解决批标准化中 sample 问题:Filter Response Normalization
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:董鑫,哈佛大学·人工智能博士在读
文章链接: https://zhuanlan.zhihu.com/p/94947457 作者主页:https://www.zhihu.com/people/simonxdong/activities 本文已由作者授权转载,未经允许,不得二次转载。
Note: Filter Response Normalization from Google
这是一篇来自 Google AI 的一篇文章,提出了一种解决 batch normalization 中的 sample 问题的新方法。
Previous Work
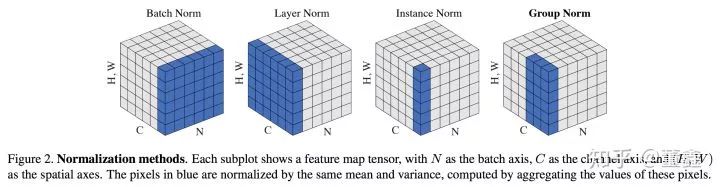
关于不同的 normalization 的方法,看这张图基本上就够了。
Notation
Method
Filter Response Normalization (FRN)
都是在 channel level 做 normalization 的,但是 FRN 没有在 batch 这个维度上求 variance (其实相当于 batch size=1)。自然不会受制于 batch size
FRN 里面,没有减去 mean。
Thresholded Linear Unit (TLU)
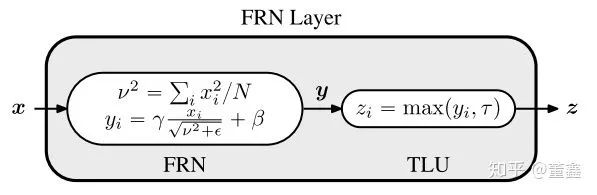
However, this does not appear to be identical to absorbing the biases in the previous and subsequent layers based on our experiments. We hypothesize that the form of TLU is more favorable for optimization. TLU significantly improves the performance of models using FRN (see Table 5), outperforming BN and other alternatives, and leads to our method, FRN layer.
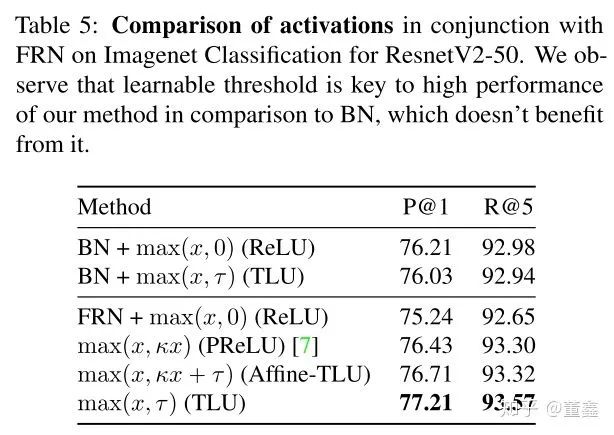
TLU 不会让 正常 BN 变差 (只差了 0.2,不同说明太多问题,所以认为没有变差),但是能让 FRN 大幅度变好;
其实只要对 ReLU 做一些参数化的改动都能让 TLU 变好,但是还是 TLU 最好用。
-End-
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~

登录查看更多
相关内容

专知会员服务
54+阅读 · 2020年3月5日
专知会员服务
14+阅读 · 2020年1月1日
Arxiv
5+阅读 · 2018年10月18日
Arxiv
5+阅读 · 2018年4月5日


相关VIP内容
专知会员服务
54+阅读 · 2020年3月5日
专知会员服务
14+阅读 · 2020年1月1日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年10月18日
Arxiv
5+阅读 · 2018年4月5日