机器之心专栏
论文作者:Shiliang Zhang、Lei Ming、Zhijie Yan
语音领域顶级学术会议 Interspeech 2019 将于 9 月 15-19 日在奥地利格拉茨开幕。本文介绍了阿里巴巴达摩院机器智能-语音实验室被此大会接收的一篇论文,作者们提出了一种自动纠错模型,该模型采用 Transformer 作为纠错器,将前端基于 CTC 的语音识别系统的识别结果作为输入,可以自动纠正大量的识别错误,特别是识别结果中的替换错误。
INTERSPEECH 是语音科学和技术领域最大、最全面的国际学术会议, 今年的大会将在奥地利第二大城市格拉茨举办。
在 INTERSPEECH 会议期间,来自全球学术界和产业界的研究人员齐聚一堂,讨论语音领域的新技术,包括语音合成、语音识别、语音增强这些细分领,在会议上展示的研究成果代表着语音相关领域的最新研究水平和未来的发展趋势。
在此篇被 Interspeech 接收的论文中,来自阿里巴巴达摩院-机器智能技术团队的研究者们提出了一种自动纠错模型(Listener-Decoder-Speller,LDS),该模型采用 Transformer 作为纠错器,将前端基于 CTC 的语音识别系统的识别结果作为输入,可以自动纠正大量的识别错误,特别是识别结果中的替换错误。
![]()
论文地址: https://arxiv.org/pdf/1904.10045.pdf
近年来,基于端到端的语音识别系统开始慢慢成为主流,其中两个具有代表性的框架是:
1)CTC(Connectionist Temporal Classification)准则及其变形;
2)基于注意力机制的编解码模型(Attention-Encoder-Decoder)。
这两个框架都将语音识别当作一个序列到序列的映射问题,同时提出不等长输入序列和输出序列之间的对齐方法。
CTC 通过引入空字符(blank)来进行序列的扩展,Attention-Encoder-Decoder 则采用注意力机制来进行输入声学特征和输入预测字符之间的对齐关系。
CTC 准则采用了输出独立无关假设,即每个时刻的预测样本之间是无关的。
这个假设简化了模型训练和测试,但是它也使得基于 CTC 的端到端识别系统成为了一个纯声学模型,通常需要联合语音模型进行解码才能获得理想的识别结果。
由于大量同音字的存在,纯靠声学模型往往很难在普通话识别中对文本加以有效的区分,需要联合语言模型,利用文本的语义信息加以补充。
因此,目前基于 CTC 的识别系统,通常会联合 N-gram 语言模型,采用构建 WFST 的方式进行解码。
尽管如此,由于 N-gram 引入的语音信息是有限的局部文本信息,还是很难有效地发现识别错误,特别是同音字替换错误。
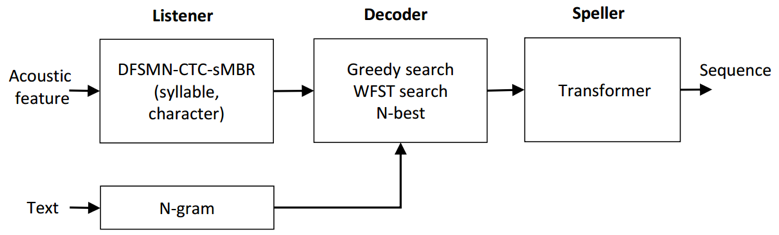
针对上述问题,本文中提出了一种联合 CTC 识别系统和 Transformer 纠错系统的识别框架,称之为 Listener-Decoder-Speller (LDS)。
其结构框架如下图所示:
![]()
LDS 的模型主要包含 3 个组成部分:
Listener,Decoder,Speller:
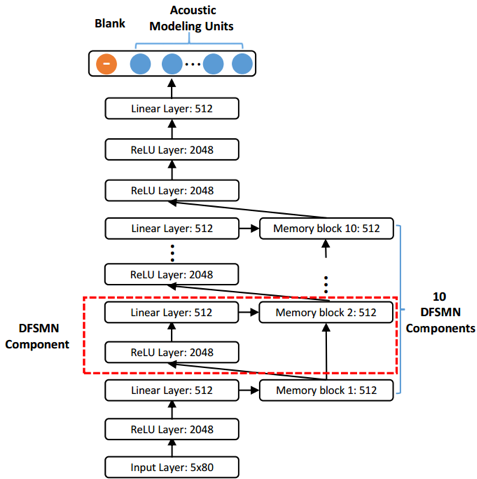
Listener 是一个基于 DFSMN-CTC-sMBR 的声学模型,可以基于输入的语音信号,预测每个声学建模单元的后验概率。
在具体实验中,研究者探索了不同的声学建模(音节,字符)单元对其性能的影响。
DFSMN(Deep Feedforward Sequential Memory Networks)是研究者之前的工作中提出的一种网络结构,其模型结构如下图所示:
![]()
Decoder 是一个解码器,可以单独对 CTC 声学模型进行解码,也可以通过联合语言模型进行解码,得到识别结果。
相对应的解码方法分别称之为:
Greedy-Search 和 WFST-Beam-Search。
值得一提的是,本文中研究者提出采用 N-best 的数据扩展方法,保留 N 条识别结果的候选,用于扩充后端纠错模型的训练数据,显著提升了纠错模型的性能。
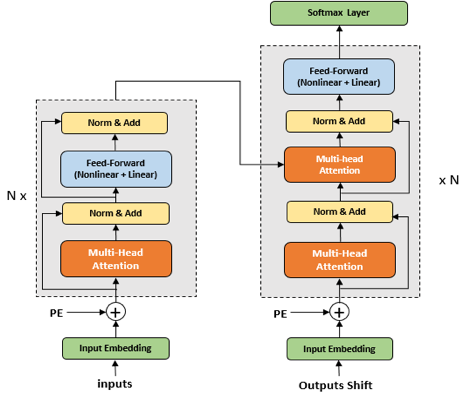
Speller 是基于 Transformer 的纠错模型,其原理和机器翻译有异曲同工之处。
Speller 的输入是前端模型 CTC 的解码结果,预测的是真实的标注。
由于 Transformer 具有很强的语义建模能力,可以有效地利用上下文信息,自动纠正识别结果中的很多错误,提升识别性能。
关于 Speller 的模型框图如下图所示:
![]()
研究者在一个 2 万小时中文数据库上对 LDS 模型进行了实验验证。
验证采用 DFSMN-CTC-sMBR 模型联合 N-gram 语言模型作为基线系统,并在此基础上通过添加基于 Transformer 的 Speller 构建 LDS。
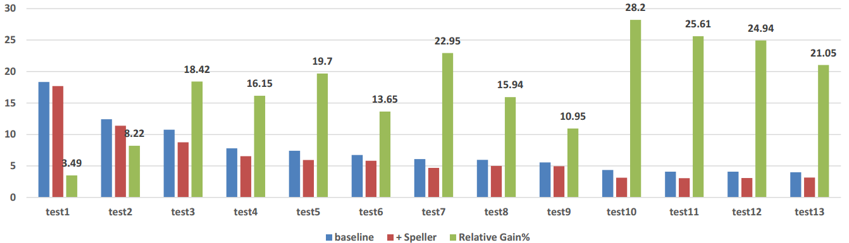
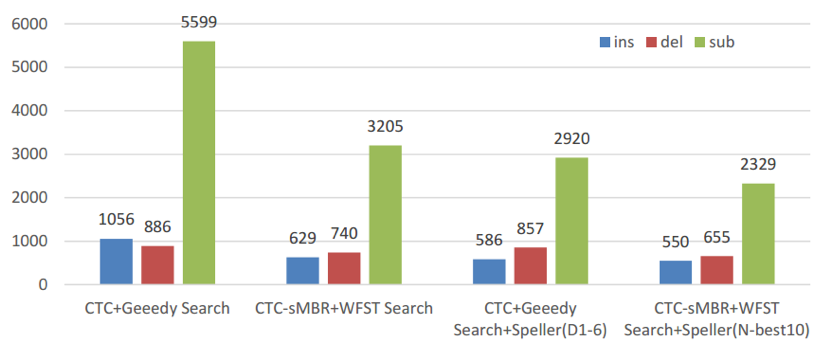
如下图 4 所示,在全部 13 个不同领域的测试数据集上,添加纠错模块可以使得识别系统获得显著的性能提升,提升范围大多在 20 % 以上。
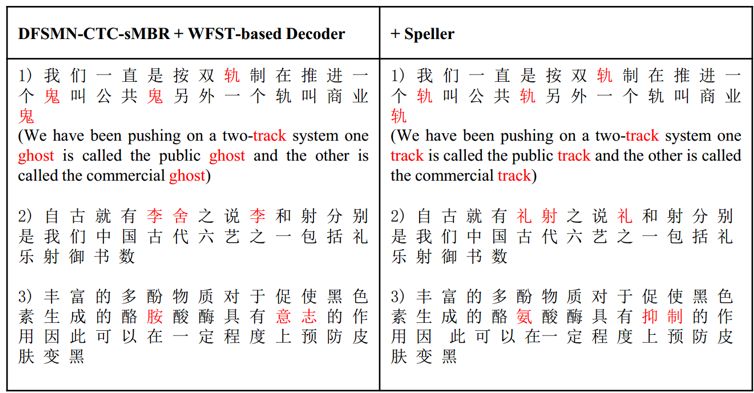
通过对识别错误类型的统计,研究者进一步发现,通过添加纠错模型可以极大地降低识别过程中的替换错误。
![]() 图 4: 基线识别系统和添加了 Speller 的识别系统在不同测试集上的性能对比
图 4: 基线识别系统和添加了 Speller 的识别系统在不同测试集上的性能对比
![]()
图5:不同系统的错误类型和性能对比
![]()
阿里巴巴达摩院机器智能-语音实验室致力于语音识别、语音合成、语音唤醒、声学设计及信号处理、声纹识别、音频事件检测等下一代人机语音交互基础理论、关键技术和应用系统的研究工作,形成了覆盖电商、新零售、司法、交通、制造等多个行业的产品和解决方案,为消费者、企业和政府提供高质量的语音交互服务。
2019 年,达摩院语音实验室共 8 篇论文被语音领域顶会 Interspeech 收录,内容涵盖语音识别、转换、语音数据清洗打标、混合语言模型等方面。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com