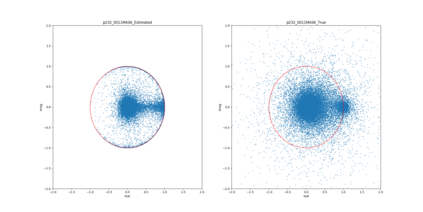
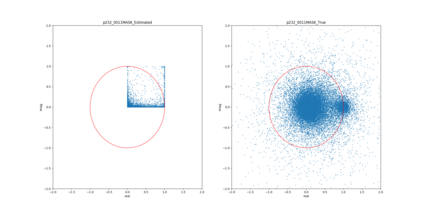
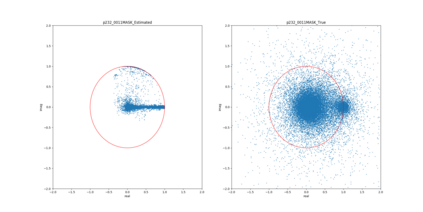
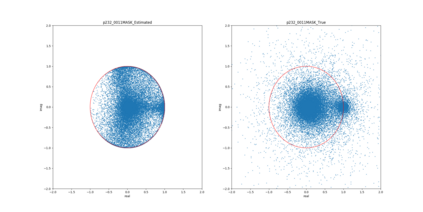
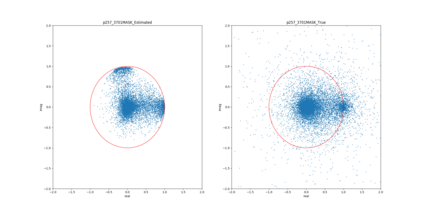
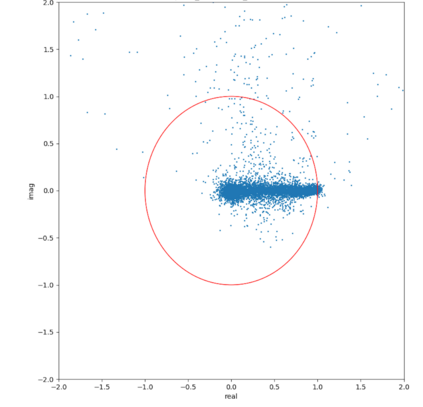
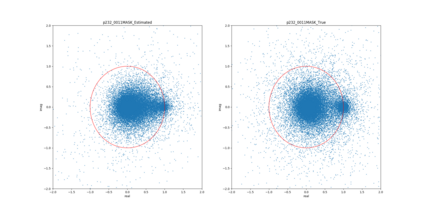
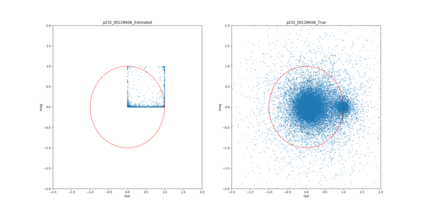
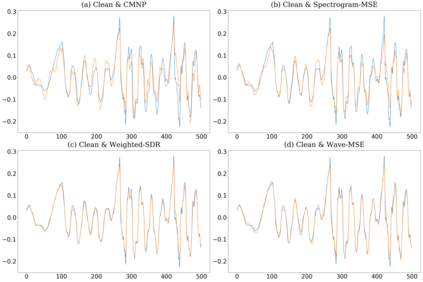
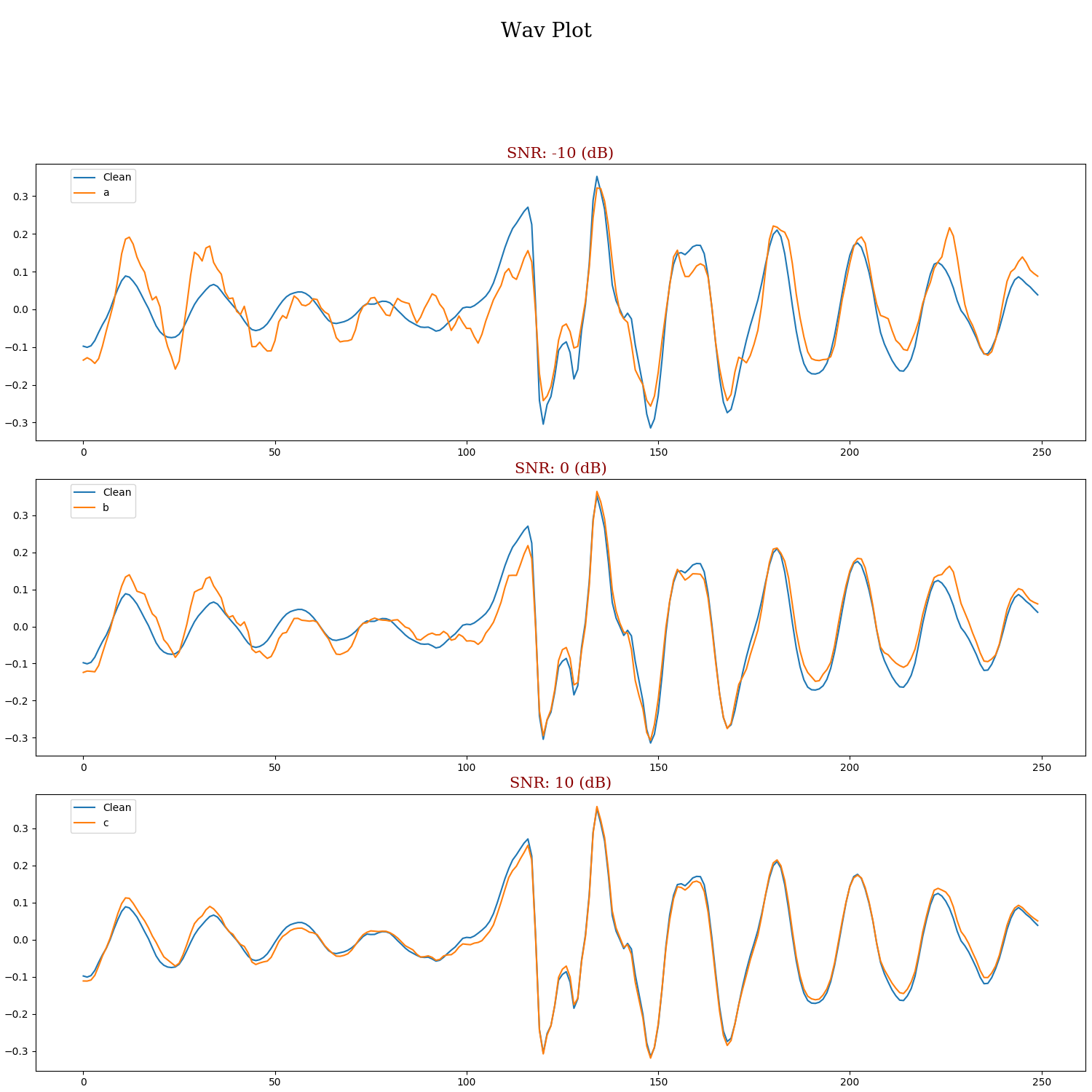
Most deep learning-based models for speech enhancement have mainly focused on estimating the magnitude of spectrogram while reusing the phase from noisy speech for reconstruction. This is due to the difficulty of estimating the phase of clean speech. To improve speech enhancement performance, we tackle the phase estimation problem in three ways. First, we propose Deep Complex U-Net, an advanced U-Net structured model incorporating well-defined complex-valued building blocks to deal with complex-valued spectrograms. Second, we propose a polar coordinate-wise complex-valued masking method to reflect the distribution of complex ideal ratio masks. Third, we define a novel loss function, weighted source-to-distortion ratio (wSDR) loss, which is designed to directly correlate with a quantitative evaluation measure. Our model was evaluated on a mixture of the Voice Bank corpus and DEMAND database, which has been widely used by many deep learning models for speech enhancement. Ablation experiments were conducted on the mixed dataset showing that all three proposed approaches are empirically valid. Experimental results show that the proposed method achieves state-of-the-art performance in all metrics, outperforming previous approaches by a large margin.
翻译:最深层次的强化言语的基于学习的模型主要侧重于估计光谱量值,同时重新使用从吵闹的演讲到重建的阶段。这是因为很难估计清洁言语的阶段。为了改善言语的增强性能,我们从三个方面解决了阶段的估算问题。首先,我们提出了深复杂的U-Net,这是一个先进的U-Net结构化模型,其中包含了定义明确的复杂价值的建筑块,以处理复杂价值的光谱。第二,我们提出了一种极地协调的复杂价值的掩码法,以反映复杂理想比率面具的分布。第三,我们定义了一种新的损失功能,即加权源对扭曲率损失,其设计与定量评价措施直接相关。我们的模式是在语音银行和DEPAND数据库的混合体上进行评估的,许多深层学习模型广泛使用这种模型来强化言语力。在混合数据集上进行了实验,表明所有三种拟议方法都是实证有效的。实验结果显示,拟议的方法在所有计量方法中都取得了最先进的性业绩,以大幅度取代了以前的方法。