FAIR&MIT提出知识蒸馏新方法:数据集蒸馏
选自arxiv
作者:Tongzhou Wang等
机器之心编译
参与:路、王淑婷
近日,来自 FAIR、MIT 和加州大学伯克利分校的 Tongzhou Wang、朱俊彦等人发布新研究论文,提出一种新的蒸馏方法——数据集蒸馏。这与将知识从复杂网络迁移到较简单模型不同,该方法将原始数据集中大量数据集的知识压缩到少量合成数据上,同时在合成数据上训练的模型性能与在原始数据集上的模型性能相差无几。
Geoffrey Hinton 在论文《Distilling the Knowledge in a Neural Network》中提出模型蒸馏,即将知识从多个独立训练的网络的集成迁移到单个紧凑网络,从而执行模型压缩。近日,FAIR、MIT、加州大学伯克利分校的研究者发布一篇论文,考虑使用一种相关又无关的任务:不蒸馏模型,而是蒸馏数据集。与模型蒸馏不同,该方法保持模型不变,而是将整个训练数据集的知识(通常包含数千或数百万图像)压缩成少量合成训练图像。实验结果表明可以使每张合成图像表示一个类别,且能使同一个模型在合成图像上达到惊人的优秀性能。如下图 a 所示,在给定固定网络初始化的前提下,将六万个 MNIST 训练图像压缩成 10 张合成图像(每张图像代表一个类别)。在这 10 张图像上训练标准 LENET (LeCun et al., 1998) 架构可在测试阶段达到 94% 的识别准确率,该模型在原始任务中的性能是 99%。对于具备未知随机权重的网络,100 张合成图像仅需几个梯度下降步就能训练达到 80% 的性能。研究者将该方法叫作「数据集蒸馏」,这些图像叫作蒸馏图像。
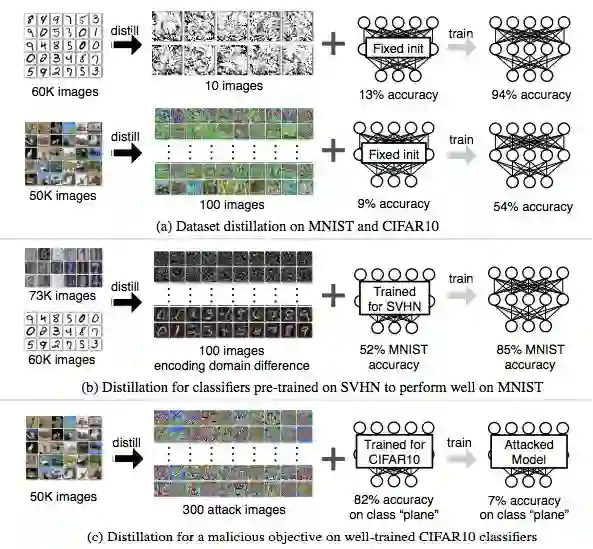
图 1:数据集蒸馏:将数万张图像的知识压缩到几张合成训练图像中,后者即蒸馏图像。(a)在 MNIST 数据集上,10 张蒸馏图像可以将特定固定初始化设置的标准 LENET 的性能训练达到 94% 的测试准确率(在完整训练数据集上训练出的模型性能是 99%)。在 CIFAR10 数据集上,100 张蒸馏图像可以将固定初始化的深度网络的性能训练达到 54% 的测试准确率(在完整训练数据集上训练出的模型性能是 80%)。(b)使用在街道门牌号数字识别数据集 SVHN 上预训练的网络,可以将 SVHN 和 MNIST 两个数据集之间的域区别蒸馏成 100 张蒸馏图像。这些图像可用于快速精调在 SVHN 上训练的网络,使之在 MNIST 数据集上获得较高准确率。(c)出于恶意目标而训练时,该蒸馏方法可用于创建对抗攻击图像。如果经过良好优化的网络使用这些图像经一个梯度步即可完成重新训练,那么这些网络将误分类特定目标类别。
那数据集蒸馏为何有用呢?这就关系到给定训练数据集中有多少数据是被真正编码了,以及训练集的可压缩性如何。此外,给出少量蒸馏图像,我们可以更加高效地为给定网络「加载」整个数据集的知识,而传统的训练通常需要数万个梯度下降步。
这里有一个关键问题,即将数据集压缩成少量合成数据样本是否可能。例如,在合成图像(而非自然的图像流形)上训练图像分类模型是否可能。传统的观念认为不可以,因为合成训练数据可能与真正测试数据的分布不同。但是,本文证明这是可能的。研究者展示了一种用于合成少量合成数据样本的新优化算法,这些样本不仅能捕获大量原始训练数据,而且在几个梯度步内就可以适应快速的模型训练。为了达到该目标,研究者首先将网络权重作为合成训练数据的可微函数。因此,无需为特定训练目标函数进行权重优化,而是对蒸馏图像优化像素值。但是,这需要获取网络的初始权重。为了松弛该假设,研究者提出一种方法,可为随机初始化网络生成蒸馏图像。为了进一步提升性能,研究者还提出了一种迭代版本,即获取多张蒸馏图像来训练一个模型,而每张蒸馏图像可使用多次传输来训练。最后,研究者研究了简单的线性模型,提出了达到在完整数据集上训练模型的相同性能所需蒸馏数据的最低规模。
论文:DATASET DISTILLATION

论文链接:https://arxiv.org/pdf/1811.10959.pdf
摘要:模型蒸馏(model distillation),即将复杂模型的知识迁移到更简单的模型中。本文提出了另一种方法:数据集蒸馏(dataset distillation):保持模型不变,尝试将大型训练数据集的知识压缩成小型数据集。这个想法是合成无需来自正确数据分布的少量数据点,这些数据点在作为学习算法的训练数据时,训练出的模型逼近在原始数据上训练的模型。例如,实验证明六万个 MNIST 训练图像可以压缩成 10 个合成蒸馏图像(每一个图像的类别不同),给定固定的网络初始化,网络仅需几步梯度下降步即可逼近原始性能。研究者在大量不同初始化设置和不同学习目标中评估了该方法。在多个数据集上的实验证明该方法在大多数设置中可媲美其它方法。
方法

实验

表 1:经过 10 个梯度下降步和 3 个 epoch 后,本研究提出的方法与其它基线的对比结果。
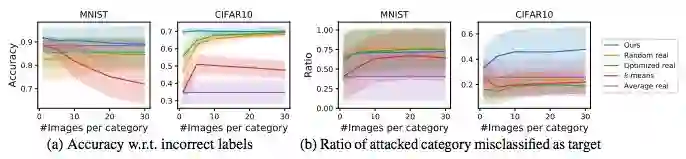
图 6:在随机预训练初始化和恶意目标的情况下,本研究提出的方法和基线的性能对比。

表 2:本研究提出的方法和基线在 MNIST (M)、USPS (U) 和 SVHN (S) 数据集上训练模型的性能。

表 3:本研究提出的方法与基线在 ImageNet 数据集上预训练得到的 ALEXNET 模型在 PASCAL-VOC 和 CUB-200 数据集上的性能。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


