captions, respectively. Experiments shows that our proposed model outperforms the state-of-the-art approaches, without using extra ground truth supervision.
翻译:生成图像的模版化字幕是图像字幕中新出现的一个主题。 如果将图像作为投入, 它需要系统生成一个具有特定风格( 幽默、 浪漫、 正面和负面) 的字幕, 并准确描述图像内容的语义。 在本文中, 我们提出一个新的模版化图像字幕模型, 有效地将两种要求都考虑在内。 为此, 我们首先设计了一个名为样式- 事实 LSTM 的新版本, 作为我们模型的构件。 它使用两组矩阵来分别捕捉事实和模版化知识, 并自动学习基于上下文的两种组的字级权重。 此外, 当我们培训模型以捕捉模版化元素时, 我们提出一个基于参考事实模型的适应性学习方法。 它为模型从Styl化字幕标签中学习时提供事实知识, 并且能够适应性地对每步步提供多少信息。 我们用两个模版化图像模型来分别捕捉到基于前一背景的图理学/ 实验性外观, 分别显示我们所提出的真实性地面图理学/ 。