端对端的深度卷积神经网络在语音识别中的应用
端对端的深度卷积神经网络在语音识别中的应用
本文参考文献
Very Deep Convolutional Networks for End-to-End Speech Recognition
今天给大家介绍的是由MIT、CMU、Google Brain共同提出的深度卷积神经网络用于端对端的语音识别,这篇文章中提到了很多模型和技巧,个人觉得是一个非常综合性的模型,而且实验结果表明这个模型可以在WSJ任务上实现10.5%的单词错误率,不需要任何的语言模型,这是个人非常欣赏的地方。
一方面,近期的序列到序列(seq2seq)模型不仅在自然语言处理领域取得了新的成就,也同时为语音识别指明了另一个新的方向。不同于传统的语音识别系统,需要使用HMM或CTC来训练序列的整体概率,seq2seq仅仅凭借一个神经网络就可以实现完全端对端的训练语音识别系统,不需要任何额外的语言模型,这就是seq2seq的优势所在。
另外一方面,CNN相比于传统的循环神经网络(RNN)具有计算量小、容易刻画局部特征的优势,CNN的共享权重以及池化(pooling)层可以赋予模型更好的时域或频域的不变性,另外更深层的非线性结构也可以让CNN具备强大的表征能力,基于以上这些优势,CNN在语音识别上的应用日渐增多,因为现在我们不仅关心语音识别的准确率,更关心的是模型的训练速度。
seq2seq模型在语音识别上的应用其实之前也已经出现了,最典型的工作就是Listen, Attend and Spell论文,它是一个基于注意力机制的seq2seq模型,这也很容易理解,整个模型分为三部分:其中编码器承担Listen的角色,注意力机制承担Attend的角色,解码器承担Spell的角色。负责Listen的编码器是由多层双向长短期记忆网络(BLSTM)构成,而在今天这篇论文中,作者将BLSTM换成了深度卷积神经网络(Deep CNN)和BLSTM,而在解码器仍然是由LSTM构成。
在模型细节上,本文主要有以下几个特色:
使用了Network in Network(NiN)的模型来使得deep CNN以更少的参数拥有更强大的表征能力;
使用了Batch Normalization来加速模型的训练;
使用了Residual connection来克服因模型深度而带来的陷入局部最优的问题;
使用了Convolutional LSTM来减少LSTM的参数,将原有LSTM内部的乘法改成了卷积,得到更强的泛化能力;
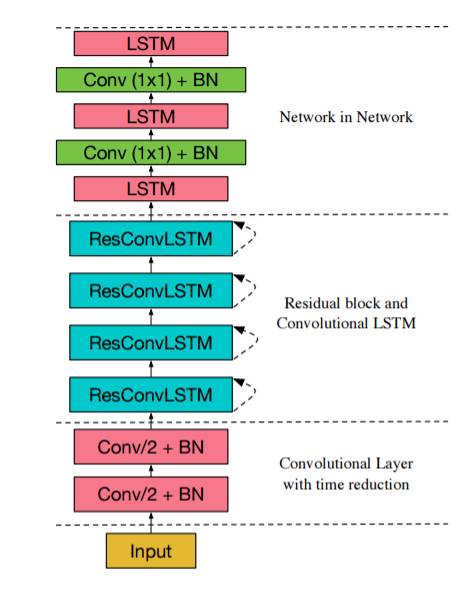
文章的最优实验模型结构如下图所示,底部由两个卷积网络构成,使得特征在时间维度上进行降维,同时卷积层带有批归一化操作,因为批归一化操作可以提高训练速度加速模型收敛,紧接着是四个residual block,每个residual block由一个conv lstm和conv构成,最后是LSTM NiN模块。这样一个模型应用在seq2seq的编码器上,在WSJ任务上得到了最好的效果。
题图:Anil Saxena
你可能会感兴趣的文章有:
详述DeepMind wavenet原理及其TensorFlow实现
Layer Normalization原理及其TensorFlow实现
Batch Normalization原理及其TensorFlow实现
Maxout Network原理及其TensorFlow实现
Network-in-Network原理及其TensorFlow实现
如何基于TensorFlow实现ResNet和HighwayNet
深度残差学习框架(Deep Residual Learning)
推荐阅读 | 如何让TensorFlow模型运行提速36.8%
推荐阅读 | 如何让TensorFlow模型运行提速36.8%(续)
深度学习每日摘要|坚持技术,追求原创




