学界 | 阿里 NIPS 2017 Workshop论文:基于 TensorFlow 的深度模型训练 GPU 显存优化
AI 科技评论按:本文转自“阿里技术”, AI 科技评论获授权转载,并做了不改动原意的编辑。
NIPS 2017 在美国长滩举办,场面非常热烈。在本届会议上,阿里巴巴除有两篇论文入选 Workshop 并进行 Oral 和 Poster 形式报告外,三大技术事业部连续 3 天(5 日-7 日)在阿里展区举行多场技术研讨会,向 5000 余名参会人员介绍阿里在机器学习、人工智能领域的技术研究、产品与落地应用。

(NIPS 2017 阿里巴巴展台-阿里巴巴 iDST 院长金榕进行演讲)
这篇介绍深度模型训练 GPU 显存优化的论文《Training Deeper Models by GPU Memory Optimization on TensorFlow》于 8 日在 NIPS 2017 ML Systems Workshop 中由作者做口头报告。这篇论文聚焦特征图,提出两种方法减少深度神经网络训练过程中的显存消耗,并且把这些方法的实现无缝整合到 TensorFlow 中,克服了 TensorFlow 训练大模型时无法有效优化显存的缺点。
近期深度学习在不同应用中发挥的作用越来越重要。训练深度学习模型的必要逻辑包括适合 GPU 的并行线性代数计算。但是,由于物理限制,GPU 的设备内存(即显存)通常比主机内存小。最新的高端 NVIDIA GPU P100 具备 12–16 GB 的显存,而一个 CPU 服务器有 128GB 的主机内存。然而,深度学习模型的趋势是「更深更宽」的架构。例如,ResNet 包含多达 1001 个神经元层,神经网络机器翻译(NMT)模型包含 8 个使用注意力机制的层,且 NMT 模型中的大部分的单个层是按顺序水平循环展开的,难以避免地带来大量显存消耗。
简言之,有限的 GPU 显存与不断增长的模型复杂度之间的差距使显存优化成为必然。下面将介绍深度学习训练流程中 GPU 显存使用的主要组成。
特征图(feature map)
对于深度学习模型,特征图是一个层在前向传输中生成的中间输出结果,且在后向传输的梯度计算中作为输入。图 1 是 ResNet-50 在 ImageNet 数据集上进行一次小批量训练迭代的 GPU 显存占用曲线。随着特征图的不断累积,曲线到达最高点。特征图的大小通常由批尺寸(batch size)和模型架构决定(如 CNN 架构的卷积步幅大小、输出通道数量;RNN 架构的门数量、时间步长和隐层大小)。不再需要作为输入的特征图占用的显存将会被释放,导致图 1 中显存占用曲线的下降。对于复杂的模型训练,用户必须通过调整批尺寸,甚至重新设计模型架构来避免「内存不足」的问题。尽管在分布式训练的情况下,训练任务可以分配到多个设备上来缓解内存不足的问题,但是这也导致了额外的通信开销。设备的带宽限制也可能显著拖慢训练过程。
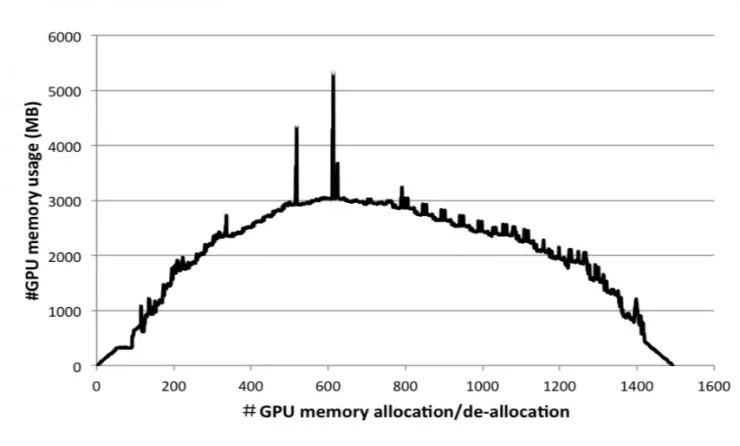
图 1:ResNet-50 的显存占用在一个训练步中的变化曲线。横轴代表分配/释放次数,纵轴代表当前显存占用的总比特数。
权重
与特征图相比,权重占用内存相对较少。在这篇论文中,权重作为 GPU 内存中的持久内存,只有整个训练任务完成后才可以被释放。
临时显存(Temporary memory)
一些算法(如基于 Fast-Fourier-Transform(FFT)的卷积算法)需要大量的额外显存。这些显存占用是暂时的,在计算结束后立即得到释放。临时显存的大小可以通过在 GPU 软件库(如 cuDNN)中列举每个算法来自动调整,因此可以被忽略。
很明显,特征图是 GPU 显存使用的主要组成部分。论文作者聚焦特征图,提出了两种方法来解决 GPU 显存限制问题,即通用的「swap-out/in」方法以及适用于 Seq2Seq 模型的内存高效注意力层。所有这些优化都基于 TensorFlow。TensorFlow 具备内置内存分配器,实现了「best-fit with coalescing」的算法。该分配器旨在通过 coalescing 支持碎片整理(de-fragmentation)。但是,它的内置内存管理策略未考虑大模型训练时的显存优化。
《Training Deeper Models by GPU Memory Optimization on TensorFlow》的论文贡献如下:聚焦于特征图,提出两种方法减少深度神经网络训练过程中的 GPU 显存消耗。基于数据流图的「swap-out/in」方法使用主机内存作为更大的内存池,从而放宽 GPU 显存上限的限制;而内存高效的注意力层可用来优化显存消耗量大的 Seq2Seq 模型。这些方法的实现被无缝整合到 TensorFlow 中,且可透明地应用于所有模型,无需对现有模型架构的描述作任何改变。

论文: Training Deeper Models by GPU Memory Optimization on TensorFlow
作者:孟晨、孙敏敏、杨军、邱明辉、顾扬
论文地址:http://t.cn/RTpfoXt
摘要:随着大数据时代的到来、GPGPU 的获取成本降低以及神经网络建模技术的进步,在 GPU 上训练深度学习模型变得越来越流行。然而,由于深度学习模型的内在复杂性和现代 GPU 的显存资源限制,训练深度模型仍然是一个困难的任务,尤其是当模型大小对于单个 GPU 而言太大的时候。在这篇论文中,我们提出了一种基于通用数据流图的 GPU 显存优化策略,即「swap-out/in」,将主机内存当做一个更大的内存池来克服 GPU 的内存限制。同时,为了优化内存消耗大的 Seq2Seq 模型,我们还提出了专用的优化策略。我们将这些策略无缝整合到 TensorFlow 中,且优化不会造成准确率的损失。我们在大量的实验中观察到了显著的显存使用降低。给定一个固定的模型和系统配置,最大训练批尺寸可以增加 2 到 30 倍。
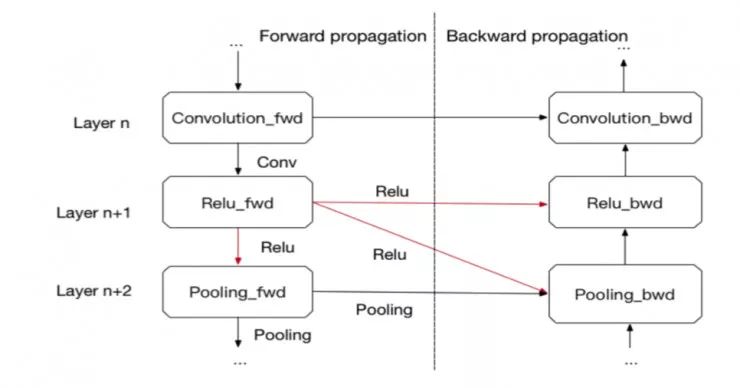
图 2:引用计数(reference count)
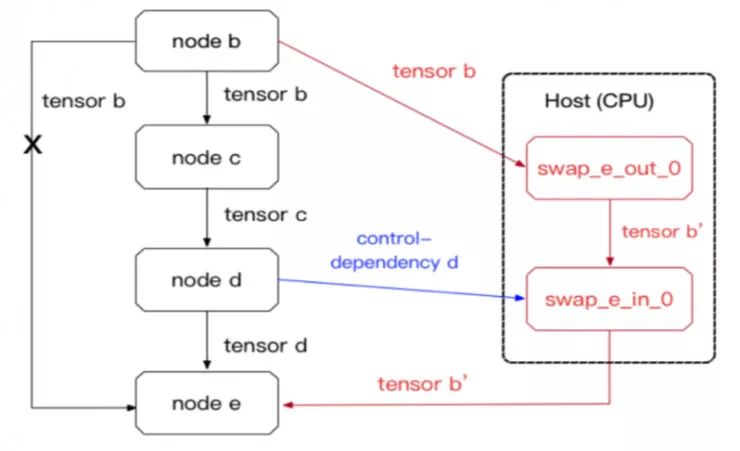
图 3:swap out/in 优化的原子操作(Atomic operation)
删除从节点 e 到节点 b 的引用边,并添加了红色和蓝色的节点和边。
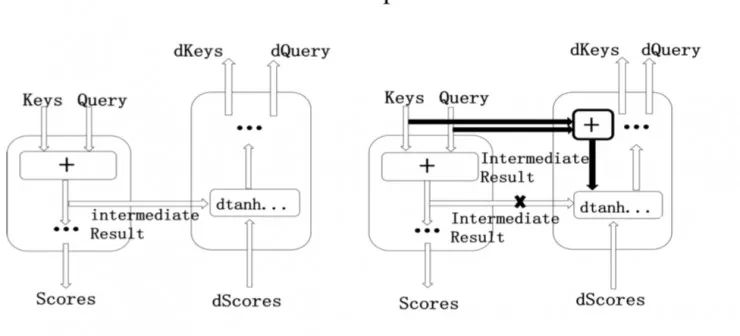
图 4:注意力操作(Attention operation)优化
d 指梯度。图左未经优化,图右经过了显存优化。
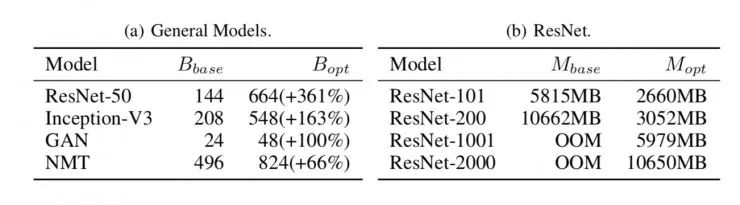
表 1:对 swap out/in 的评估。GPU 的显存上限是 12GB。

表 2:对显存高效序列模型的评估
————— AI 科技评论招人了 —————
AI 科技评论期待你的加入,和我们一起见证未来!
现诚招学术编辑、学术兼职、学术外翻
详情请点击招聘启事
————— 给爱学习的你的福利 —————
上海交通大学博士讲师团队
从算法到实战应用,涵盖CV领域主要知识点;
手把手项目演示
全程提供代码
深度剖析CV研究体系
轻松实战深度学习应用领域!
详细了解请点解阅读原文
▼▼▼

————————————————————




