Interspeech 2019 | 基于多模态对齐的语音情感识别
本文来自公众号滴滴科技合作,AI科技评论获授权转载,如需转载请联系原公众号。
Interspeech 2019


论文地址:https://arxiv.org/abs/1909.05645
模型
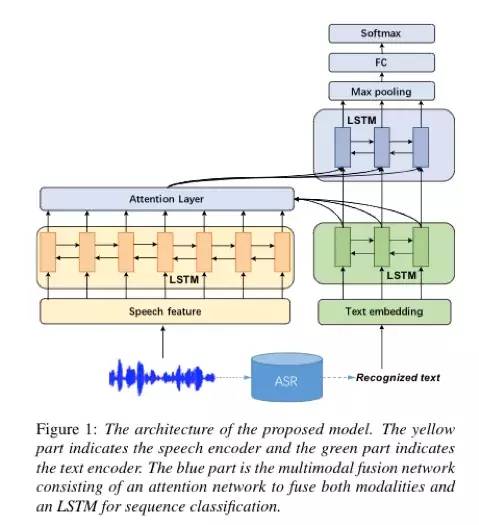
本文提出的多模态对齐的语音情感识别的模型,主要包括语音的编码器模块,语音识别文本的编码器模块,以及基于注意力机制的多模态融合网络模块,具体的模型结构图如上图。
语音的编码器模块
我们首先获取语音的低维度的基于帧的MFCC特征,然后用BiLSTM对音频基于帧进行高维特征表示。
我们首先预训练(Pretraining)来获取单词的词向量(Word Embedding)表示,然后用BiLSTM对ASR识别文本基于单词进行高维特征表示。
我们利用Attention机制动态学出每个单词文本特征的权重和每帧语音的特征,然后加权求和得到每个单词的语音对齐的特征,接着我们将对齐的特征和文本的特征拼接并用BiLSTM来做特征的融合,最后我们用最大池化层和全连接层进行情感分类。
实验
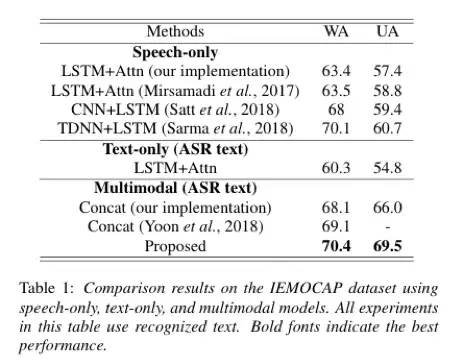
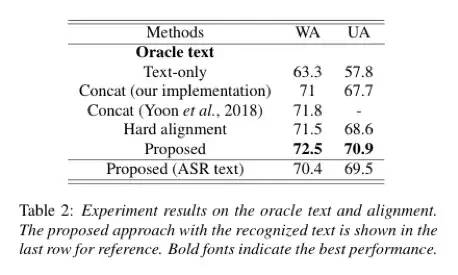
论文在语音情感识别的公开数据集IEMOCAP评测了模型。IEMOCAP数据集是由10个演员录制,对话主要包括10个情感。论文与之前的方法保持一致使用了主要的4个情感(生气,开心,中性,伤心)。

1. Facebook 自然语言处理新突破:新模型能力赶超人类 & 超难 NLP 新基准
2. 巴赫涂鸦创作者 Anna Huang 现身上海,倾情讲解「音乐生成」两大算法
3. 一份完全解读:是什么使神经网络变成图神经网络?


点击阅读原文,查看更多语音语义资源
登录查看更多
相关内容

INTERSPEECH是关于口语处理科学和技术的全球最大、最全面的会议。INTERSPEECH会议强调跨学科的方法,涉及语音科学和技术的各个方面,从基础理论到高级应用。
官网地址:http://dblp.uni-trier.de/db/conf/interspeech/index.html
专知会员服务
33+阅读 · 2020年1月5日
Arxiv
7+阅读 · 2019年4月18日
Arxiv
21+阅读 · 2019年2月4日
Arxiv
4+阅读 · 2018年4月2日





相关VIP内容
专知会员服务
33+阅读 · 2020年1月5日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年4月18日
Arxiv
21+阅读 · 2019年2月4日
Arxiv
4+阅读 · 2018年4月2日