CVPR 2019 | 微软亚研院提出用于语义分割的结构化知识蒸馏
本文由我爱计算机视觉授权转载

今天跟大家分享一篇关于语义分割的论文,刚刚上传到arXiv的CVPR 2019接收论文《Structured Knowledge Distillation for Semantic Segmentation》,通讯作者单位为微软亚洲研究院。
作者信息:

作者分别来自澳大利亚阿德莱德大学、微软亚洲研究院、北航、Keep公司、三星中国研究院,该文为第一作者Yifan Liu在微软亚洲研究院实习期间的工作。
该文研究了在语义分割模型的知识蒸馏中引入结构化信息的损失函数,在不改变模型计算量的情况下,使用该方法在Cityscapes数据集上mIoU精度取得了最高达15.17%的提升。
什么是知识蒸馏?
顾名思义,知识蒸馏是把知识浓缩到“小”网络模型中。一般情况下,在相同的数据上训练,模型参数量较大、计算量大的模型往往精度比较高,而用精度高、模型复杂度高的模型即Teacher网络的输出训练Student网络,以期达到使计算量小参数少的小网络精度提升的方法,就是知识蒸馏。
知识蒸馏的好处是显而易见的,使用知识蒸馏后的Student网络能够达到较高的精度,而且更有利于实际应用部署,尤其是在移动设备中。
下面两幅图中,作者展示了使用该文提出的结构化知识蒸馏的语义分割模型在计算量和参数量不变的情况下,精度获得了大幅提升。
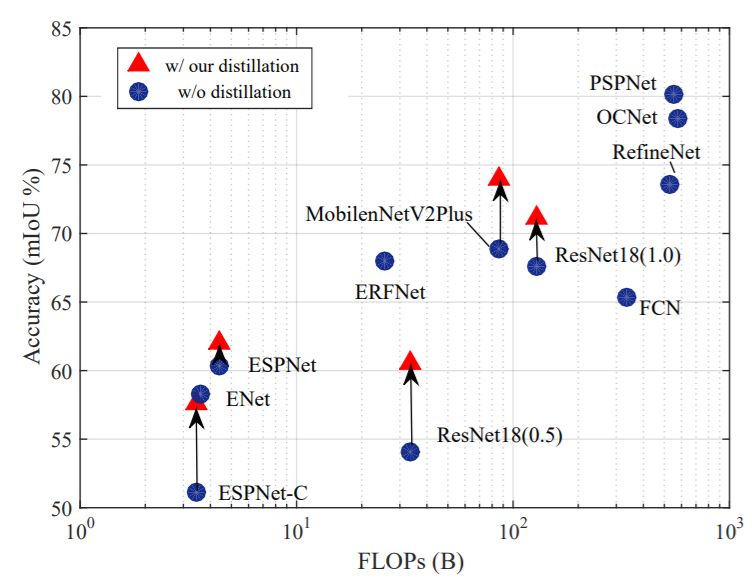
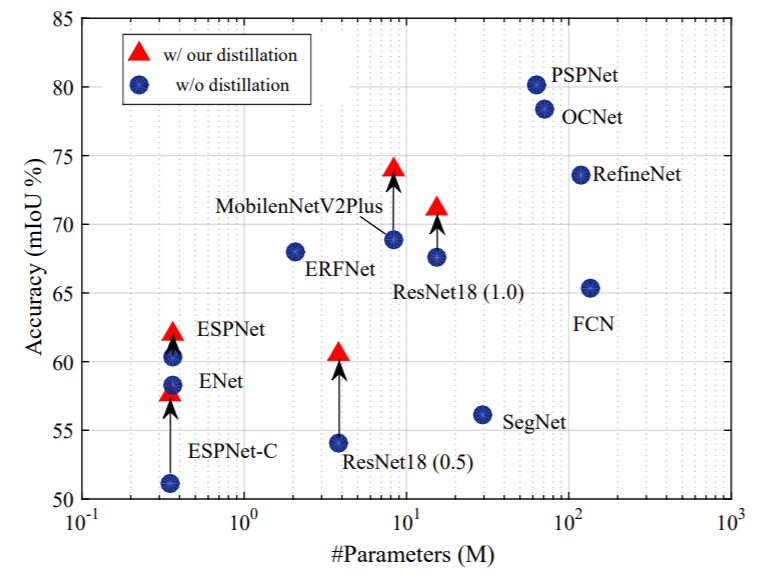
算法原理
知识蒸馏的目标是希望对于Teacher网络和Student网络给定相同的图像,输出结果尽量一样。
所以,知识蒸馏的关键,是如何衡量Teacher网络和Student网络输出结果的一致性,也就是训练过程中的损失函数设计。
该文中作者将语义分割问题看为像素分类问题,所以很自然的可以使用衡量分类差异的逐像素(Pixel-wise)的损失函数Cross entropy loss,这是在最终的输出结果Score map中计算的。
同时作者引入了图像的结构化信息损失,如下图所示。
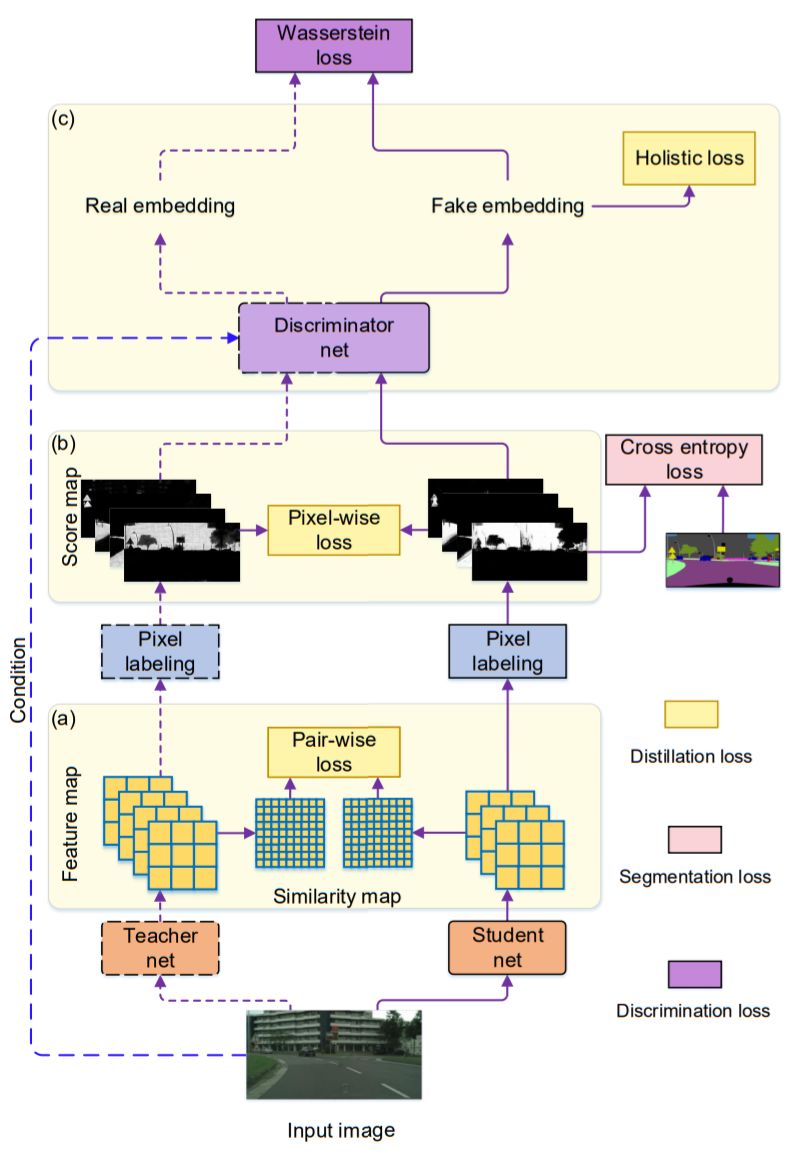
如何理解图像的结构化信息?一种很显然的结构化信息即图像中局部的一致性。在语义分割中,可以简单理解为,预测结果中存在的自相似性,作者衡量这种结构化信息的方式是Teacher预测的两像素结果和Student网络预测的两像素结果一致。衡量这种损失,作者称之为Pair-wise loss(也许可以翻译为“逐成对像素”损失)。
另一种更高层次的结构化信息是来自对图像整体结构相似性的度量,作者引入了对抗网络的思想,设计专门的网络分支分类Teacher网络和Student网络预测的结果,网络收敛的结果是该网络不能再区分Teacher网络和Student网络的输出。作者称这块损失函数为Holistic loss(整体损失)。
仔细想想,作者设计的损失函数的三部分,逐像素的损失(Pixel-wise loss,PI)、逐像素对的损失(Pair-wise loss,PA)、整体损失(Holistic loss,HO)都很有道理,是不是?
作者使用ResNet18网络模型在Cityscapes数据集上研究了作者提出的损失函数各部分对结果的影响。(ImN代表用ImageNet预训练模型初始化网络)
结果如下图。
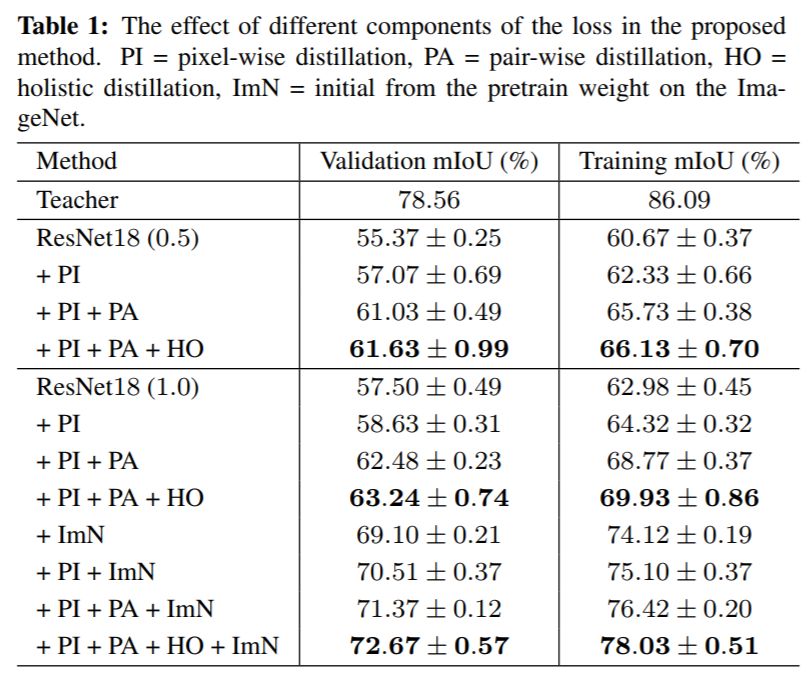
可知,作者提出的损失函数的各个部分都能使得Student网络获得精度增益,最高达15.17%!CV君发现逐像素对的损失(Pair-wise loss,PA)获得的增益最大。
实验结果
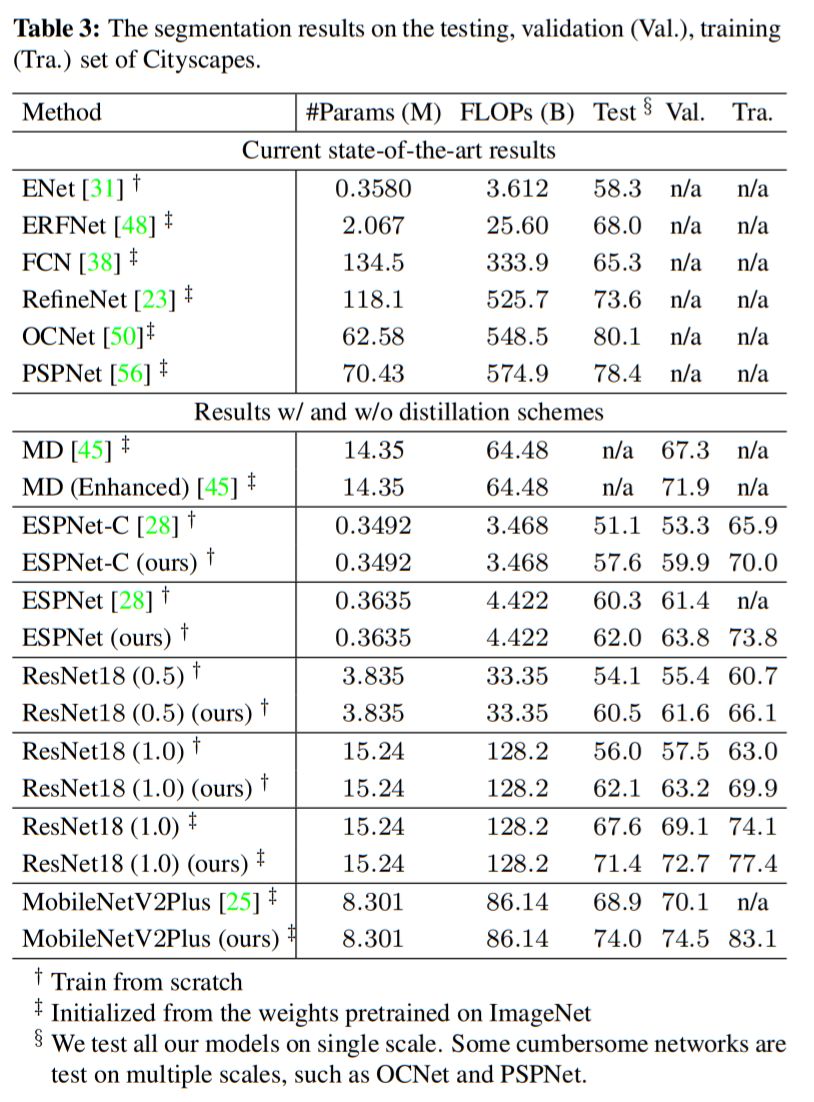
作者使用多个轻量级网络模型,在三个主流语义分割数据库上进行了实验。
下图为在Cityscapes数据集上的结果,使用该文方法知识蒸馏后Student网络精度获得了大幅提升!
下图为一些预测结果示例,视觉效果上改进明显。

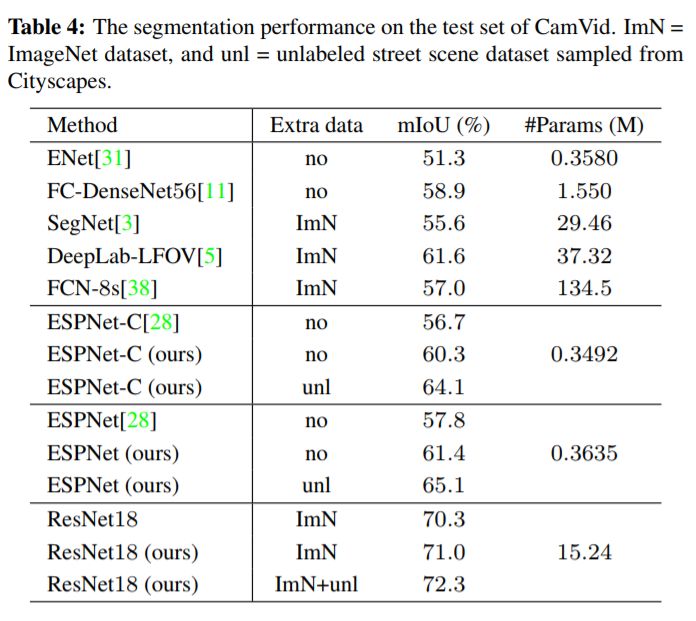
下图为在CamVid数据集上的结果,同样改进明显。
CamVid数据集上的Student网络预测示例,视觉上也好了很多。

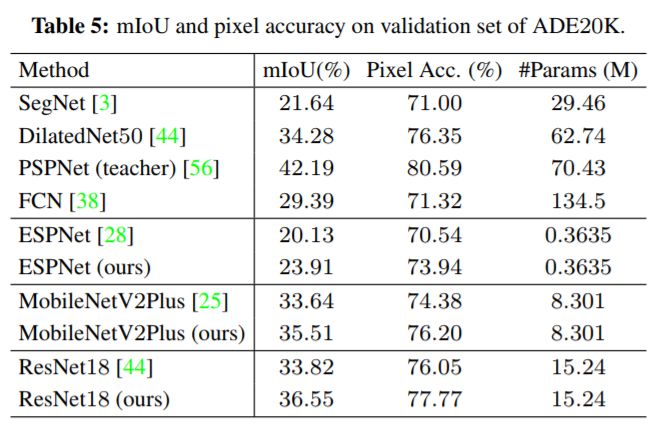
下图为在ADE20K数据集上的实验结果,同样所有网络模型的精度都获得了大幅提升!
目前还未发现该文作者公布代码。
论文地址:
https://arxiv.org/pdf/1903.04197.pdf
值得一提的是,该文很显然不仅对语义分割网络的知识蒸馏有借鉴意义,做深度估计、光流计算等像素级预测任务都值得参考。
推荐阅读

觉得有用,给个好看啦~



