
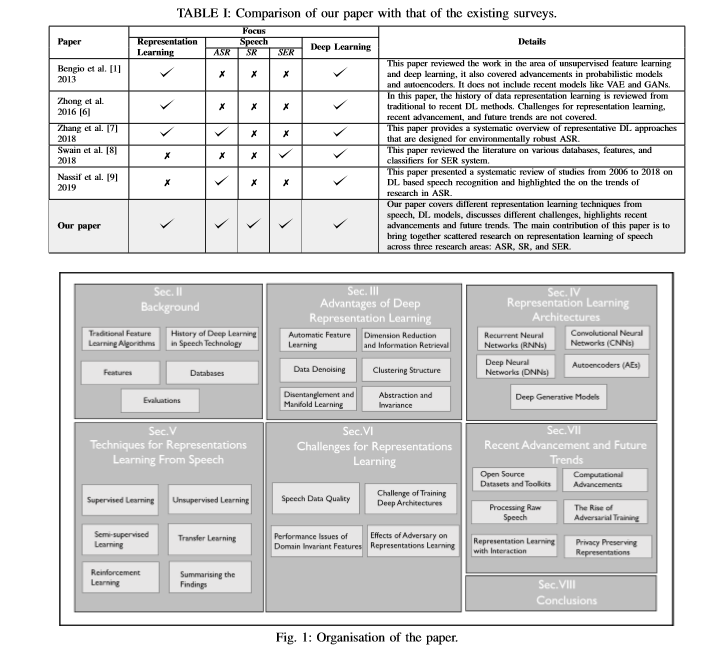
题目: Deep Representation Learning in Speech Processing: Challenges, Recent Advances, and Future Trends
简介: 传统上,语音处理研究将设计人工工程声学特征(特征工程)的任务与设计有效的机器学习(ML)模型以做出预测和分类决策的任务分离为一个独立的问题。这种方法有两个主要缺点:首先,手工进行的特征工程很麻烦并且需要人类知识。其次,设计的功能可能不是最适合当前目标的。这引发了语音社区中采用表示表达学习技术的最新趋势,该趋势可以自动学习输入信号的中间表示,从而更好地适应手头的任务,从而提高性能。表示学习的重要性随着深度学习(DL)的发展而增加,在深度学习中,表示学习更有用,对人类知识的依赖性更低,这有助于分类,预测等任务。本文的主要贡献在于:通过将跨三个不同研究领域(包括自动语音识别(ASR),说话者识别(SR)和说话者情绪识别(SER))的分散研究汇总在一起,对语音表示学习的不同技术进行了最新和全面的调查。最近针对ASR,SR和SER进行了语音复习,但是,这些复习都没有集中于从语音中学习表示法,这是我们调查旨在弥补的差距。
成为VIP会员查看完整内容

相关内容

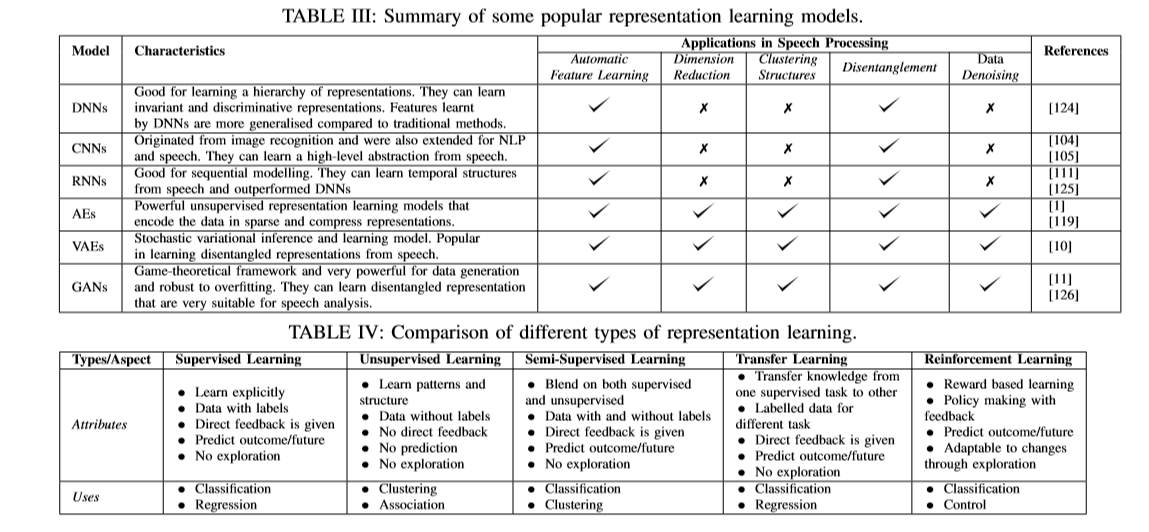
表示学习是通过利用训练数据来学习得到向量表示,这可以克服人工方法的局限性。 表示学习通常可分为两大类,无监督和有监督表示学习。大多数无监督表示学习方法利用自动编码器(如去噪自动编码器和稀疏自动编码器等)中的隐变量作为表示。 目前出现的变分自动编码器能够更好的容忍噪声和异常值。 然而,推断给定数据的潜在结构几乎是不可能的。 目前有一些近似推断的策略。 此外,一些无监督表示学习方法旨在近似某种特定的相似性度量。提出了一种无监督的相似性保持表示学习框架,该框架使用矩阵分解来保持成对的DTW相似性。 通过学习保持DTW的shaplets,即在转换后的空间中的欧式距离近似原始数据的真实DTW距离。有监督表示学习方法可以利用数据的标签信息,更好地捕获数据的语义结构。 孪生网络和三元组网络是目前两种比较流行的模型,它们的目标是最大化类别之间的距离并最小化了类别内部的距离。
专知会员服务
80+阅读 · 2020年3月5日
Arxiv
8+阅读 · 2019年2月8日


相关VIP内容
专知会员服务
80+阅读 · 2020年3月5日
相关资讯
相关论文
Arxiv
8+阅读 · 2019年2月8日