腾讯AI Lab 8篇论文入选,从0到1解读语音交互能力 | InterSpeech 2018
AI科技评论按:Interspeech 会议是全球最大的综合性语音信号处理领域的科技盛会,首次参加的腾讯 AI Lab共有8篇论文入选,居国内企业前列。这些论文有哪些值得一提的亮点?一起看看这篇由腾讯 AI Lab供稿的总结文章。 另外,以上事件在雷锋网旗下学术频道 AI 科技评论数据库产品「AI 影响因子」中有相应加分。
9 月 2 到 6 日,Interspeech 会议在印度海得拉巴举办,腾讯 AI Lab 首次参加,有 8 篇论文入选,位居国内企业前列。该年度会议由国际语音通信协会 ISCA(International Speech Communication Association)组织,是全球最大的综合性语音信号处理领域的科技盛会。
腾讯 AI Lab 也在业界分享语音方面的研究成果,今年已在多个国际顶级会议和期刊上发表了系列研究成果,涵盖从语音前端处理到后端识别及合成等整个技术流程。比如今年 4 月举办的 IEEE 声学、语音与信号处理国际会议(ICASSP 2018),是由 IEEE 主办、全球最大、最全面的信号处理及其应用方面的顶级学术会议,腾讯 AI Lab 也入选论文 4 篇,介绍了其在多说话人语音识别、神经网络语言模型建模和说话风格合成自适应方面的研究进展。
在研究方面,腾讯 AI Lab 提出了一些新的方法和改进,在语音增强、语音分离、语音识别、语音合成等技术方向都取得了一些不错的进展。在落地应用上,语音识别中心为多个腾讯产品提供技术支持,比如「腾讯听听音箱」、「腾讯极光电视盒子」,并融合内外部合作伙伴的先进技术,在语音控制、语义解析、语音合成(TTS)等方面都达到了业内领先水平。
本文将基于智能音箱的基本工作流程介绍腾讯 AI Lab 在语音方面的近期研究进展。
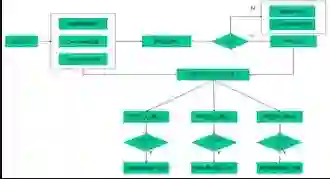
首先,我们先了解一下音箱语音交互技术链条。
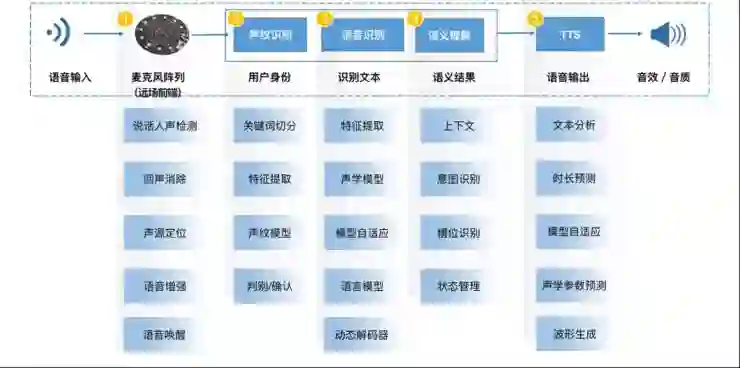
智能音箱的最典型应用场景是家庭,在这种场景中用户与音箱设备的距离通常比用户在智能手机上使用语音应用的距离远很多,因此会引入较明显的室内混响、回声,音乐、电视等环境噪声,也会出现多说话人同时说话,有较强背景人声的问题。要在这样的场景中获取、增强、分离得到质量较好的语音信号并准确识别是智能音箱达到好的用户体验所要攻克的第一道难关。
麦克风阵列是这一步最常用的解决方案之一,比如腾讯听听就采用了由 6 个麦克风组成的环形阵列,能够很好地捕捉来自各个方位的声音。
麦克风采集到声音之后,就需要对这些声音进行处理,对多麦克风采集到的声音信号进行处理,得到清晰的人声以便进一步识别。这里涉及的技术包括语音端点检测、回声消除、声源定位和去混响、语音增强等。另外,对于通常处于待机状态的智能音箱,通常都会配备语音唤醒功能。为了保证用户体验,语音唤醒必须要足够灵敏和快速地做出响应,同时尽量减少非唤醒语音误触发引起的误唤醒。
经过麦克风阵列前端处理,接下来要做的是识别说话人的身份和理解说话内容,这方面涉及到声纹识别、语音识别和模型自适应等方面的问题。
之后,基于对说话内容的理解执行任务操作,并通过语音合成系统合成相应语音来进行回答响应。如何合成高质量、更自然、更有特色的语音也一直是语音领域的一大重点研究方向。
腾讯 AI Lab 的研究范围涵盖了上图中总结的音箱语音交互技术链条的所有 5 个步骤,接下来将依此链条介绍腾讯 AI Lab 近期的语音研究进展。
1)前端
采集到声音之后,首先需要做的是消除噪声和分离人声,并对唤醒词做出快速响应。
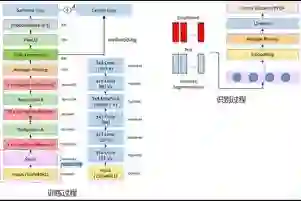
在拾音和噪声消除方面,腾讯 AI Lab 的 Voice Processing(简称 AIVP)解决方案集成了语音检测、声源测向、麦克风阵列波束形成、定向拾音、噪声抑制、混响消除、回声消除、自动增益等多种远场语音处理模块,能有效地为后续过程提供增强过的清晰语音。发表于 Symmetry 的论文《一种用于块稀疏系统的改进型集合-元素比例自适应算法(An Improved Set-membership Proportionate Adaptive Algorithm For A Block-sparse System)》是在回声消除方面的研究。
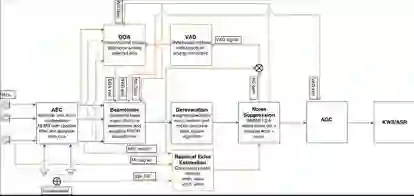
远场语音处理的各个模块
在语音唤醒方面,腾讯 AI Lab 的 Interspeech 2018 研究《基于文本相关语音增强的小型高鲁棒性的关键词检测(Text-Dependent Speech Enhancement for Small-Footprint Robust Keyword Detection)》针对语音唤醒的误唤醒、噪声环境中唤醒、快语速唤醒和儿童唤醒等问题提出了一种新的语音唤醒模型——使用 LSTM RNN 的文本相关语音增强(TDSE)技术,能显著提升关键词检测的质量,并且在有噪声环境下也表现突出,同时还能显著降低前端和关键词检测模块的功耗需求。
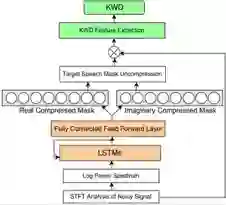
基于文本相关语音增强的关键词检测架构
2)声纹识别
声纹识别是指根据说话人的声波特性进行身份辨识。这种技术有非常广泛的应用范围,比如根据不同家庭用户的偏好定制个性化的应用组合。声纹系统还可用于判断新用户的性别和年龄信息,以便在之后的互动中根据用户属性进行相关推荐。
声纹识别也存在一些有待攻克的挑战。在技术上存在信道失配、环境噪声、短语音、远场等难题,在应用上还有录音冒认、兼容能力、交互设计等挑战。声纹模型还应当具备兼容确认和辨别功能,支持隐式更新和隐式注册,以便随用户使用时间的增长而逐步提升性能。
支持隐式注册的声纹模型的性能随用户使用时长增长而提升
腾讯 AI Lab 除了应用已实现的经典声纹识别算法外(GMM-UBM、GMM/Ivector、DNN/Ivector、GSV),也在探索和开发基于 DNN embedding 的新方法,且在短语音方面已经实现了优于主流方法的识别效果。腾讯 AI Lab 也在进行多系统融合的开发工作——通过合理布局全局框架,使具有较好互补性的声纹算法协同工作以实现更精准的识别。相关部分核心自研算法及系统性能已经在语音顶级期刊上发表。
其中,被 Interspeech 2018 接收的论文《基于深度区分特征的变时长说话人确认(Deep Discriminative Embeddings for Duration Robust Speaker Verification)》提出了一种基于 Inception-ResNet 的声纹识别系统框架,可学习更加鲁棒且更具有区分性的嵌入特征。
同样入选 Interspeech 2018 的论文《从单通道混合语音中还原目标说话人的深度提取网络(Deep Extractor Network for Target Speaker Recovery From Single Channel Speech Mixtures)》提出了一种深度提取网络(如下图所示),可在规范的高维嵌入空间中通过嵌入式特征计算为目标说话人创建一个锚点,并将对应于目标说话人的时间频率点提取出来。
实验结果表明,给定某一说话人一段非常短的语音,如给定该说话人的唤醒词语音(通常 1S 左右),所提出的模型就可以有效地从后续混合语音中高质量地分离恢复出该目标说话人的语音,其分离性能优于多种基线模型。同时,研究者还证明它可以很好地泛化到一个以上干扰说话人的情况。
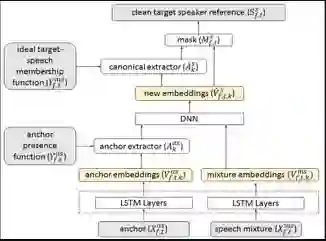
深度提取网络示意图
3)语音识别
语音识别技术已经经历过长足的发展,现在已大体能应对人们的日常使用场景了,但在噪声环境、多说话人场景、「鸡尾酒会问题」、多语言混杂等方面仍还存在一些有待解决的难题。
腾讯 AI Lab 的语音识别解决方案是结合了说话人特征的个性化识别模型,能够为每位用户提取并保存自己个性化声学信息特征。随着用户数据积累,个性化特征会自动更新,用户识别准确率可获得显著提升。
另外,腾讯 AI Lab 还创新地提出了多类单元集合融合建模方案,这是一种实现了不同程度单元共享、参数共享、多任务的中英混合建模方案。这种方案能在基本不影响汉语识别准确度的情况下提升英语的识别水平。
腾讯 AI Lab 有多篇 Interspeech 2018 论文都针对的是这个阶段的问题。
在论文《基于生成对抗网络置换不变训练的单通道语音分离(Permutation Invariant Training of Generative Adversarial Network for Monaural Speech Separation)》中,研究者提出使用生成对抗网络(GAN)来实现同时增强多个声源的语音分离,并且在训练生成网络时通过基于句子层级的 PIT 解决多个说话人在训练过程顺序置换问题。实验也证明了这种被称为 SSGAN-PIT 的方法的优越性,下面给出了其训练过程示意图:
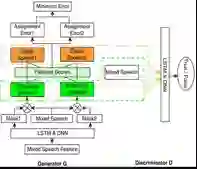
SSGAN-PIT 的训练过程示意图
论文《使用注意机制和门控卷积网络的单声道多说话人语音识别(Monaural Multi-Talker Speech Recognition with Attention Mechanism and Gated Convolutional Networks)》将注意机制和门控卷积网络(GCN)整合进了研究者之前开发的基于排列不变训练的多说话人语音识别系统(PIT-ASR)中,从而进一步降低了词错率。如下左图展示了用于多说话人语音识别的带有注意机制的 PIT 框架,而右图则为其中的注意机制:
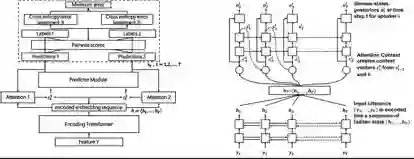
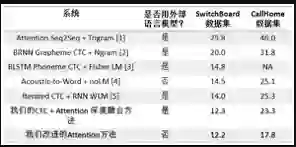
在论文《提升基于注意机制的端到端英语会话语音识别(Improving Attention Based Sequence-to-Sequence Models for End-to-End English Conversational Speech Recognition)》中,研究者提出了两项用于端到端语音识别系统的基于注意的序列到序列模型改进方法。第一项改进是使用一种输入馈送架构——其不仅会馈送语境向量,而且还会馈送之前解码器的隐藏状态信息,并将它们作为解码器的输入。第二项改进基于一种用于序列到序列模型的序列最小贝叶斯风险(MBR)训练的更好的假设集合生成方法,其中在 MBR 训练阶段为 N-best 生成引入了 softmax 平滑。实验表明这两项改进能为模型带来显著的增益。下表展示了实验结果,可以看到在不使用外部语言模型的条件下,新提出的系统达到了比其它使用外部模型的最新端到端系统显著低的字错误率。
论文《词为建模单元的端到端语音识别系统多阶段训练方法(A Multistage Training Framework For Acoustic-to-Word Model)》研究了如何利用更好的模型训练方法在只有 300 小时的 Switchboard 数据集上也能得到具有竞争力的语音识别性能。最终,研究者将 Hierarchical-CTC、Curriculum Training、Joint CTC-CE 这三种模型训练方法结合到了一起,在无需使用任何语言模型和解码器的情况下取得了优良的表现。
另外,在今年 4 月举办的 IEEE ICASSP 2018 上,腾讯 AI Lab 有 3 篇自动语音识别方面的论文和 1 篇语音合成方面的论文(随后将介绍)入选。
在语音合成方面,其中 2 篇都是在用于多说话人的置换不变训练方面的研究。
其中论文《用于单声道多说话人语音识别的使用辅助信息的自适应置换不变训练(Adaptive Permutation Invariant Training With Auxiliary Information For Monaural Multi-talker Speech Recognition)》基于腾讯 AI Lab 之前在置换不变训练(PIT)方面的研究提出使用音高(pitch)和 i-vector 等辅助特征来适应 PIT 模型,以及使用联合优化语音识别和说话人对预测的多任务学习来利用性别信息。研究结果表明 PIT 技术能与其它先进技术结合起来提升多说话人语音识别的性能。
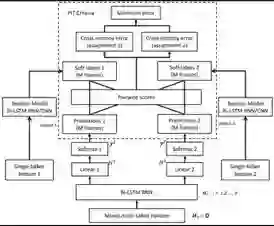
论文《用于单通道多说话人语音识别的置换不变训练中知识迁移(Knowledge Transfer In Permutation Invariant Training For Single-channel Multi-talker Speech Recognition)》则将 teacher-student 训练和置换不变训练结合到了一起,可将单说话人模型中提取出的知识用于改进 PIT 框架中的多说话人模型。实验结果也证明了这种方法的优越性。下图展示了这种加上了知识提取架构的置换不变训练架构。
另外一篇语音识别方面的 ICASSP 2018 论文《使用基于字母的特征和重要度采样的神经网络语言建模(Neural Network Language Modeling With Letter-based Features And Importance Sampling)》则提出了一种 Kaldi 语音识别工具套件的扩展 Kaldi-RNNLM 以支持神经语言建模,可用于自动语音识别等相关任务。
在语音识别方面最后值得一提的是,腾讯 AI Lab 还在《Frontiers of Information Technology & Electronic Engineering》(FITEE)上发表了一篇关于「鸡尾酒会问题」的综述论文《鸡尾酒会问题的过去回顾、当前进展和未来难题(Past Review, Current Progress, And Challenges Ahead On The Cocktail Party Problem)》,对针对这一问题的技术思路和方法做了全面的总结。
4)自然语言处理/理解
在智能音箱的工作流程中,自然语言处理是一个至关重要的阶段,这涉及到对用户意图的理解和响应。腾讯 AI Lab 在自然语言的处理和理解方面已有很多突破性的研究进展,融合腾讯公司多样化的应用场景和生态,能为腾讯的语音应用和听听音箱用户带来良好的用户体验和实用价值。
在将于当地时间 7 月 15-20 日在澳大利亚墨尔本举办的 ACL 2018 会议上,腾讯 AI Lab 有 5 篇与语言处理相关的论文入选,涉及到神经机器翻译、情感分类和自动评论等研究方向。腾讯 AI Lab 之前推送的文章《ACL 2018 | 解读腾讯 AI Lab 五篇入选论文》已对这些研究成果进行了介绍。另外在 IJCAI 2018(共 11 篇,其中语言处理方向 4 篇)和 NAACL 2018(4 篇)等国际顶级会议上也能看到腾讯 AI Lab 在语言处理方面的研究成果。
5)语音合成
对智能音箱而言,语音答复是用户对音箱能力的最直观感知。最好的合成语音必定要清晰、流畅、准确、自然,个性化的音色还能提供进一步的加成。
腾讯在语音合成方面有深厚的技术积累,开发了可实现端到端合成和重音语调合成的新技术,并且在不同风格的语音合成上也取得了亮眼的新进展。下面展示了一些不同风格的合成语音:

在 Interspeech 2018 上,腾讯 AI Lab 的论文《面向表现力语音合成采用残差嵌入向量的快速风格自适应(Rapid Style Adaptation Using Residual Error Embedding for Expressive Speech Synthesis)》探索了利用残差作为条件属性来合成具有适当的韵律变化的表现力语音的方法。该方法有两大优势:1)能自动学习获得风格嵌入向量,不需要人工标注信息,从而能克服数据的不足和可靠性低的问题;2)对于训练集中没有出现的参考语音,风格嵌入向量可以快速生成,从而使得模型仅用一个语音片段就可以快速自适应到目标的风格上。下图展示了该论文提出的残差编码网络的架构(左图)以及其中残差编码器的结构(右图)。
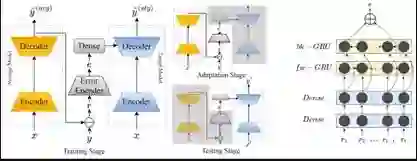
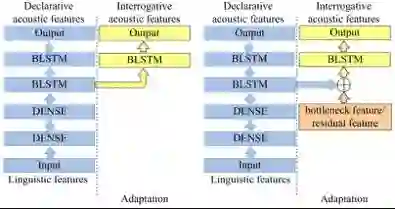
腾讯 AI Lab 在 ICASSP 2018 上也有一篇关于风格适应的论文《基于特征的说话风格合成适应(Feature Based Adaptation For Speaking Style Synthesis)》。这项研究对传统的基于模型的风格适应(如下左图)进行了改进,提出了基于特征的说话风格适应(如下右图)。实验结果证明了这种方法的有效性,并且表明这种方法能在保证合成语音质量的同时提升其疑问语气风格的表现力。
总结
智能语音被广泛认为是「下一代人机交互入口」,同时也能和腾讯公司广泛的应用生态相结合,为用户提供更加方便快捷的服务。腾讯 AI Lab 的技术已能为更多产品提供更高效更智能的解决方案。
腾讯 AI Lab 在语音方面的主攻方向包括结合说话人个性化信息语音识别、前后端联合优化、结合语音分离技术、语音语义的联合识别。
腾讯 AI Lab 未来还将继续探索语音方面的前沿技术,创造能与人类更自然交流的语音应用。也许未来的「腾讯听听音箱」也能以轻松的语调回答这个问题:
「9420,生命、宇宙以及一切的答案是什么?」
注:9420 是「腾讯听听音箱」的唤醒词,而在《银河系漫游指南》中上面这个终极问题的答案是 42,而 9420 的谐音也刚好为「就是爱你」(42=是爱),看起来是个很合适的答案。






